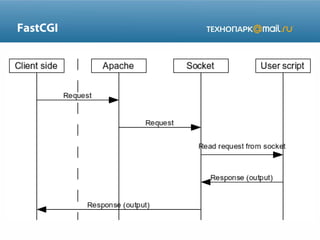
Документ содержит подробные сведения о веб-серверах, их конфигурации и работе с запросами. Описаны ключевые термины, процессы, настройки для Apache и Nginx, а также различные модели обработки сетевых запросов. В конце предоставлены утилиты для мониторинга и указания на домашнее задание по созданию базы данных и интеграции с Django.




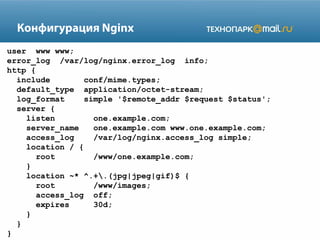
![Файлы Web-сервера
1) Конфиг /etc/apache2/httpd.conf
Include /etc/apache2/mods-available/*
Include /etc/apache2/sites-available/*
2) Скрипт /etc/init.d/apache2 [start|stop|restart]
3) PID-файл /var/run/apache2.pid
4) Error-лог /var/log/apache2/error.log
/var/log/apache2/mydomain-error.log
5) Access-лог /var/log/apache2/access.log
/var/log/apache2/mydomain-access.log](https://image.slidesharecdn.com/presentation-3-131218004158-phpapp01/85/Web-2013-3-5-320.jpg)










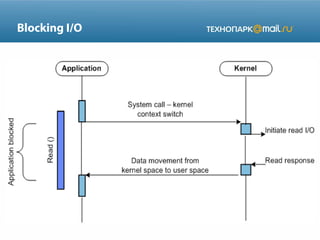

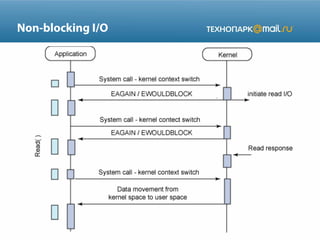
![IO Multiplexing
readsocks = […] # список сокетов для чтения
writesocks = […] # список сокетов для записи
while True:
readables, writeables, exceptions =
select(readsocks, writesocks, [])
for sockobj in readables:
data = sockobj.recv(1024)
if not data:
sockobj.close( )
readsocks.remove(sockobj)
else:
print 'tgot', data, 'on', id(sockobj)](https://image.slidesharecdn.com/presentation-3-131218004158-phpapp01/85/Web-2013-3-22-320.jpg)