Download as PDF, PPTX




![[Mildenhall et al., ECCV2020]
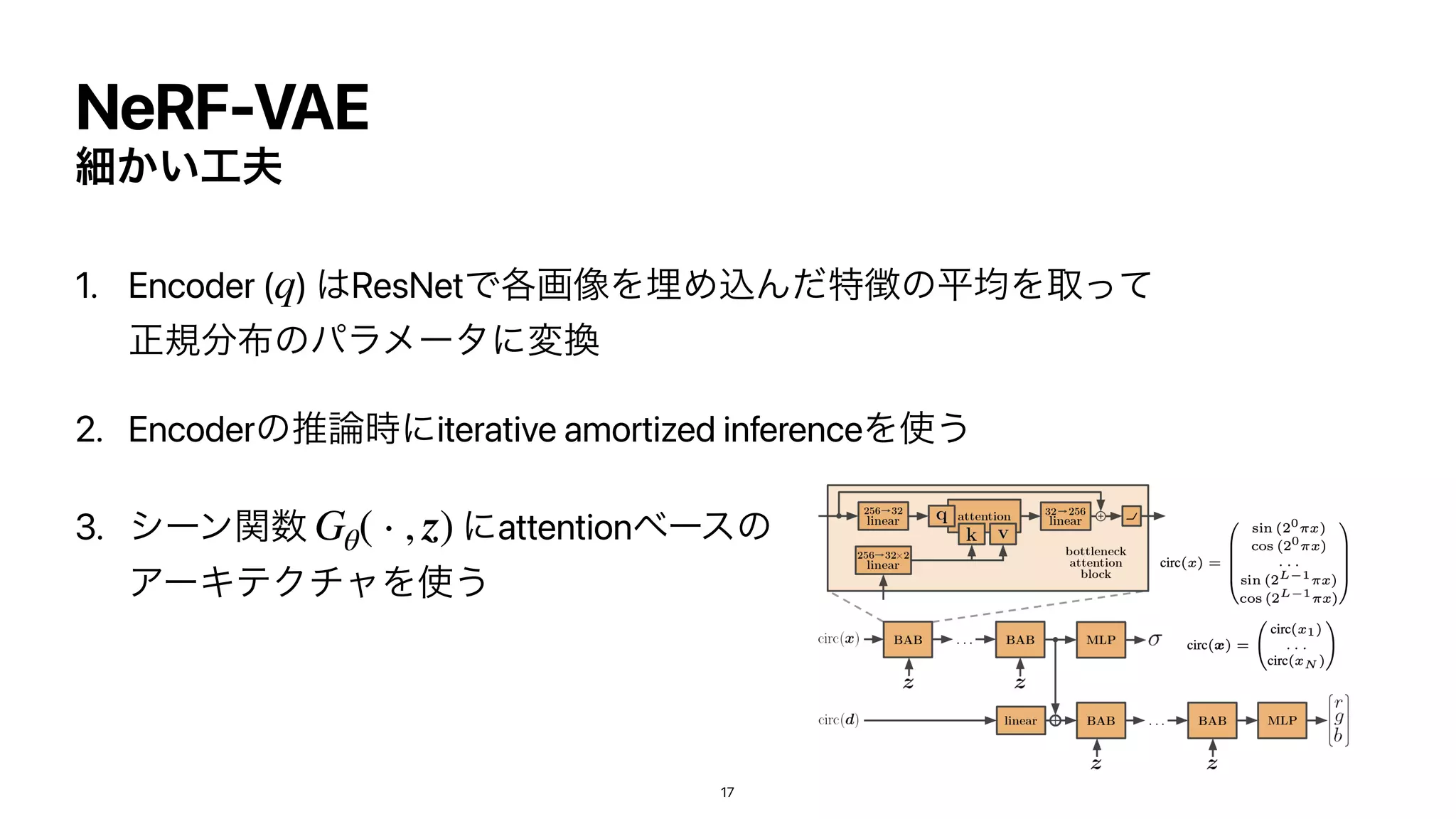
• 3࣍࠲ݩඪ ( ) ͱࢹઢํ ( ) Λ
ೖྗͱًͯ͠ ( ) ͱີ Λ
ग़ྗ͢ΔNN (γʔϯؔ
)
• ༷ʑͳ͔֯ΒࡱͬͨࣸਅͰֶश
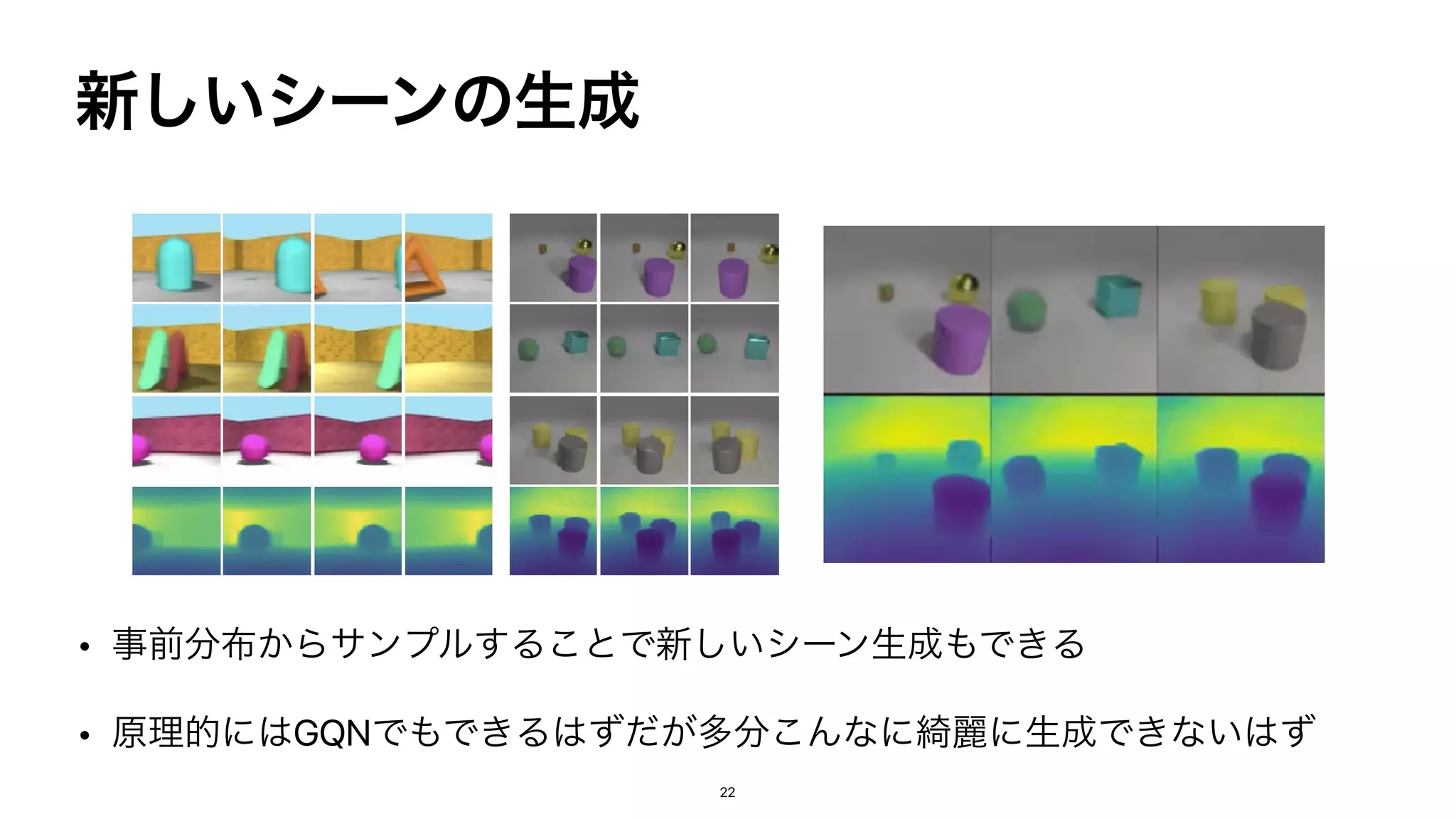
➡︎
ผͷ͔֯ΒࡱͬͨࣸਅΛ
ɹੜͰ͖Δ(novel view synthesis)
x d
r, g, b σ
Fθ : (x, d) ↦ ((r, g, b), σ)
NeRF
5](https://image.slidesharecdn.com/dlseminar20210416-210419040232/75/DL-NeRF-VAE-A-Geometry-Aware-3D-Scene-Generative-Model-5-2048.jpg)
![NeRF
[Mildenhall et al., ECCV2020]
• γʔϯΛ3࣍࠲ݩඪͱࢹઢํ͔Βًͱີ ͷؔͱͯ͠දݱ
• ͜ͷ͕ؔΘ͔Δͱɺvolume renderingΛ༻͍ͯҙͷࢹ͔Βͷը૾Λ
ੜՄೳʢৄ͘͠͞ډΜͷࢿྉ[1, 2]Λࢀরʣ
6](https://image.slidesharecdn.com/dlseminar20210416-210419040232/75/DL-NeRF-VAE-A-Geometry-Aware-3D-Scene-Generative-Model-6-2048.jpg)
![[Mildenhall et al., ECCV2020]
• ֶशϨϯμϦϯάͨ͠ը૾ͱ
ਅͷը૾ͱͷ̎ࠩޡͷ࠷খԽ
• volume rendering͕ඍՄೳͳͷͰ
end-to-endʹֶशՄೳ
• ϨϯμϦϯά࣌ʹ͏αϯϓϧͷ
બͼํͳͲʹ༷ʑͳ͋Γ
NeRF
7](https://image.slidesharecdn.com/dlseminar20210416-210419040232/75/DL-NeRF-VAE-A-Geometry-Aware-3D-Scene-Generative-Model-7-2048.jpg)
![[Mildenhall et al., ECCV2020]
Pros
• 3Dγʔϯͷදͯ͠ͱݱըظత
• ैདྷ܈ϝογϡͷΑ͏ͳ
ࢄͰߴίετͳදݱ
• NNΛͬͨimplicitͳදͰݱ
ෳࡶͳγʔϯΛਫ਼៛ʹଊ͑ΒΕΔ
NeRF
8](https://image.slidesharecdn.com/dlseminar20210416-210419040232/75/DL-NeRF-VAE-A-Geometry-Aware-3D-Scene-Generative-Model-8-2048.jpg)
![NeRF
[Mildenhall et al., ECCV2020]
Cons
• γʔϯ͝ͱʹஞҰϞσϧΛ࠷దԽ͢Δඞཁ͕͋Δ
• ະͷγʔϯ͕ಘΒΕͨΒɺͦͷʹϞσϧΛֶश͠ͳ͚ΕͳΒͳ͍
• γʔϯ͝ͱʹͨ͘͞Μͷը૾Λ༻ҙ͢Δඞཁ͕͋Δ
• 1γʔϯ͋ͨΓֶशʹ1~2͔͔Δ
• ʢવ͕ͩʣ৽͍͠γʔϯͷੜͰ͖ͳ͍
9](https://image.slidesharecdn.com/dlseminar20210416-210419040232/75/DL-NeRF-VAE-A-Geometry-Aware-3D-Scene-Generative-Model-9-2048.jpg)
![[Eslami et al.,2018]
• 3࣍ݩγʔϯ෮ݩΛߦ͏VAE
• EncoderΛ༻͍ͯ৽͍͠γʔϯΛ
ߴʹ෮͖ͰݩΔ
• ϞσϧΈࠐΈϕʔε
• ৄ͘͠ླ͞Μͷࢿྉ[3]Λࢀর
GQN
10](https://image.slidesharecdn.com/dlseminar20210416-210419040232/75/DL-NeRF-VAE-A-Geometry-Aware-3D-Scene-Generative-Model-10-2048.jpg)
![GQN
[Eslami et al.,2018]
• ࢹ ͔Βͨݟը૾Λ ͱ͠ɺγʔϯΛજࡏม Ͱදݱ
• VAEͱಉ༷ʹมԼքͷ࠷େԽͰֶश
c I z
z
I
c
log p ({Ik}
N
k=1
∣ {ck}
N
k=1)
= log
∫
p (z)
N
∏
k=1
p (Ik ∣ ck, z) dz
≥
𝔼
q(z ∣ {Ik, ck}
N
k=1) [
N
∑
k=1
log p (Ik ∣ ck, z)
]
− DKL (q∥p)
11](https://image.slidesharecdn.com/dlseminar20210416-210419040232/75/DL-NeRF-VAE-A-Geometry-Aware-3D-Scene-Generative-Model-11-2048.jpg)
![[Eslami et al.,2018]
৽͍͠γʔϯͷ෮ݩencoder ( )Λ
ͬͯߴʹͰ͖Δ
q
p (I ∣ c, {Ik, ck}
M
k=1)
≈
𝔼
q(z ∣ {Ik, ck}
M
k=1)
[p (I ∣ c, z)]
GQN
12](https://image.slidesharecdn.com/dlseminar20210416-210419040232/75/DL-NeRF-VAE-A-Geometry-Aware-3D-Scene-Generative-Model-12-2048.jpg)
![GQN
[Eslami et al.,2018]
Pros
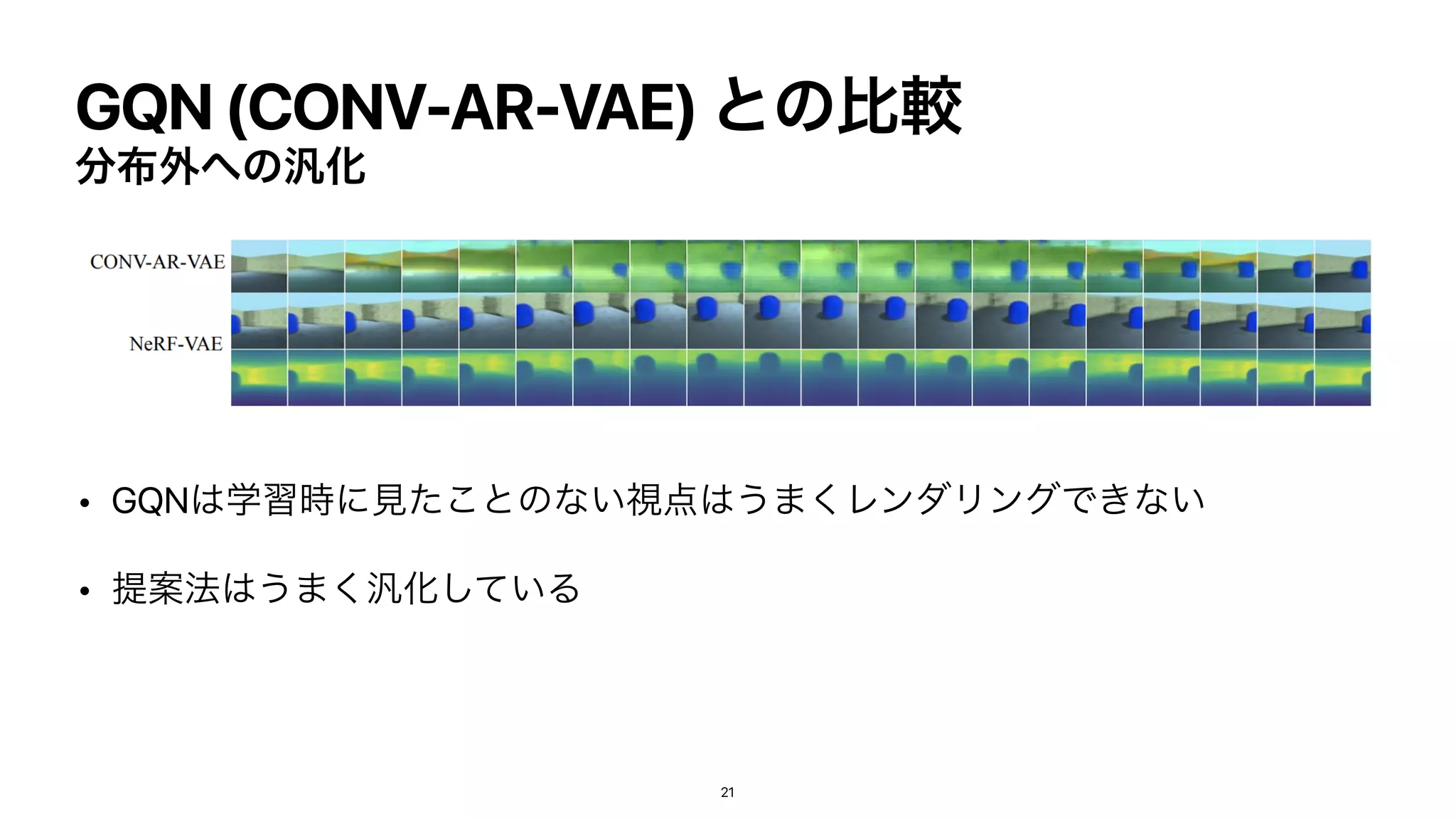
• EncoderͰະγʔϯΛߴʹ
෮͖ͰݩΔ (amortized inference)
• ֶश࣌ؒͦ͜·Ͱ͔͔Βͳ͍
Cons
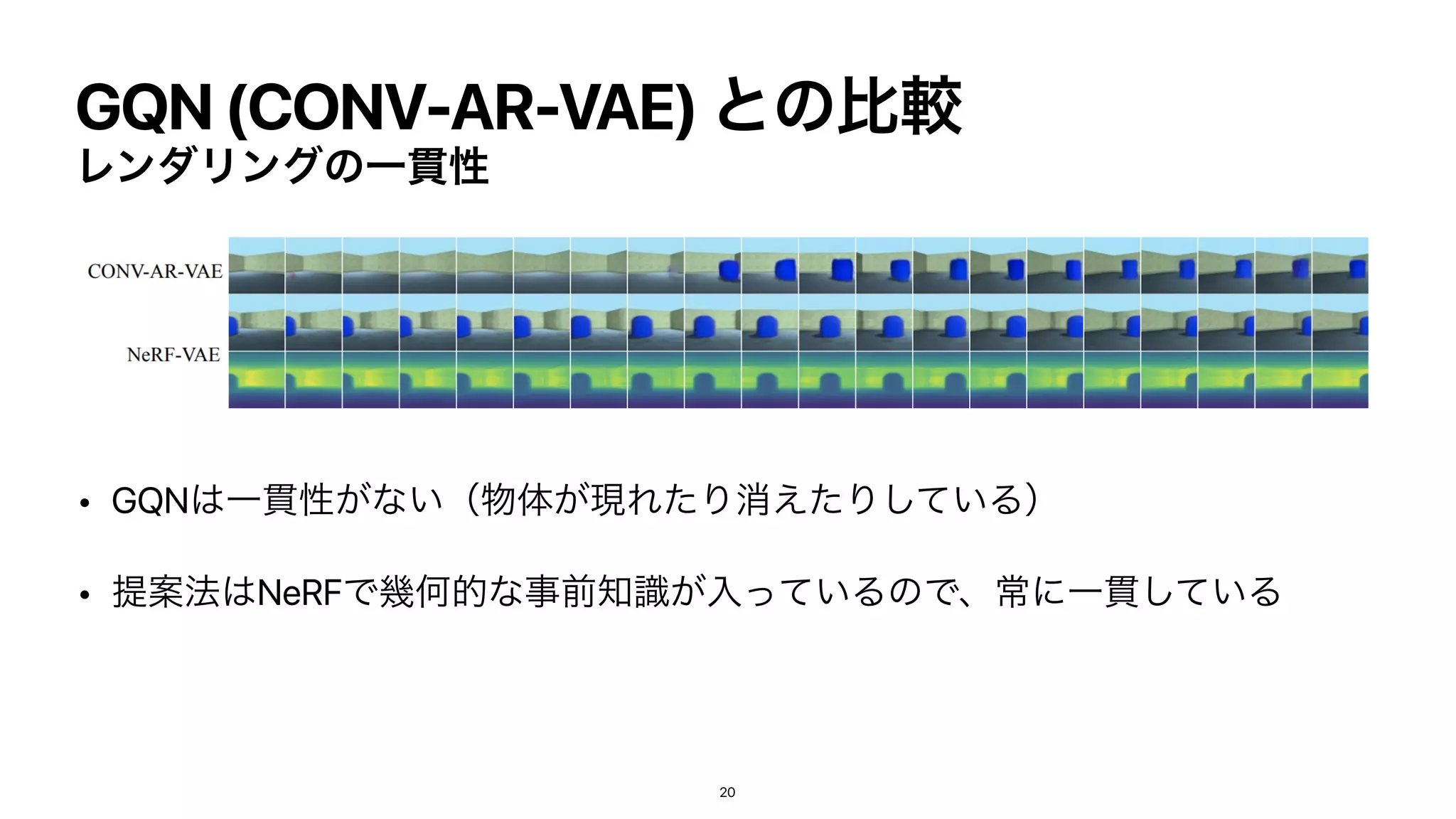
• زԿతͳใΛͬͯͳ͍ͷͰ
෮ݩը૾ʹҰ؏ੑ͕ͳ͍
• NeRF΄Ͳ៉ྷʹੜͰ͖ͳ͍
13](https://image.slidesharecdn.com/dlseminar20210416-210419040232/75/DL-NeRF-VAE-A-Geometry-Aware-3D-Scene-Generative-Model-13-2048.jpg)


![• ࢹ ͔ΒͷϨϯμϦϯά݁ՌΛ ͱ͢Δͱ
ؔ
• ֶशGQNͱಉ༷ʹมԼքͷ࠷େԽ
c ̂
I = render (Gθ( ⋅ , z), c)
pθ(I ∣ z, c) =
∏
i,j
𝒩
(I(i, j) ∣ ̂
I(i, j), σ2
lik)
𝔼
q(z ∣ {Ik, ck}
N
k=1) [
N
∑
k=1
log p (Ik ∣ ck, z)
]
− DKL (q∥p)
z
I
c
NeRF-VAE
࠷దԽ
16](https://image.slidesharecdn.com/dlseminar20210416-210419040232/75/DL-NeRF-VAE-A-Geometry-Aware-3D-Scene-Generative-Model-16-2048.jpg)


![References
[1] [DLྠಡձ]NeRF: Representing Scenes as Neural Radiance Fields for View
Synthesis (https://www.slideshare.net/DeepLearningJP2016/dlnerf-representing-
scenes-as-neural-radiance-fields-for-view-synthesis)
[2] [DLྠಡձ]Neural Radiance Field (NeRF) ͷੜͱ·ڀݚΊ (https://
www.slideshare.net/DeepLearningJP2016/dlneural-radiance-field-nerf?ref=https://
deeplearning.jp/)
[3] [DLྠಡձ]GQNͱؔ࿈ڀݚɼੈքϞσϧͱͷؔʹ͍ͭͯ (https://
www.slideshare.net/DeepLearningJP2016/dlgqn-111725780)
24](https://image.slidesharecdn.com/dlseminar20210416-210419040232/75/DL-NeRF-VAE-A-Geometry-Aware-3D-Scene-Generative-Model-24-2048.jpg)

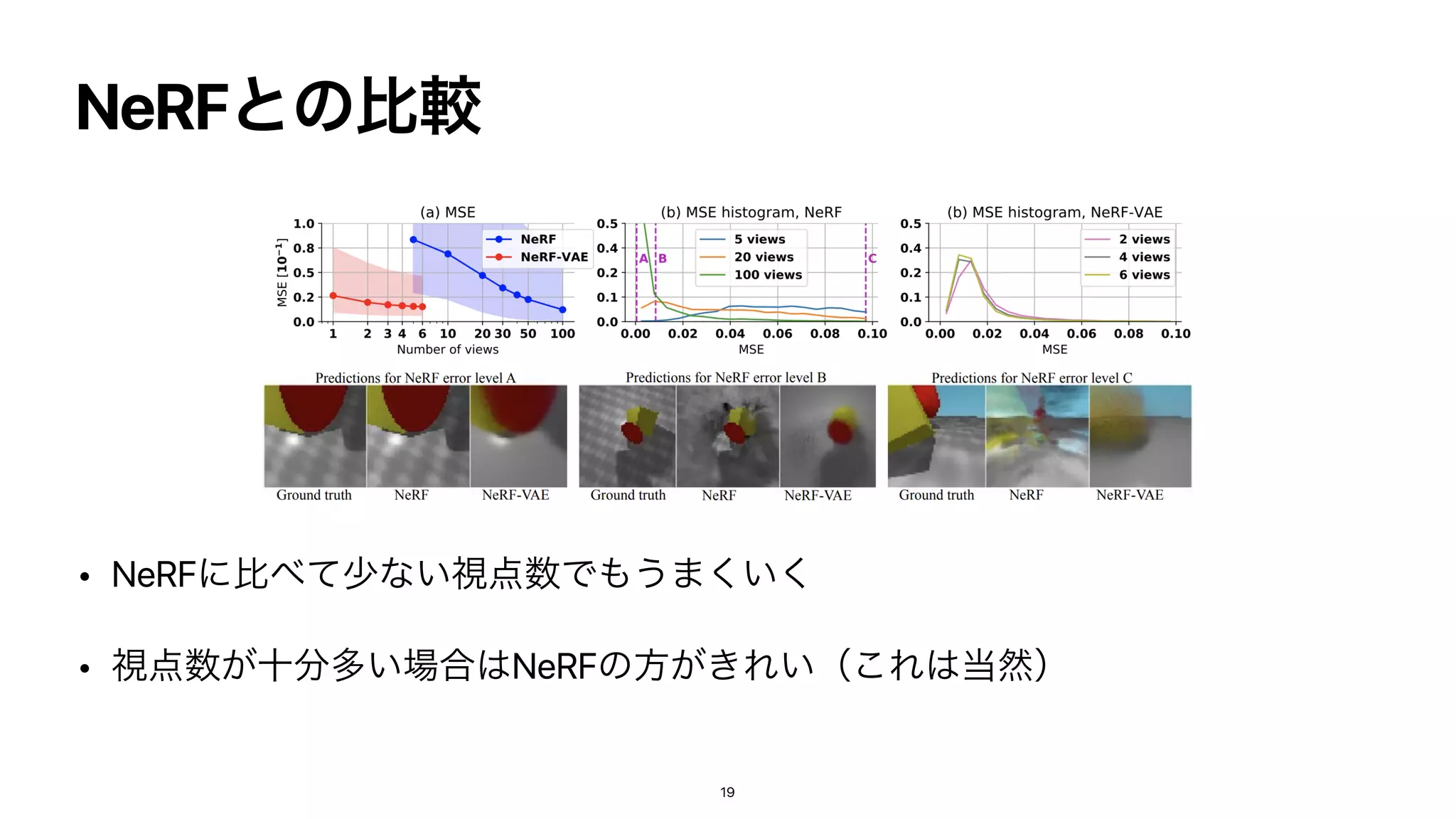
NeRF-VAE is a 3D scene generative model that combines Neural Radiance Fields (NeRF) and Generative Query Networks (GQN) with a variational autoencoder (VAE). It uses a NeRF decoder to generate novel views conditioned on a latent code. An encoder extracts latent codes from input views. During training, it maximizes the evidence lower bound to learn the latent space of scenes and allow for novel view synthesis. NeRF-VAE aims to generate photorealistic novel views of scenes by leveraging NeRF's view synthesis abilities within a generative model framework.

![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Paper] GIRAFFE: Representing Scenes as Compositional Generative Neural Featu...](https://cdn.slidesharecdn.com/ss_thumbnails/papergirafferepresentingscenesascompositionalgenerativeneuralfeaturefields-210823043723-thumbnail.jpg?width=640&height=640&fit=bounds)













































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)






