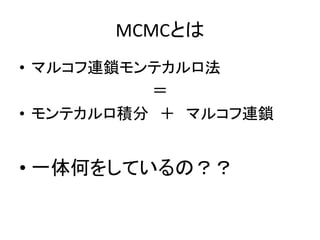
モンテカルロ積分
• ある積分Hに、確率変数xの確率分布p(x)をかませよう
• ここで、x1,x2, x3,…を確率分布p(x)から独立に抽出した標本と
すると、大数の法則より
• つまり、確率分布p(x)から独立して多くのサンプルが得られ
れば、直接積分を解かなくても、漸近解が得られる。
• これをモンテカルロ積分という。
( )
( ) ( ) ( ) ( ) [ ( )]
( )
( )
, ( )
( )
p
k x
H k x dx p x dx h x p x dx E h x
p x
k x
where h x
p x
1
1
( ) ,
n
F
i
i
h x H as n
n
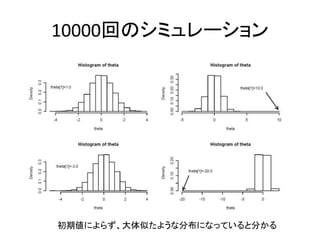
Gibbs sampler (singlecomponent)
• 定常分布を得るための方法の一つである
(0) (0) (0) (0)
1 2
( 1) ( ) ( )
1 1 2
( 1) ( 1) ( ) ( )
2 2 1 3
( 1) ( 1) ( 1) ( )
3 3 1 2 4
1. ; ( , ,.., )
2. ( | ,.., )
( | , ,.., )
( | , , .
p
t t t
p
t t t t
p
t t t t
Step Setinitial parameter
Step sampledrawn from p
sampledrawn from p
sampledrawn from p
θ
( )
( 1) ( 1) ( 1)
1
( ) ( ) ( )
1 1
., )
..................., ( ,.., )
3. 2
,
( ,.., ) ( ,.., )
t
p
t t t
p
t t t
p p
and make
Step loop step
Then after enough iterations
converges to a draw from p
θ
θ
Joint distribution
Bayesian estimation
• ベイズの定理
•我々は普通、データyからパラメータΘがどんなもの
(分布)であるかを知りたい。
• 分布の形が分かればおのずと代表値、ばらつき(信
用区間)が分かる。
( | ) ( )
( | )
( )
,
( | ): , ( ): , ( | ):
( ):
p y p
p y
p y
where
p y posterior p prior p y likelihood
p y normalizing factor
データに欠測があると..
• 手に入ったデータがYobsしかない状況
• ベイズ推定で、パラメータの事後分布をもとめたい
•モンテカルロ積分の立場からみると、p(Ymis|Yobs,R)
の分布から、YmisをD個サンプリングできて、それを
Ymis
(1),..,Ymis
(d)とすると
( | , ) ( , | , )
( | , ) ( | , )
obs mis obs mis
mis obs mis obs mis
p p d
p p d
θ Y R θ Y Y R Y
θ Y Y Y Y R Y
完全データの
事後分布
事後予測分布
( )
1
1
( | , ) ( | , )
d
i
obs mis obs
i
p p
d
θ Y R θ Y Y
25.
MAR assumption;
“ignorability”
• MAR(missingat random)はMIを実行するうえで重要
な仮定
• 欠測のメカニズムが観測されているデータに依存し
て発生している。(観測されていないデータには依存
しない)
• 数式では がいえる
• これで、今後の議論では確率変数Rについては無視
して議論できる(欠測のプロセスをモデル化する必
要がない)
( | , ) ( | )mis obs mis obsp pY Y R Y Y
I-step: regression-based imp.
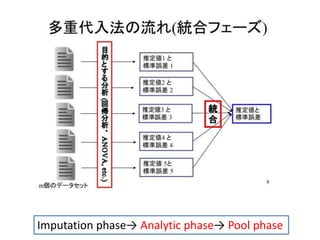
•次のIQとJob performanceのデータ
• 欠測部分を予測分布から求める
IQ Job Performance
78 NA
84 NA
84 NA
85 NA
87 NA
91 NA
92 NA
94 NA
94 NA
96 NA
99 7
105 10
105 11
106 15
108 10
112 10
113 12
115 14
118 16
134 12
30.
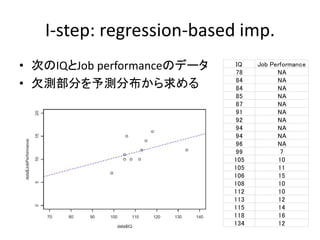
I-step: regression-based imp.
(0)(0)
1 1
(0) (0)
2 2
:
* ,
~ ( , )
~ ( , )
, ,
~ *
obs obspart
mis mispart
regression
JP a b IQ
JP N
IQ N
getthe parameter distributions
of a b
JP a b IQ
観察されている部分で
回帰式を作って
欠測している部分を回
帰式から発生させる
(0) (0)
~ ( | , )mis mis obspY Y θ Y
31.
P-step: regression-based imp.
•次に、完全データ(Ymis
(0), Yobs)より事後分布p(Θ|
Ymis
(0), Yobs)が求まる
(0) (0)
(0) 1
(0) 1
( | , ) ( , | ) ( )
,
( | , , ) ~ Wishart ( 1, )
( | , , ) ~ ultivariate Normal( , )
,where SS means sample sumof squares
mis obs mis obs
mis obs
mis obs
p p p
and in general
p n SS
p M n
θ Y Y Y Y θ θ
Σ μ Y Y
Σ Y Y μ Σ
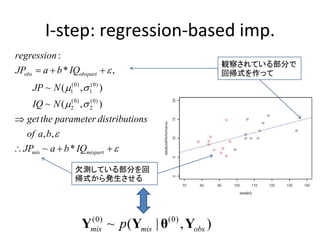
Data Augmentation
(Dempster etal. 1977)
• 次のiterationを繰り返すと、
• が得られる。(regression-basedはこれの特殊な場合)
• Regression-based よりも、乱数の発生が困難!→コ
ンピューターの力を大いに借りる。
• この方法は、Ymisを更新してデータがどんどん大きく
なっていくので Data Augmentation という。
( ) ( )
( 1) ( )
~ ( | , )
~ ( | , )
t t
mis mis obs
t t
mis obs
p
p
Y Y θ Y
θ θ Y Y
36.
Two-component Gibbs sampler
(Liu,1994;Schafer,1997)
• 前述したサンプルは最終的に以下の定常分布に収
束することが分かっている。
• これで欲しかった予測事後分布p(Ymis|Yobs)からのサ
ンプルが得られた。
• このdata augmentation はGibbs samplerの見地から
も正当化され、Liuは”two-component Gibbs
sampler”と呼称している。
( 1)
( 1)
~ ( | )
~ ( | )
t
obs
t
mis mis obs
p
p
θ θ Y
Y Y Y
37.
Two-component Gibbs sampler,
Summary
() ( )
( 1) ( )
( 1)
( 1)
simulate these:
~ ( | , )
~ ( | , )
..........
Then,we get thesamplesdrawnfromthefollowingposterior
~ ( | )
~ ( | )
t t
mis obs
t t
mis mis obs
t
obs
t
mis mis obs
p
p
p
p
θ θ Y Y
Y Y θ Y
θ θ Y
Y Y Y
Rubin’s rule
• では、推定のために平均と分散を導出する
•は各完全データの推定値
( )
1
( )
1
( )
1
1
( | ) ( | , )
[ | ] ( | )
1
( | , )
1
[ | , ]
d
i
obs mis obs
i
obs obs
d
i
mis obs
i
d
i
mis obs
i
p p
d
E p d
p d
d
E
d
θ Y θ Y Y
θ Y θ θ Y θ
θ θ Y Y θ
θ Y Y
( )
[ | , ]i
mis obsE θ Y Y
40.
Rubin’s rule
• 分散:
•ただしBは有限のデータセットによる誤差の補正とし
て次のようにする
1
1
[ | ] [ ( | , ) | ] [ ( | , ) | ]
1
( | , )
1
[ ( | , ) ( | )][ ( | , ) ( | )]
1
obs mis obs obs mis obs obs
d
mis obs
i
d
T
mis obs obs mis obs obs
i
Var E Var Var E
Var
d
E E E E
d
V B
θ Y θ Y Y Y θ Y Y Y
θ Y Y
θ Y Y θ Y θ Y Y θ Y
1
[ | ] (1 )obsVar V B
d
θ Y
参考文献
• Little, R.J. A., & Rubin, D. B.
(2002). Statistical analysis with
missing data. Hoboken, N.J: Wiley.
• Enders, C. K. (2010). Applied
missing data analysis. New York:
Guilford Press.
• Molenberghs, G., Fitzmaurice, G.,
Kenward, M. G., Tsiatis, A. A., and
Verbeke, G. (2014). Handbook of
Missing Data Methodology.
Chapman & Hall/CRC Press.
http://as.wiley.
com/WileyCDA
/WileyTitle/pr
oductCd-
0471183865.ht
ml
http://ww
w.applied
missingda
ta.com/
https://www.
crcpress.com
/Handbook-
of-Missing-
Data-
Methodology
/
参考文献
• Tanner, M.A., & Wong, W. H.. (1987). The Calculation
of Posterior Distributions by Data Augmentation.
Journal of the American Statistical Association,
82(398), 528–540.
• Zhang, P.. (2003). Multiple Imputation: Theory and
Method. International Statistical Review / Revue
Internationale De Statistique, 71(3), 581–592.
• Meng, XL. (1994). Multiple-Imputation Inferences
with Uncongenial Sorces of input. Statistical Science,
9(4), 538-573.






![モンテカルロ積分
• ある積分Hに、確率変数xの確率分布p(x)をかませよう
• ここで、x1, x2, x3,…を確率分布p(x)から独立に抽出した標本と
すると、大数の法則より
• つまり、確率分布p(x)から独立して多くのサンプルが得られ
れば、直接積分を解かなくても、漸近解が得られる。
• これをモンテカルロ積分という。
( )
( ) ( ) ( ) ( ) [ ( )]
( )
( )
, ( )
( )
p
k x
H k x dx p x dx h x p x dx E h x
p x
k x
where h x
p x
1
1
( ) ,
n
F
i
i
h x H as n
n
](https://image.slidesharecdn.com/random-160222083314/85/slide-6-320.jpg)
![モンテカルロ積分:例
• そうすると、扇形の面積はドロップし
た全ての標本の数の中の赤印の割
合で近似できると直感的にわかる
• 右図の例では、100個ドロップしたも
ののうち、80個が赤印。よって
• S ≒ 80/100=0.8
• ドロップした数を増やせば増やすほ
ど近似の精度は高くなる
• X2+y2=1 の円のうちx,y軸が[0,1]までの扇形の面積Sを考えてみよう
• 右図に示すように範囲[0,1]の一様分布から独立かつランダムにサン
プルした値をドロップしていく。
• そして、円の内部に落ちた標本に赤印をつけていく](https://image.slidesharecdn.com/random-160222083314/85/slide-7-320.jpg)


![マルコフ連鎖の例
• 定常分布は正規分布になることは明らか
• 定常分布はtに依らない分布なので
( 1) ( )
( 1) ( )
~ (0.2 , 1.0)
0.2 , ~ (0, 1.0)
t t
t t
N
N
( 1) ( ) ( )
( 1) ( ) 2 ( )
[ ] [ ] 0.2 [ ]
[ ] 0
[ ] [ ] 0.2 [ ] 1
[ ] 1.04
~ (0, 1.04)
t t t
t t t
E E E
E
Var Var Var independently
Var
N
Q](https://image.slidesharecdn.com/random-160222083314/85/slide-12-320.jpg)





















![Rubin’s rule
• では、推定のために平均と分散を導出する
• は各完全データの推定値
( )
1
( )
1
( )
1
1
( | ) ( | , )
[ | ] ( | )
1
( | , )
1
[ | , ]
d
i
obs mis obs
i
obs obs
d
i
mis obs
i
d
i
mis obs
i
p p
d
E p d
p d
d
E
d
θ Y θ Y Y
θ Y θ θ Y θ
θ θ Y Y θ
θ Y Y
( )
[ | , ]i
mis obsE θ Y Y](https://image.slidesharecdn.com/random-160222083314/85/slide-39-320.jpg)
![Rubin’s rule
• 分散:
• ただしBは有限のデータセットによる誤差の補正とし
て次のようにする
1
1
[ | ] [ ( | , ) | ] [ ( | , ) | ]
1
( | , )
1
[ ( | , ) ( | )][ ( | , ) ( | )]
1
obs mis obs obs mis obs obs
d
mis obs
i
d
T
mis obs obs mis obs obs
i
Var E Var Var E
Var
d
E E E E
d
V B
θ Y θ Y Y Y θ Y Y Y
θ Y Y
θ Y Y θ Y θ Y Y θ Y
1
[ | ] (1 )obsVar V B
d
θ Y](https://image.slidesharecdn.com/random-160222083314/85/slide-40-320.jpg)
![正規性
• 事前分布P(Θ)は無情報分布、尤度P(Yobs|Θ)も多変
量正規分布を考えているので、事後分布P(Θ|Yobs)も
多変量正規分布と考えられるよって95%信用区間は
次のように与えられる。検定も同様に可
• しかし、これは無限のデータセットでの仮定なので、
small sampleの場合、z検定をt検定に置換するのと
同じ理屈でt検定ができる。自由度は以下で与えら
れている(Rubin,1987)
(1 )( | ) ( | )obs obsE z Var Y Y
1
( 1)[1 ]
(1 )
V
d
d B
](https://image.slidesharecdn.com/random-160222083314/85/slide-41-320.jpg)
















































![[The Elements of Statistical Learning]Chapter8: Model Inferennce and Averaging](https://cdn.slidesharecdn.com/ss_thumbnails/theelementsofstatisticallearningchapter8modelinferennceandaveraging-181109001318-thumbnail.jpg?width=640&height=640&fit=bounds)




![[ICLR/ICML2019読み会] Data Interpolating Prediction: Alternative Interpretation ...](https://cdn.slidesharecdn.com/ss_thumbnails/20190721shimada-190721024027-thumbnail.jpg?width=640&height=640&fit=bounds)









