北海道大学 認知行動科学研究室にて発表させていただいた,要因計画データに対するベイズ推定アプローチの発表資料です。 内容に関する留意点は http://tyamane1969.net/?p=172 をご覧ください。

























![④結果の解釈
事後分布を見て結果を解釈
正答率pについて,EAP=0.41
95%確信区間(CI)は[0.25, 0.57]](https://image.slidesharecdn.com/bayesfordd-170304055543/75/slide-33-2048.jpg)






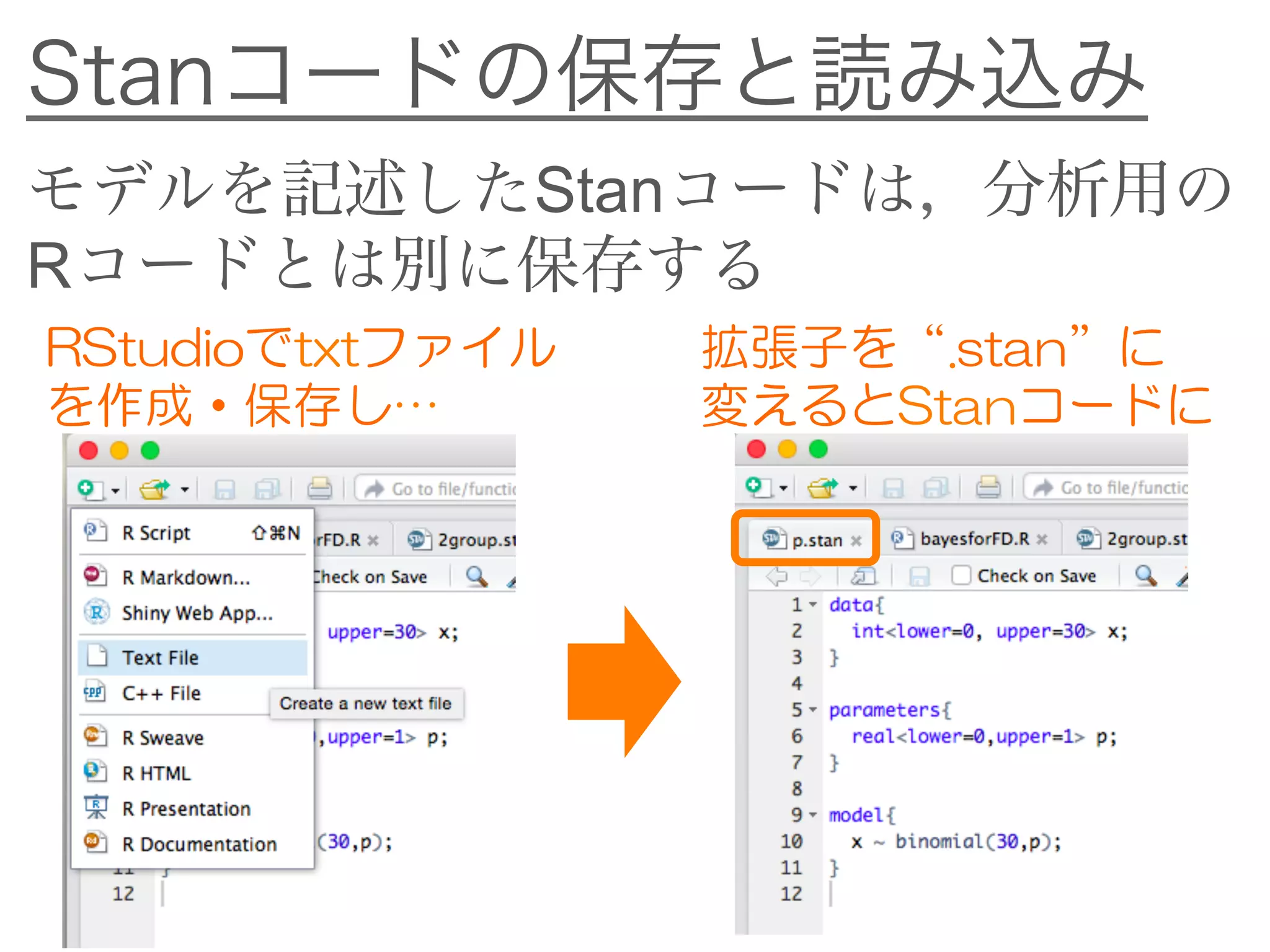
![2群の差の推定:Stanコード
data{}ブロック
int<lower=0> N1;
int<lower=0> N2;
int<lower=0,upper=30> x1[N1];
int<lower=0,upper=30> x2[N2];
N1, N2 → 各群の参加者数
x1, x2 → 各群のデータ
x1[N1]で「データがN1個分ある」
ことを表す
変数の型や下限・上限の指定は
先ほどと同様
《2group.stanを参照してください》](https://image.slidesharecdn.com/bayesfordd-170304055543/75/slide-41-2048.jpg)




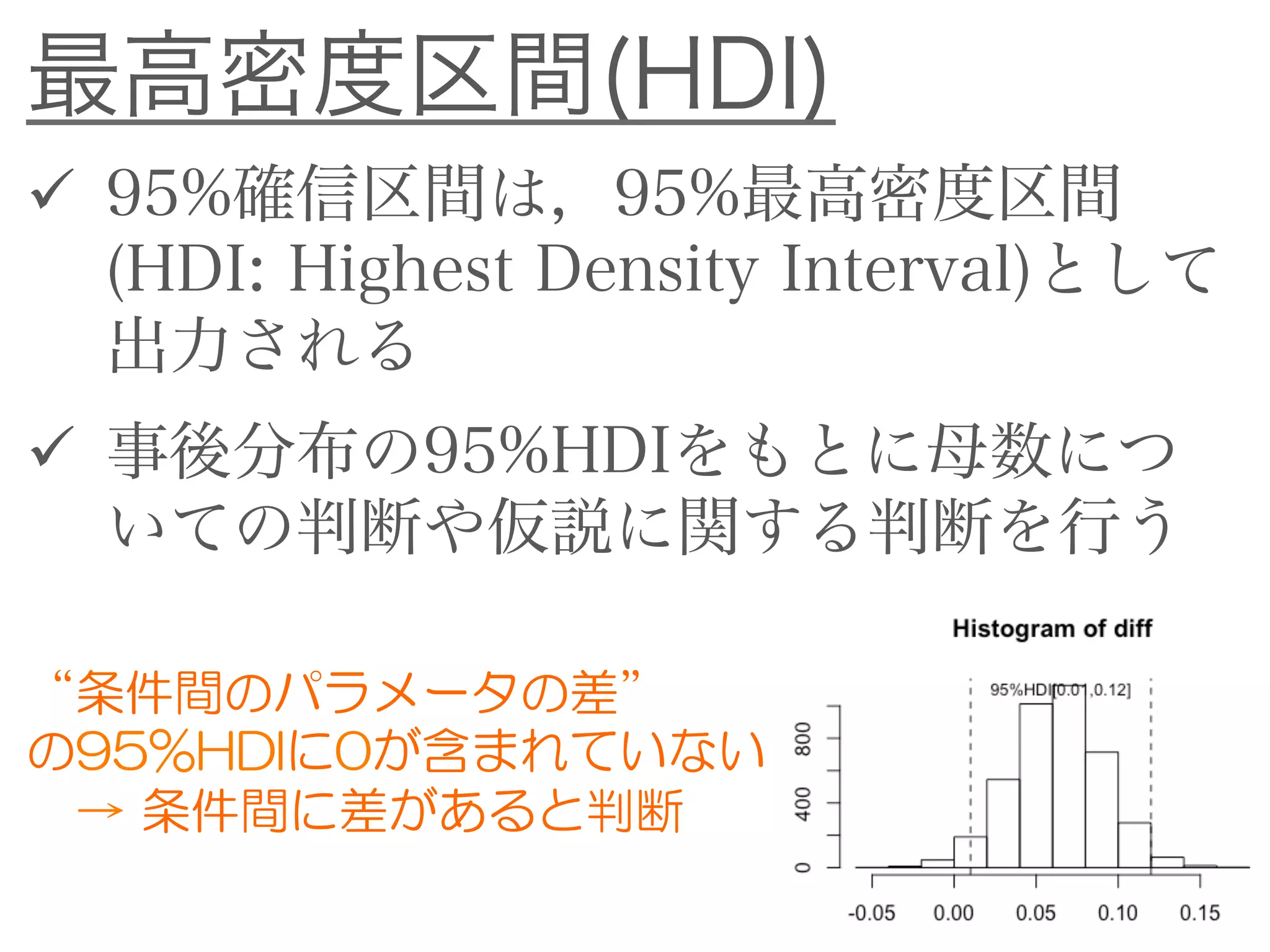
![2群の差の推定:結果の解釈
差の事後分布の95%HDIは[1.51,2.36]
確信区間に0が含まれていないので,条件
間には差があると考えてよい](https://image.slidesharecdn.com/bayesfordd-170304055543/75/slide-46-2048.jpg)




![2群の差の推定(対応あり):Stanコード
data{}ブロック
int<lower=0> N;
vector[2] x[N];
参加者数とデータをベクトル型で
宣言している
《2group_within.stanを参照してください》
parameters{}ブロック
vector[2] mu;
vector<lower=0>[2] sigma;
real<lower=-1, upper=1> rho;
平均値と分散をベクトル,相関を
−1 ~ 1の実数で宣言している](https://image.slidesharecdn.com/bayesfordd-170304055543/75/slide-51-2048.jpg)
![2群の差の推定(対応あり):Stanコード
transformed parameters{}ブロック
matrix[2,2] Sigma;
parameters{}ブロックで宣言した
パラメータをモデルに合うように
変形する
ここでは2変量正規分布の引数に
使うため,sigmaを使って2×2の
共分散行列を作成している](https://image.slidesharecdn.com/bayesfordd-170304055543/75/slide-52-2048.jpg)
![2群の差の推定(対応あり):Stanコード
transformed parameters{}ブロック
matrix[2,2] Sigma;
Sigma[1,1] = sigma[1]*sigma[1];
Sigma[2,2] = sigma[2]*sigma[2];
Sigma[1,2] = sigma[1]*sigma[2]*rho;
Sigma[2,1] = sigma[2]*sigma[1]*rho;
共分散行列のそれぞれの要素を指定
対応ありのデータなので,非対角項
に相関(rho)が掛けられている](https://image.slidesharecdn.com/bayesfordd-170304055543/75/slide-53-2048.jpg)
![2群の差の推定(対応あり):Stanコード
model{}ブロック
for(i in 1:N){
x[i] ~ multi_normal(mu,Sigma);
for文を使って2変量正規分布に
従うモデル式を記述
※muはベクトル,Sigmaは行列型
generated quantities{}
real diff;
diff = mu[2] – mu[1];
平均値の差の生成量を作成](https://image.slidesharecdn.com/bayesfordd-170304055543/75/slide-54-2048.jpg)


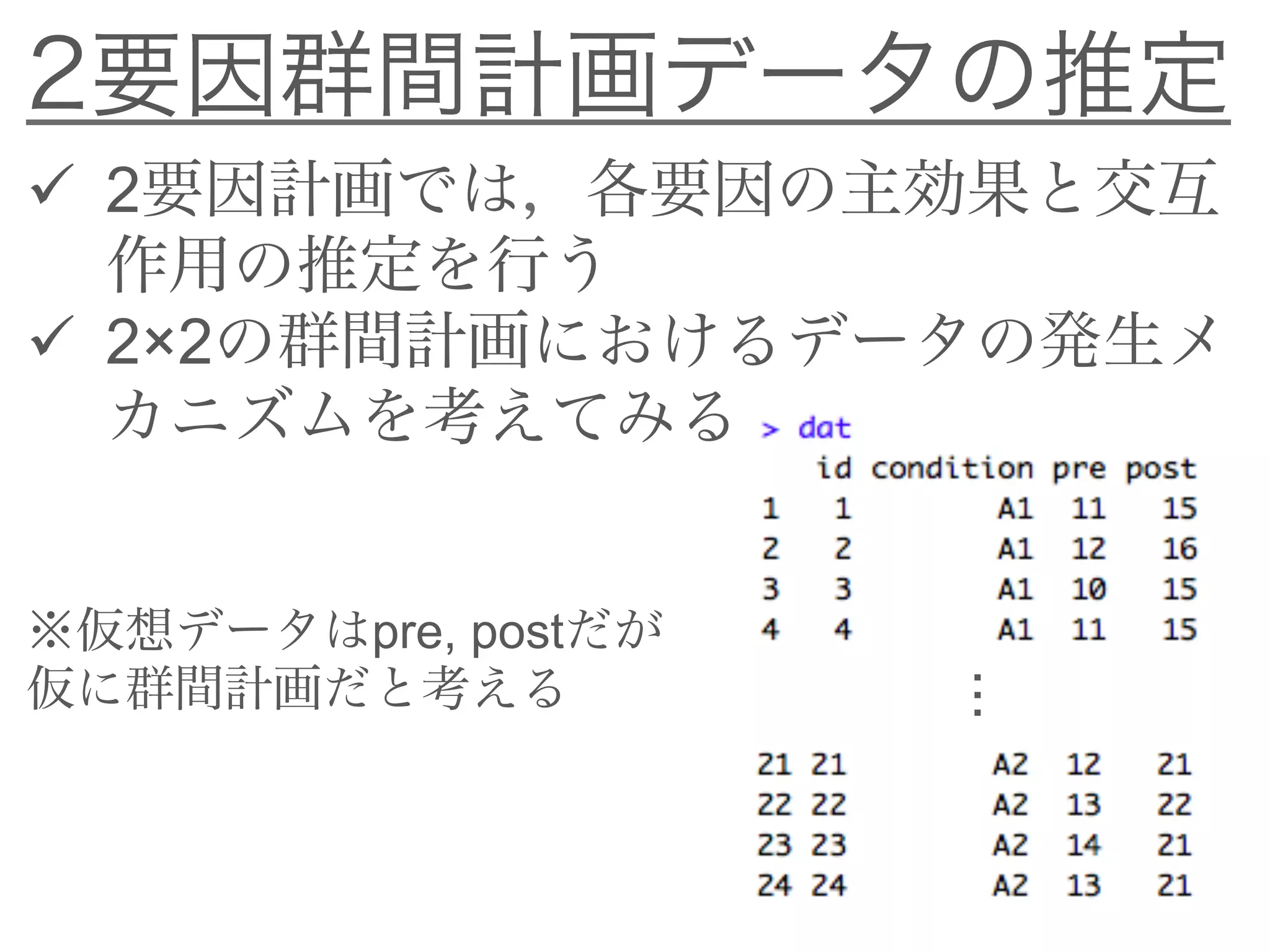




![2要因群間計画データの推定:Stanコード
transformed parameters{}ブロック
Sigma[1,1] = sigma[1]*sigma[1];
Sigma[2,2] = sigma[2]*sigma[2];
Sigma[1,2] = 0;
Sigma[2,1] = 0;
共分散行列のそれぞれの要素
を指定
群間計画のデータなので
非対角成分は0](https://image.slidesharecdn.com/bayesfordd-170304055543/75/slide-62-2048.jpg)
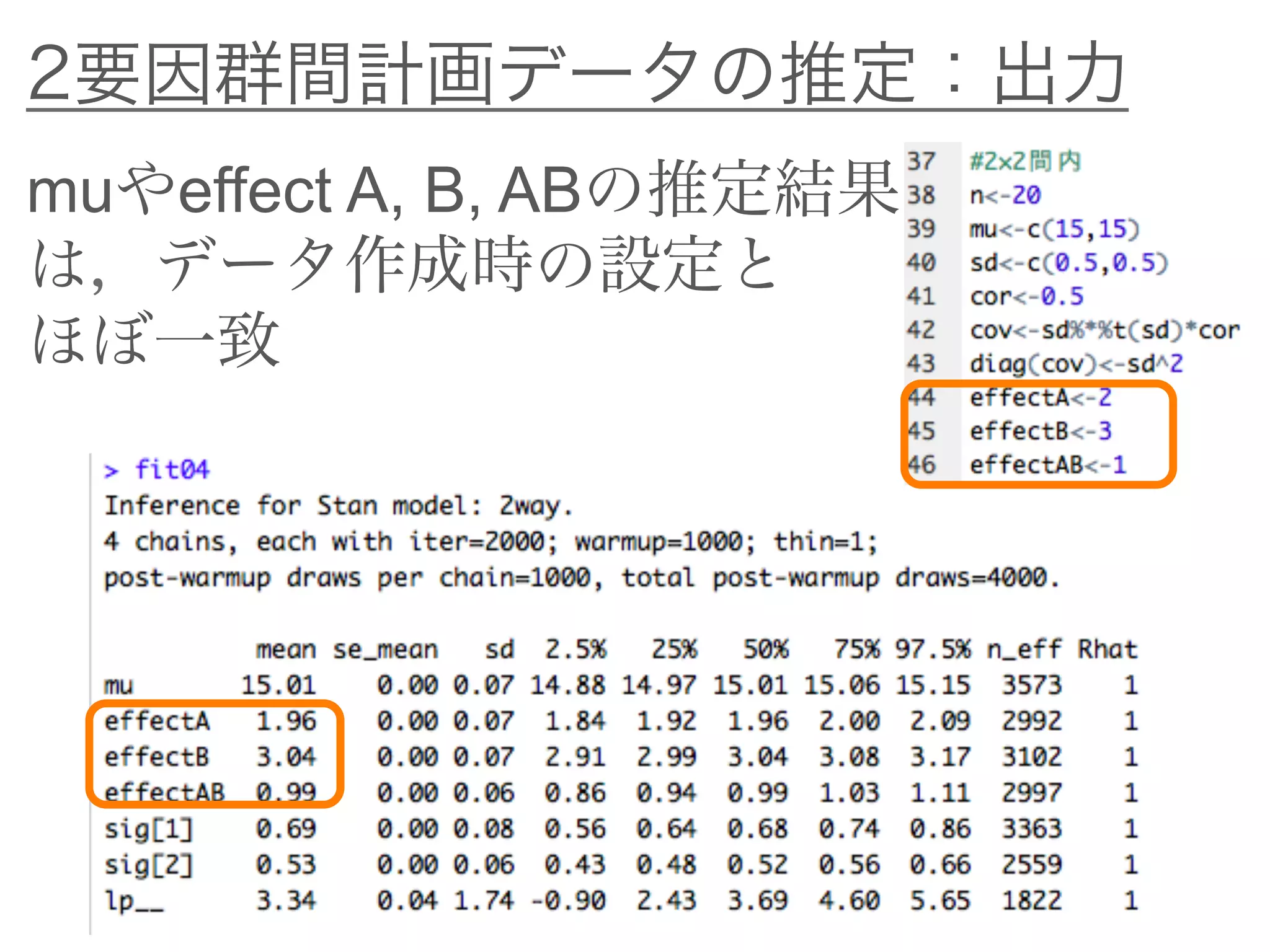
![2要因群間計画データの推定:Stanコード
transformed parameters{}ブロック
mu2[1] = mu – effectB;
mu2[2] = mu + effectB;
要因Bの効果を加える
効果は2つの条件で相殺される
ように加える必要がある
ideal1[1] = mu2[1] – effectA + effectAB;
ideal1[2] = mu2[2] – effectA – effectAB;
ideal2[1] = mu2[1] + effectA – effectAB;
ideal2[2] = mu2[2] + effectA + effectAB;
各条件に要因Aと交互作用ABの
効果を加える](https://image.slidesharecdn.com/bayesfordd-170304055543/75/slide-63-2048.jpg)
![2要因群間計画データの推定:Stanコード
ideal1[1]
ideal2[1] ideal2[2]
ideal1[2]
effect A +
effect A -
effect B - effect B +
effect AB + effect AB -
effect AB - effect AB +](https://image.slidesharecdn.com/bayesfordd-170304055543/75/slide-64-2048.jpg)





















































![[論文解説]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/0123bayes-180123100528-thumbnail.jpg?width=640&height=640&fit=bounds)















