Download as PDF, PPTX














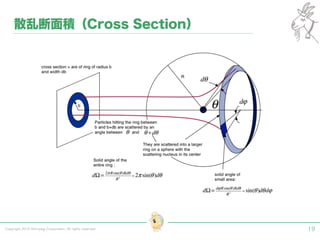
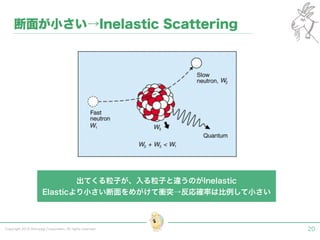
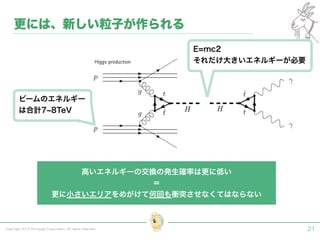
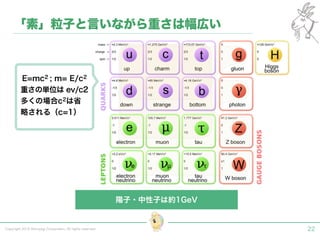
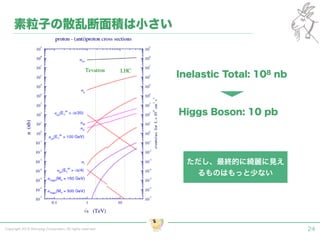





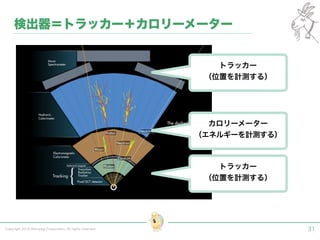
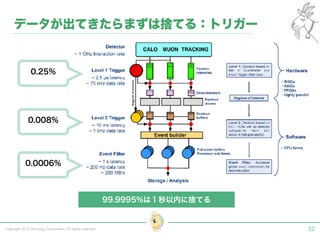
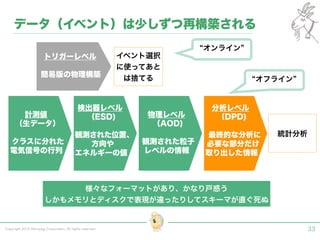
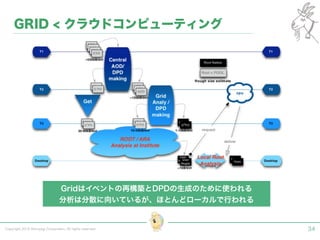



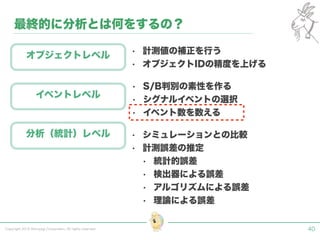


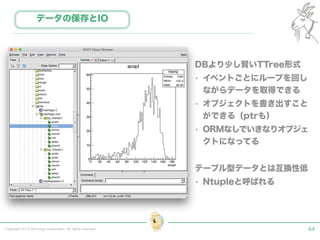
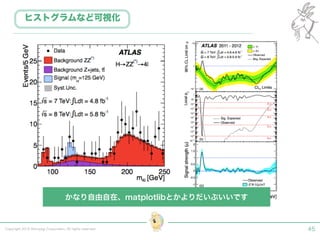
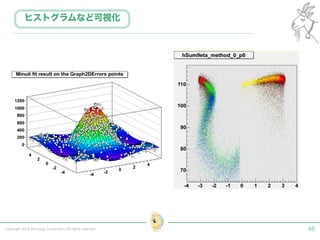



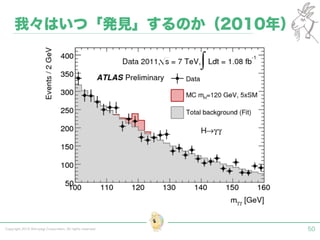
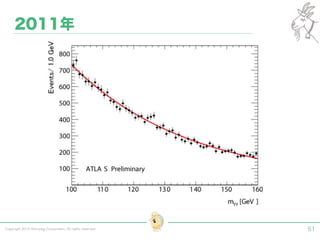
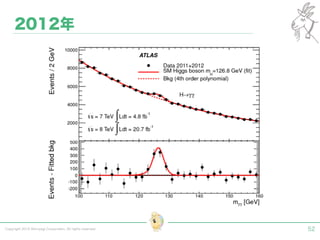


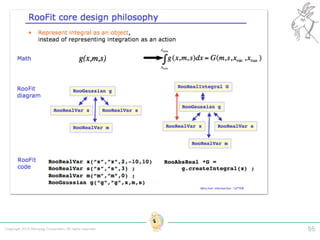
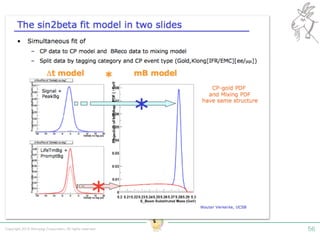
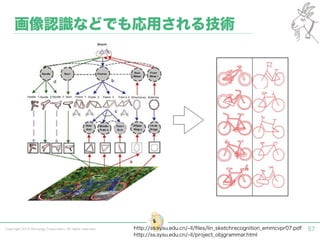
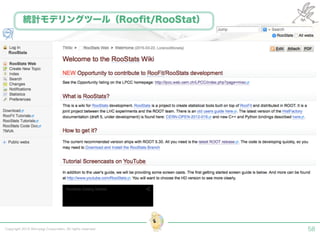
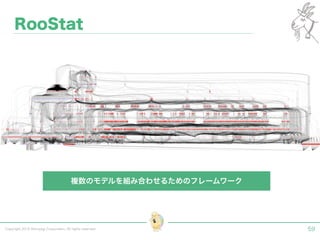


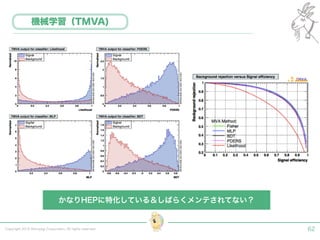





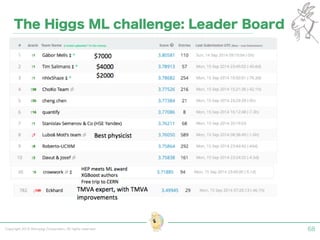








Tokyo Web Mining #45でお話させていただいた内容です。 アブストラクト: 実験素粒子物理学においては、加速器を使った高エネルギー素粒子の衝突実験から生まれる大量のデータを分析するため、かつてよりあらゆる科学分野の中でも最もデータ量の多い領域でした。スイスのCERN研究所で行われている最新の実験、LHC(Large Hadron Collider)では、最初の2年間で、1PB(ペタバイト)のデータが生成され、その一部は昨年オープン化されました。本講演では、LHCのビッグデータがどのように解析されたのか、インフラ及びアプリケーションレベルの観点ご紹介します。特に、アプリケーションレベルにおいては、独自の統計解析ライブラリであるROOTが幅広く使われており、この講演を通じ、ROOTが現在のデータ解析パラダイムのどこに位置しているのかを参加者の皆様と議論したいと思います。


























































![[DL輪読会]Learning to Simulate Complex Physics with Graph Networks](https://cdn.slidesharecdn.com/ss_thumbnails/learningtosimulatecomplexphysicswithgraphnetworks-200508054213-thumbnail.jpg?width=640&height=640&fit=bounds)
























