近年、実世界の様々な分野において強化学習の活用が進んでいる。2019年6月には、ICML2019にて、Reinforcement Learning for Real LifeというWorkshopが開催された(https://sites.google.com/view/RL4RealLife)。今回の勉強会では、このWorkshopでBest Paperに選ばれた論文の中から、3本を選んで紹介する。いずれも、強化学習を実タスクに適用する上でのアーキテクチャ・アルゴリズム上の工夫について扱っており、強化学習の実運用を検討する上で参考になると考えている。 簡単に内容を説明すると、[1]は強化学習を実世界の問題に適用する際に生じる課題を整理、[2]はFacebookによって開発された、実運用を見据えた強化学習フレームワークについての紹介、[3]はコンピュータシステムのリソース制御に強化学習を適用するためのプラットフォームの紹介となっている。
[1] Challenges of Real-World Reinforcement Learning. ICML 2019 Workshop, https://openreview.net/forum?id=S1xtR52NjN
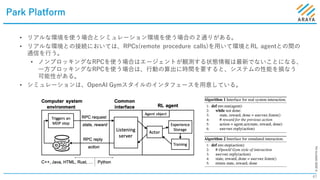
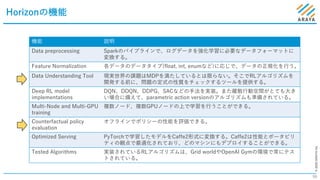
[2] Horizon: Facebook’s Open Source Applied Reinforcement Learning Platform. ICML 2019 Workshop, https://openreview.net/forum?id=SylQKinLi4
[3] Park: An Open Platform for Learning Augmented Computer Systems. ICML 2019 Workshop, https://openreview.net/forum?id=BkgfRbEPsE

































































![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]深層強化学習はなぜ難しいのか?Why Deep RL fails? A brief survey of recent works.](https://cdn.slidesharecdn.com/ss_thumbnails/20210115dlohta-210115054939-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)











![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)

