Recommended
PDF
[第2版] Python機械学習プログラミング 第4章
PDF
[第2版] Python機械学習プログラミング 第5章
PPTX
PDF
PDF
PDF
SVM実践ガイド (A Practical Guide to Support Vector Classification)
PPTX
forestFloorパッケージを使ったrandomForestの感度分析
PDF
PDF
異常検知と変化検知 9章 部分空間法による変化点検知
PPTX
Interpreting Tree Ensembles with inTrees
PPTX
PDF
20130716 はじパタ3章前半 ベイズの識別規則
PDF
PPTX
Imputation of Missing Values using Random Forest
PPTX
DLLab 異常検知ナイト 資料 20180214
PDF
PDF
PDF
PDF
遺伝的アルゴリズム�(Genetic Algorithm)を始めよう!
PDF
PDF
PPTX
PPTX
0610 TECH & BRIDGE MEETING
PDF
『問題解決力を鍛える!アルゴリズムとデータ構造』出版記念講演
PPTX
Nttr study 20130206_share
PPT
PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17
PDF
レコメンドアルゴリズムの基本と周辺知識と実装方法
PPTX
Data Mining �6.5 Rule-Based Classification
KEY
More Related Content
PDF
[第2版] Python機械学習プログラミング 第4章
PDF
[第2版] Python機械学習プログラミング 第5章
PPTX
PDF
PDF
PDF
SVM実践ガイド (A Practical Guide to Support Vector Classification)
PPTX
forestFloorパッケージを使ったrandomForestの感度分析
PDF
What's hot
PDF
異常検知と変化検知 9章 部分空間法による変化点検知
PPTX
Interpreting Tree Ensembles with inTrees
PPTX
PDF
20130716 はじパタ3章前半 ベイズの識別規則
PDF
PPTX
Imputation of Missing Values using Random Forest
PPTX
DLLab 異常検知ナイト 資料 20180214
Similar to データマイニングにおける属性構築、事例選択
PDF
PDF
PDF
PDF
遺伝的アルゴリズム�(Genetic Algorithm)を始めよう!
PDF
PDF
PPTX
PPTX
0610 TECH & BRIDGE MEETING
PDF
『問題解決力を鍛える!アルゴリズムとデータ構造』出版記念講演
PPTX
Nttr study 20130206_share
PPT
PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17
PDF
レコメンドアルゴリズムの基本と周辺知識と実装方法
PPTX
Data Mining �6.5 Rule-Based Classification
KEY
PDF
PDF
PDF
PDF
Introduction to ensemble methods for beginners
PDF
データマイニングにおける属性構築、事例選択 1. 2. 3. 4. メリット
p.149 図4. 17 Monk2の属性空間の図形表示
Monk2 : 有名なベンチマークテスト用のデー
タ
(a)の図→何となく法則があるようにみえるがバラ
バラっぽい
(b)の図→すっきり見やすい
(b)で学習するほうが効率がよい
4
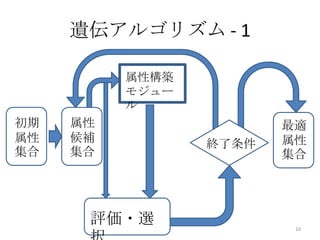
5. 6. 7. 8. 9. 10. 遺伝アルゴリズム - 1
属性構築
モジュー
ル
初期 属性 最適
属性 候補 終了条件 属性
集合 集合 集合
評価・選 10
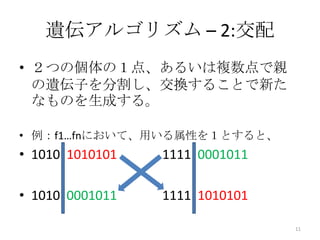
11. 遺伝アルゴリズム – 2:交配
• 2つの個体の1点、あるいは複数点で親
の遺伝子を分割し、交換することで新た
なものを生成する。
• 例:f1…fnにおいて、用いる属性を1とすると、
• 1010|1010101 1111|0001011
• 1010|0001011 1111|1010101
11
12. 遺伝アルゴリズム – 3:突然変異
• 属性の組み合わせなどをランダムに変更
する
• ある組み合わせを使いまわしていると変
化がなくなる
• 組み合わせの多様性を生み出す
• 110011001
010011010
• 110100111
12
13. 遺伝アルゴリズム – 4:評価・選
択
• なるべく評価値の多いものを選択したい
が、多様性も同時に確保しなくてはいけ
ない
• 評価値をつける方法
– 情報利得
– 記述長
– 赤池情報量基準(AIC)
• ルーレット選択
• エリート選択
13
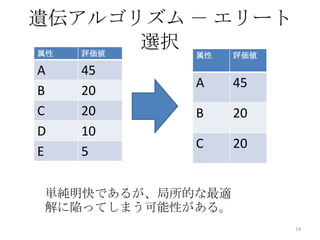
14. 遺伝アルゴリズム - エリート
属性 評価値
選択
属性 評価値
A 45
A 45
B 20
C 20 B 20
D 10
C 20
E 5
単純明快であるが、局所的な最適
解に陥ってしまう可能性がある。
14
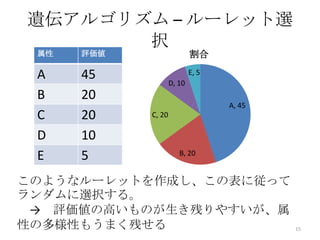
15. 遺伝アルゴリズム – ルーレット選
択
属性 評価値 割合
A 45 D, 10
E, 5
B 20
A, 45
C 20 C, 20
D 10
E 5 B, 20
このようなルーレットを作成し、この表に従って
ランダムに選択する。
→ 評価値の高いものが生き残りやすいが、属
性の多様性もうまく残せる 15
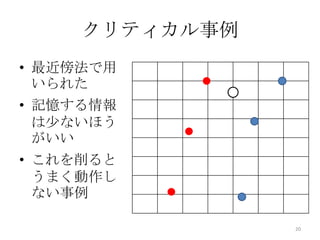
16. 事例選択とは
• ≒ データ削減(文脈で使い分ける)
• 全てのデータを使用したときと比べても
性能が劣化しないようにデータを減ら
し、マイニングの効率を上げる
p.157 図 4.23
削減の方法はさまざまであり、目的、デー
タの分布などに影響を受け、どんなデー
タにも効く削減法は存在しない
16
17. 18. 19. 20. 21. 22. 23. 24. 25. 26.






















![[第2版] Python機械学習プログラミング 第4章](https://cdn.slidesharecdn.com/ss_thumbnails/python-machine-learning-2nd-edition-04-180905090111-thumbnail.jpg?width=640&height=640&fit=bounds)
![[第2版] Python機械学習プログラミング 第5章](https://cdn.slidesharecdn.com/ss_thumbnails/python-machine-learning-2nd-edition-05-180905090112-thumbnail.jpg?width=640&height=640&fit=bounds)
































