Recommended
PDF
深層強化学習の分散化・RNN利用の動向〜R2D2の紹介をもとに〜
PDF
DQNからRainbowまで 〜深層強化学習の最新動向〜
PDF
NIPS2017読み会@PFN: Hierarchical Reinforcement Learning + α
PDF
【DL輪読会】Scaling laws for single-agent reinforcement learning
PPTX
【DL輪読会】論文解説:Offline Reinforcement Learning as One Big Sequence Modeling Problem
PDF
PPTX
PPTX
PDF
PDF
Teslaにおけるコンピュータビジョン技術の調査 (2)
PPTX
PDF
PPTX
[DL輪読会]GENESIS: Generative Scene Inference and Sampling with Object-Centric L...
PDF
0から理解するニューラルネットアーキテクチャサーチ(NAS)
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
PDF
[DL輪読会]Understanding Black-box Predictions via Influence Functions
PPTX
PPTX
【DL輪読会】EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Pointsfor...
PDF
[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
PDF
cvpaper.challenge 研究効率化 Tips
PPTX
PDF
[Track2-2] 最新のNVIDIA AmpereアーキテクチャによるNVIDIA A100 TensorコアGPUの特長とその性能を引き出す方法
PPTX
[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
PDF
Transformerを多層にする際の勾配消失問題と解決法について
PDF
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
PDF
[DL輪読会]マルチエージェント強化学習と⼼の理論 〜Hanabiゲームにおけるベイズ推論を⽤いたマルチエージェント 強化学習⼿法〜
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
PPTX
[DL輪読会]Pay Attention to MLPs (gMLP)
PDF
PPTX
【DL輪読会】Contrastive Learning as Goal-Conditioned Reinforcement Learning
More Related Content
PDF
深層強化学習の分散化・RNN利用の動向〜R2D2の紹介をもとに〜
PDF
DQNからRainbowまで 〜深層強化学習の最新動向〜
PDF
NIPS2017読み会@PFN: Hierarchical Reinforcement Learning + α
PDF
【DL輪読会】Scaling laws for single-agent reinforcement learning
PPTX
【DL輪読会】論文解説:Offline Reinforcement Learning as One Big Sequence Modeling Problem
PDF
PPTX
PPTX
What's hot
PDF
PDF
Teslaにおけるコンピュータビジョン技術の調査 (2)
PPTX
PDF
PPTX
[DL輪読会]GENESIS: Generative Scene Inference and Sampling with Object-Centric L...
PDF
0から理解するニューラルネットアーキテクチャサーチ(NAS)
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
PDF
[DL輪読会]Understanding Black-box Predictions via Influence Functions
PPTX
PPTX
【DL輪読会】EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Pointsfor...
PDF
[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
PDF
cvpaper.challenge 研究効率化 Tips
PPTX
PDF
[Track2-2] 最新のNVIDIA AmpereアーキテクチャによるNVIDIA A100 TensorコアGPUの特長とその性能を引き出す方法
PPTX
[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
PDF
Transformerを多層にする際の勾配消失問題と解決法について
PDF
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
PDF
[DL輪読会]マルチエージェント強化学習と⼼の理論 〜Hanabiゲームにおけるベイズ推論を⽤いたマルチエージェント 強化学習⼿法〜
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
PPTX
[DL輪読会]Pay Attention to MLPs (gMLP)
Similar to Hierarchical and Interpretable Skill Acquisition in Multi-task Reinforcement Learning
PDF
PPTX
【DL輪読会】Contrastive Learning as Goal-Conditioned Reinforcement Learning
PDF
PDF
論文紹介:”Playing hard exploration games by watching YouTube“
PDF
PDF
[Dl輪読会]introduction of reinforcement learning
PDF
分散型強化学習手法の最近の動向と分散計算フレームワークRayによる実装の試み
PDF
[DL輪読会]Temporal Abstraction in NeurIPS2019
PDF
PPTX
Multi-agent Inverse reinforcement learning: 相互作用する行動主体の報酬推定
PDF
【論文紹介】PGQ: Combining Policy Gradient And Q-learning
PDF
ICLR2018読み会@PFN 論文紹介:Intrinsic Motivation and Automatic Curricula via Asymmet...
PDF
交差点の交通流におけるシミュレーション環境 を用いた深層強化学習に関する研究
PDF
PDF
PPTX
Efficient Deep Reinforcement Learning with Imitative Expert Priors for Autono...
PDF
PPTX
Learning in a small world
PDF
Computational Motor Control: Reinforcement Learning (JAIST summer course)
PPTX
[DL輪読会]Learn What Not to Learn: Action Elimination with Deep Reinforcement Le...
Hierarchical and Interpretable Skill Acquisition in Multi-task Reinforcement Learning 1. 2. 自己紹介
• 名前
• 仲田 圭佑 (なかた けいすけ)
• 仕事
• データ分析@株式会社ブレインパッド
• 研究開発寄りの部署でお仕事に役立ちそうな機械学習研究のサーベイ
をしつつ、受託分析業務をしています
• 最近気になっている分野
• 強化学習
• 今回のNN論文を肴に酒を飲む会のテーマが強化学習なので今日は楽しみです
3. Hierarchical and Interpretable Skill Acquisition
in Multi-task Reinforcement Learning
• ICLR2018 Poster: https://openreview.net/forum?id=SJJQVZW0b
• arXiv: https://arxiv.org/abs/1712.07294
• arXiv 版はデグレっている (2018/02/08現在) ので、ICLR 版推奨
• Official blog article
• https://einstein.ai/research/hierarchical-reinforcement-learning
• Authors:
• Tianmin Shu
• Univ. of California, Los Angeles
• (Intern at Salesforce Research)
• Caiming Xiong
• Richard Socher
• Salesforce Research
4. 5. 6. Hierarchical Reinforcement Learning
• 階層的にタスクおよび方策・行動を分割する強化学習。
上位/下位の2階層にするのが典型的。
(だが、提案法では多階層が可能)
• global policy (上位)
• 最終ゴールを達成するために必要なサブゴールの系列を決定する
• より抽象的 (「ブロックを探す」等)
• エージェントによって直接実行はできない行動を出力
• option とか macro action とか呼ばれたりする
• local policy (下位)
• サブゴールを達成するための行動系列を決定する
• より具体的 (「前に1歩進む」「前のマスの物体を取得する」等)
• 実際にエージェントが実行可能な、プリミティブな行動を出力
• primitive action とか呼ばれたりする
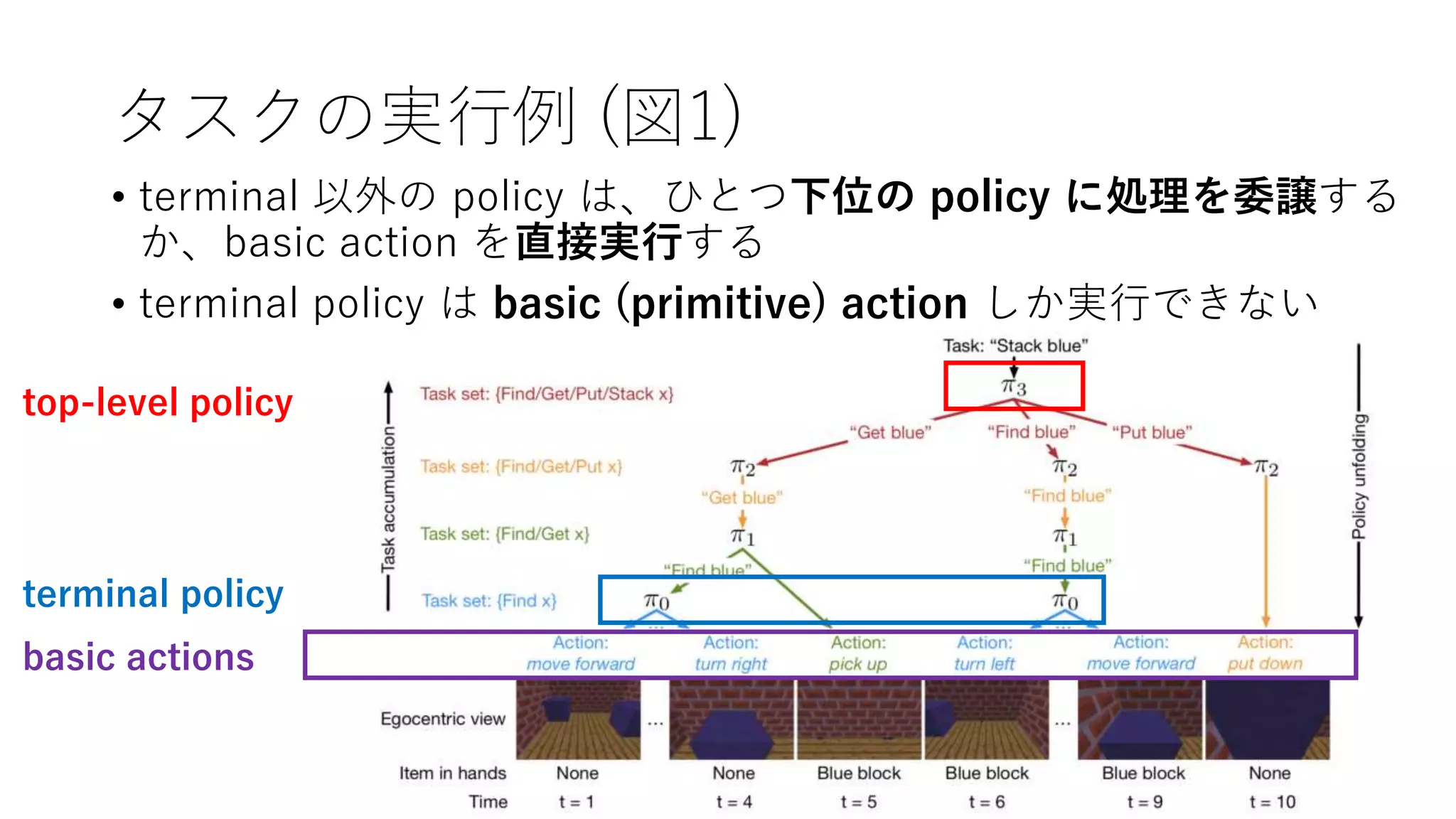
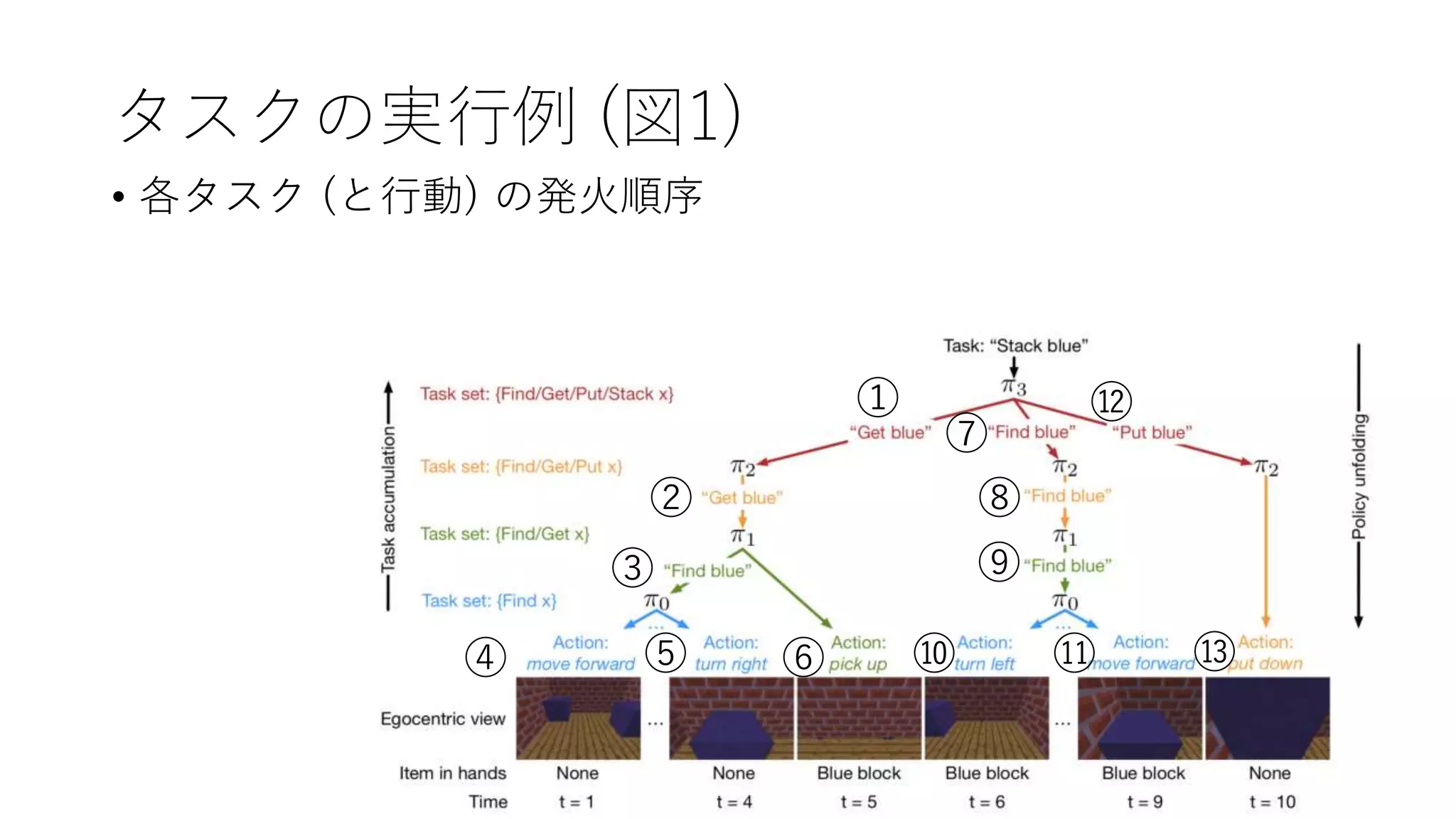
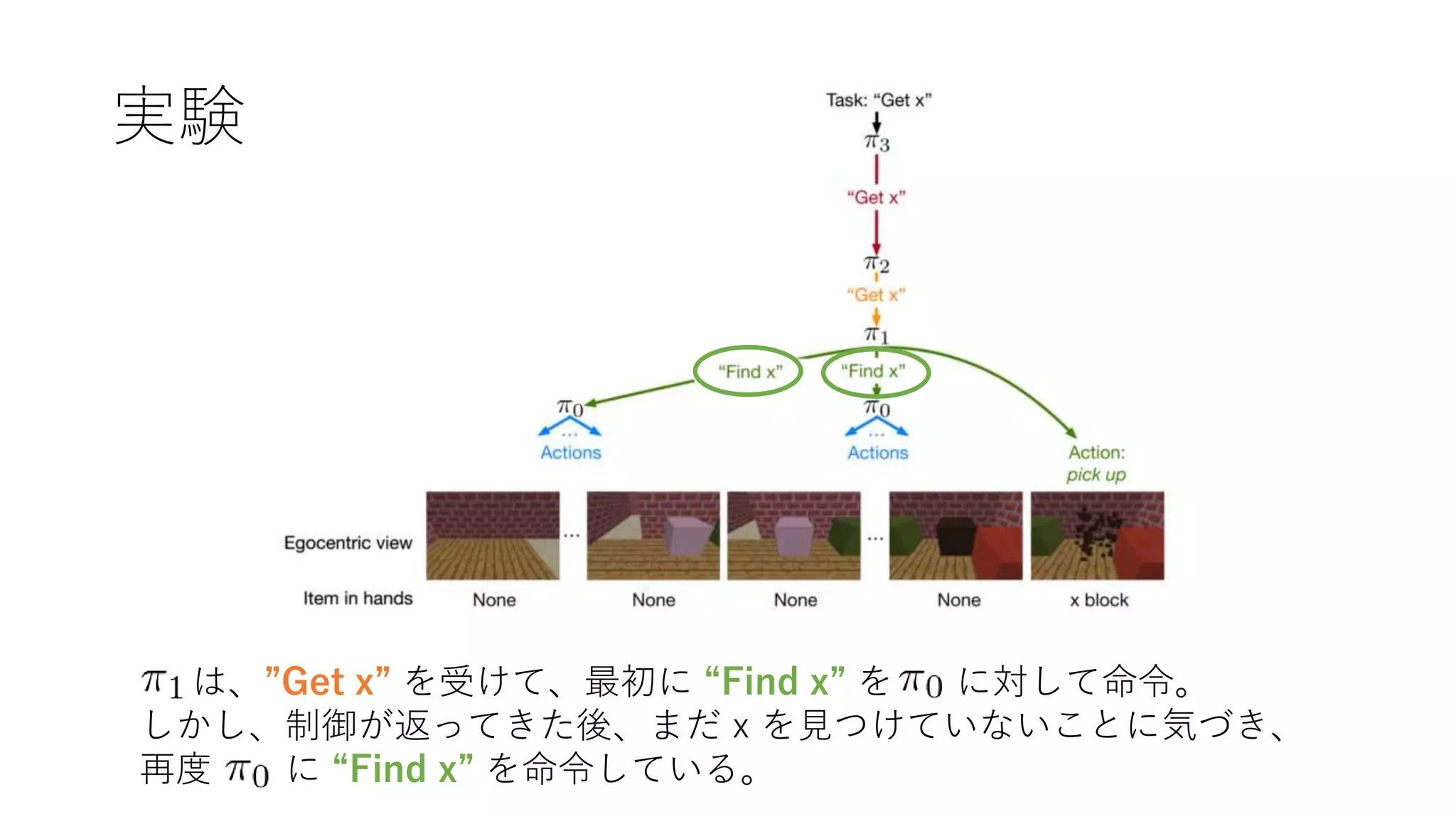
7. 8. タスクの実行例 (図1)
basic actions
terminal policy
top-level policy
• terminal 以外の policy は、ひとつ下位の policy に処理を委譲する
か、basic action を直接実行する
• terminal policy は basic (primitive) action しか実行できない
9. 10. 設定
:(kステージの) タスク。<find blue> とか。
:状態。つまりゲーム画面。※
※ 手持ちのブロックも状態に含む?論文中に明記なし
:プリミティブ行動。「一歩前へ」とか、
「目の前の物体を取得」とか
:報酬。タスク g ごとに与えられることに注意
(<find blue>のクリア条件と<put blue>のクリア条件は異なるため)
:(kステージの) 方策。k=0 なら terminal、
k=K なら top-level policy
は、k が対応するタスクセット を解く。
また、タスクセットは入れ子になっている:
つまり、上位方策は下位方策でも解けるタスクを解くこともある。
(が、実際のところそういうタスクは下位方策に委譲するように訓練させる。後述)
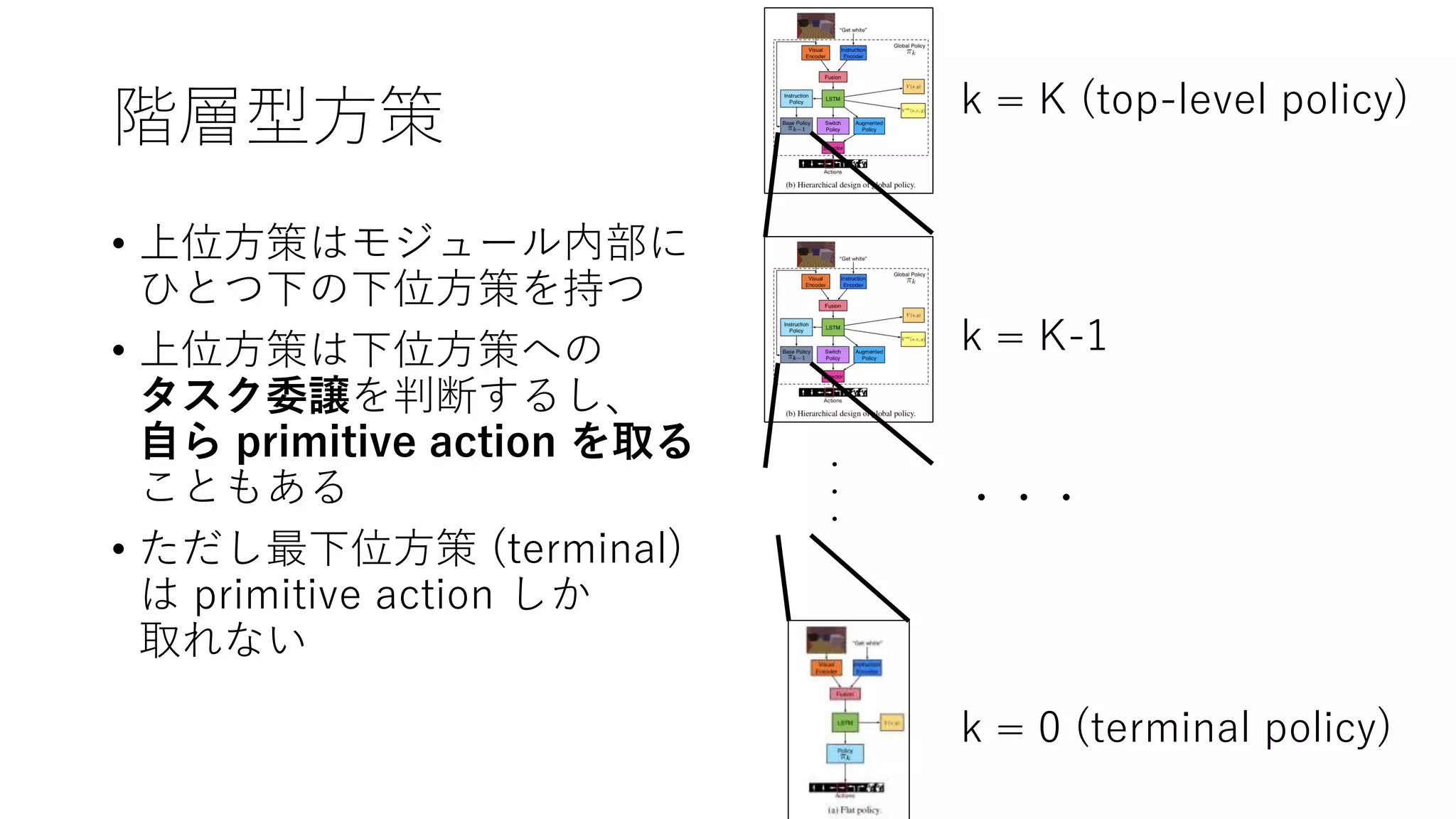
11. 階層型方策
・
・
・
k = K (top-level policy)
k = K-1
k = 0 (terminal policy)
・・・
• 上位方策はモジュール内部に
ひとつ下の下位方策を持つ
• 上位方策は下位方策への
タスク委譲を判断するし、
自ら primitive action を取る
こともある
• ただし最下位方策 (terminal)
は primitive action しか
取れない
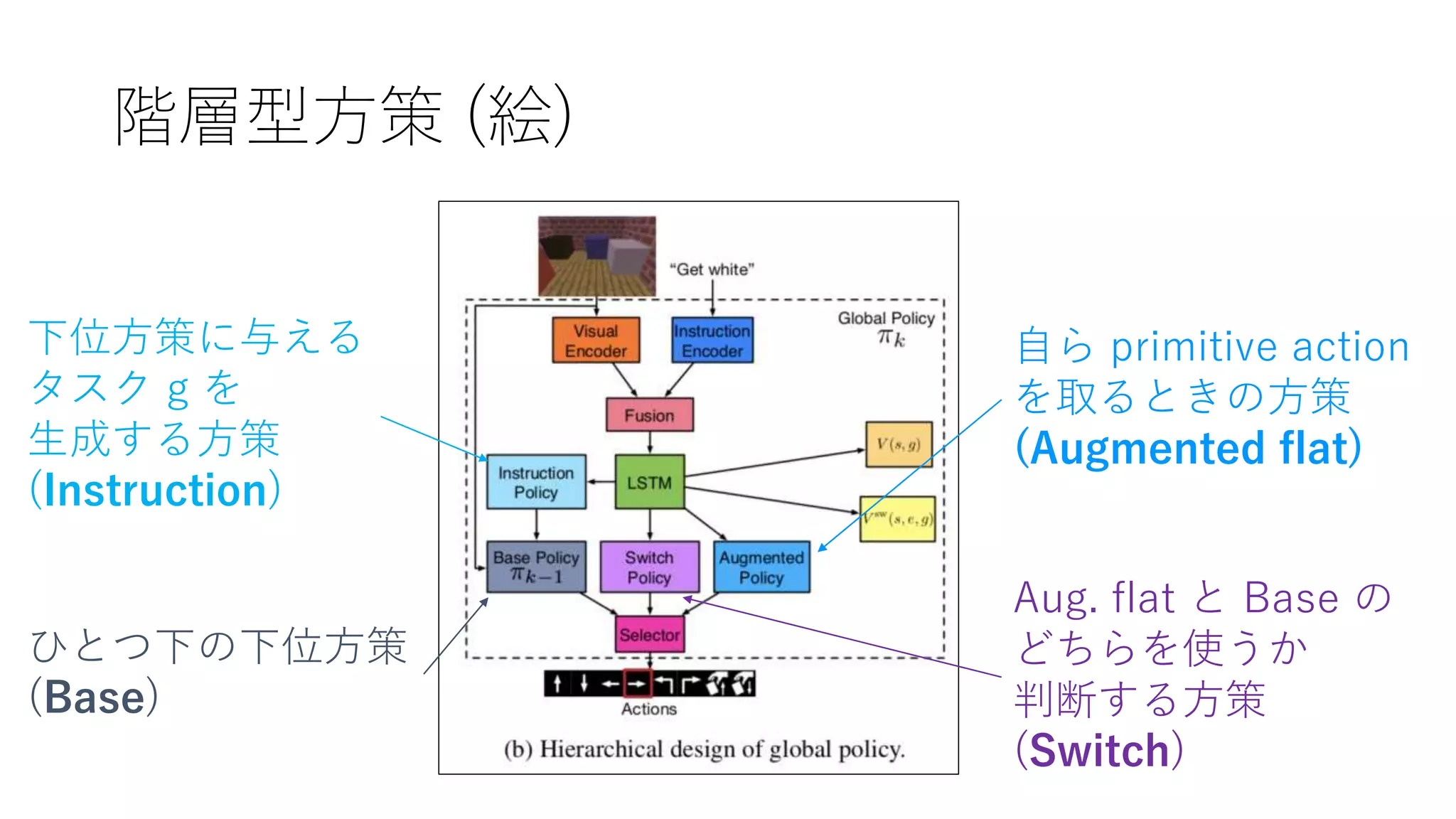
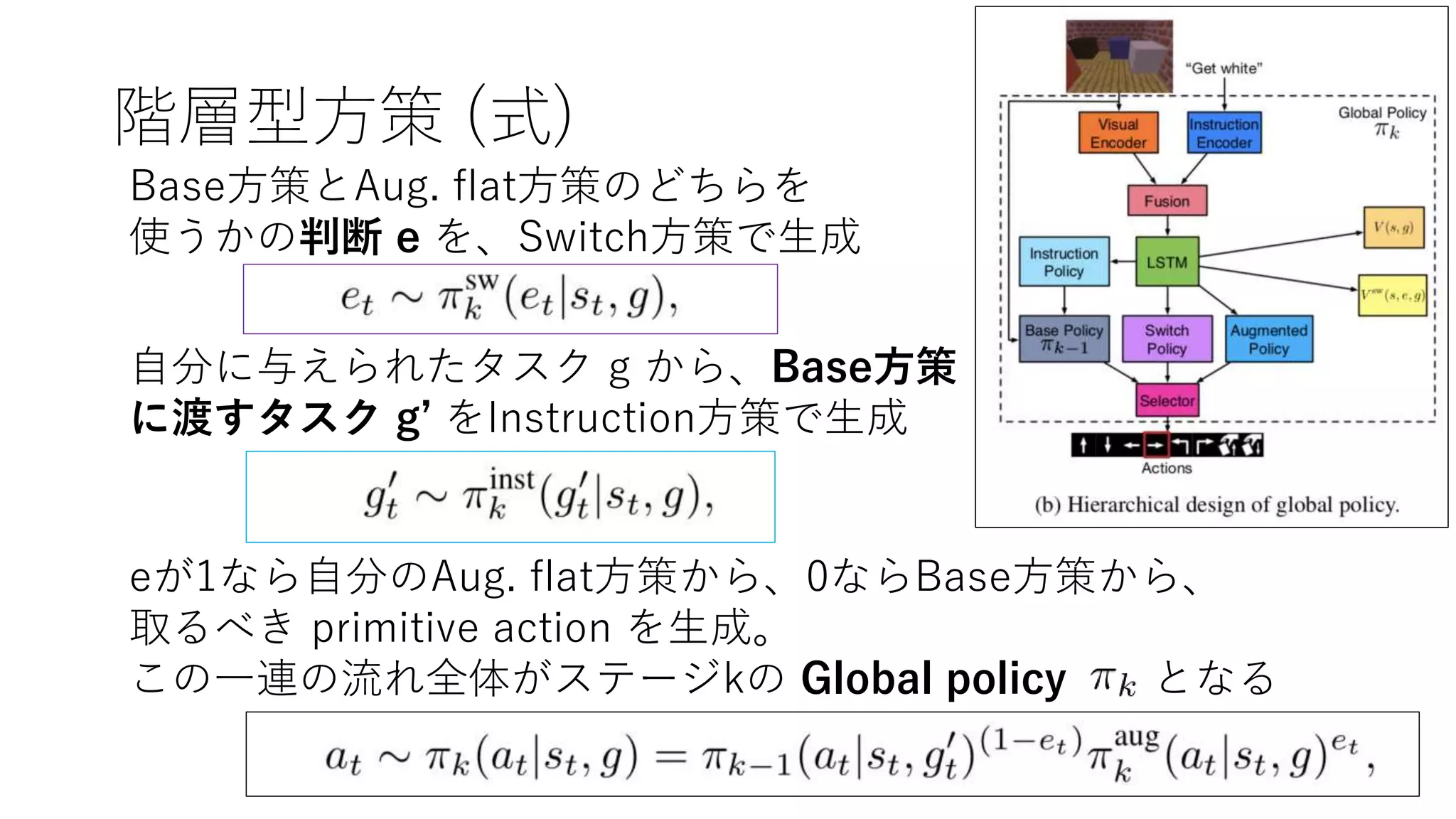
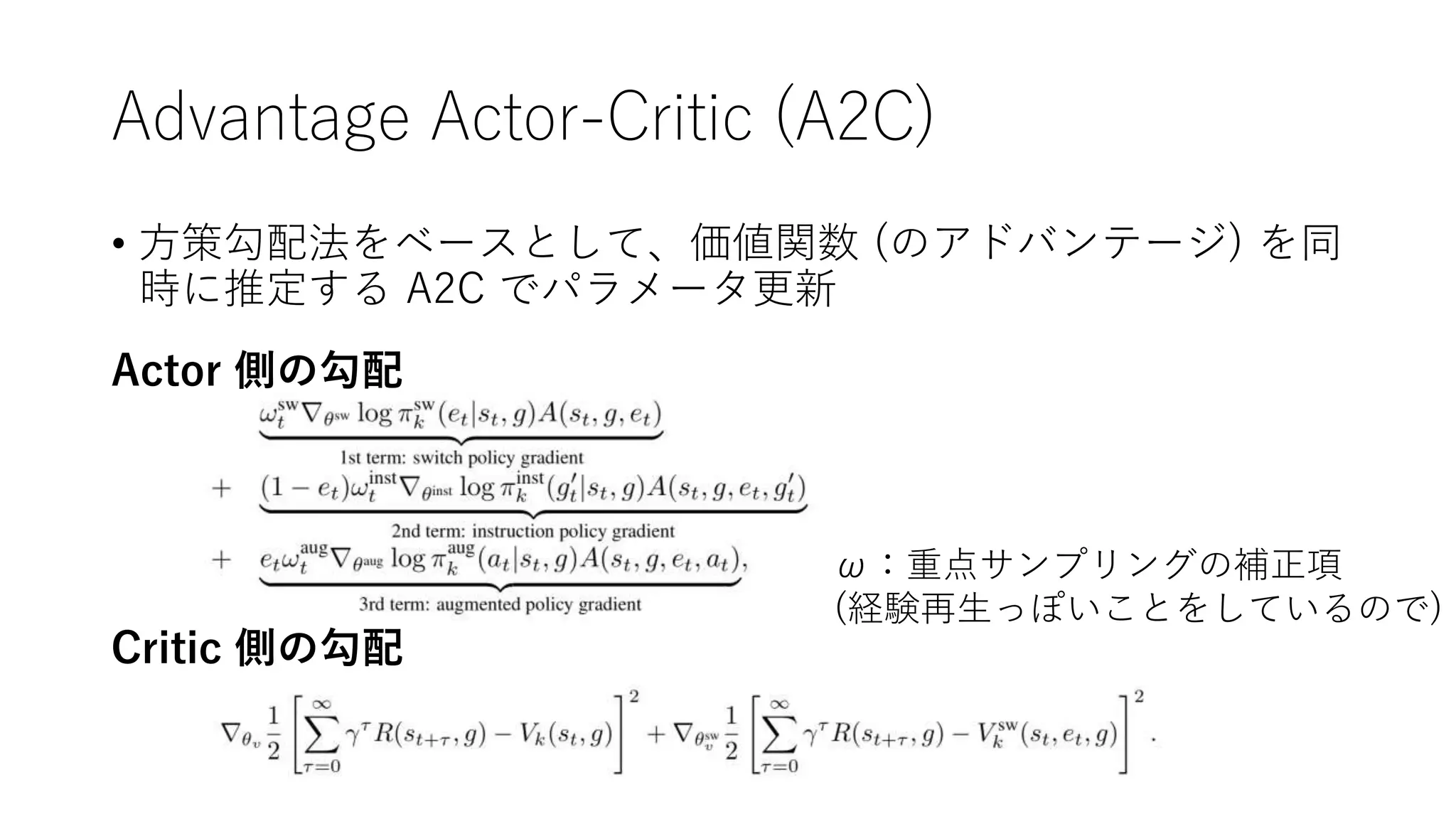
12. 13. 階層型方策 (式)
Base方策とAug. flat方策のどちらを
使うかの判断 e を、Switch方策で生成
自分に与えられたタスク g から、Base方策
に渡すタスク g’ をInstruction方策で生成
eが1なら自分のAug. flat方策から、0ならBase方策から、
取るべき primitive action を生成。
この一連の流れ全体がステージkの Global policy となる
14. Stochastic Temporal Grammar (STG)
• タスクには依存関係がある
• オブジェクトを持っていないと置けないはず。等
• 強化学習とは別に、
過去の成功系列 (positive episode) をもとに、タスクの依存関
係の順番を文法だと考えて、正しい文法を推測。
推測した文法を利用して、方策の事前分布に補正をかける:
やたらごつい名前がついているが、やっていることは、
過去に成功して報酬がもらえたタスク系列に似てほしいから、その経験分布をかけているだけ
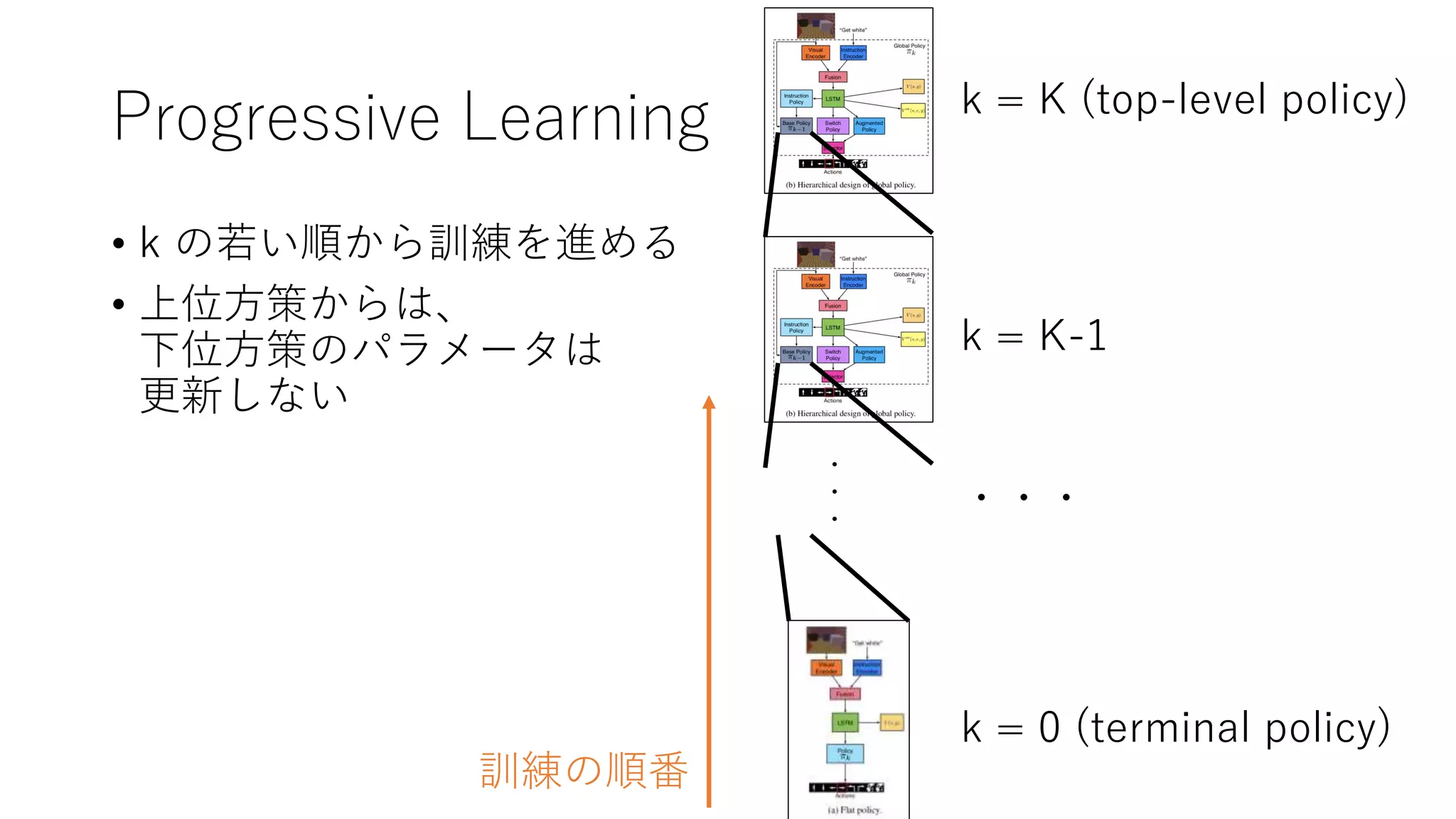
15. 16. Progressive Learning
• k の若い順から訓練を進める
• 上位方策からは、
下位方策のパラメータは
更新しない
・
・
・
k = K (top-level policy)
k = K-1
k = 0 (terminal policy)
・・・
訓練の順番
17. Curriculum Learning
• 同じステージ内でも、2フェイズに分けて訓練する
• Phase1
• base skill acquisition phase
• 下位方策 (下位ステージ, k-1) が訓練に利用したタスクのみを上位方策に解か
せる
• 「下位方策ですでに解けるタスクは、下位方策に適切にタスクを委譲すれば
良い」を学ばせる
• Phase2
• novel skill acquisition phase
• 今のステージ (k) で新たに加わったタスクも含めて解かせる
• 「どのタスクが下位方策で解けて、どのタスクが自ら Aug. flat 方策で解かな
いといけないか」を学ばせる
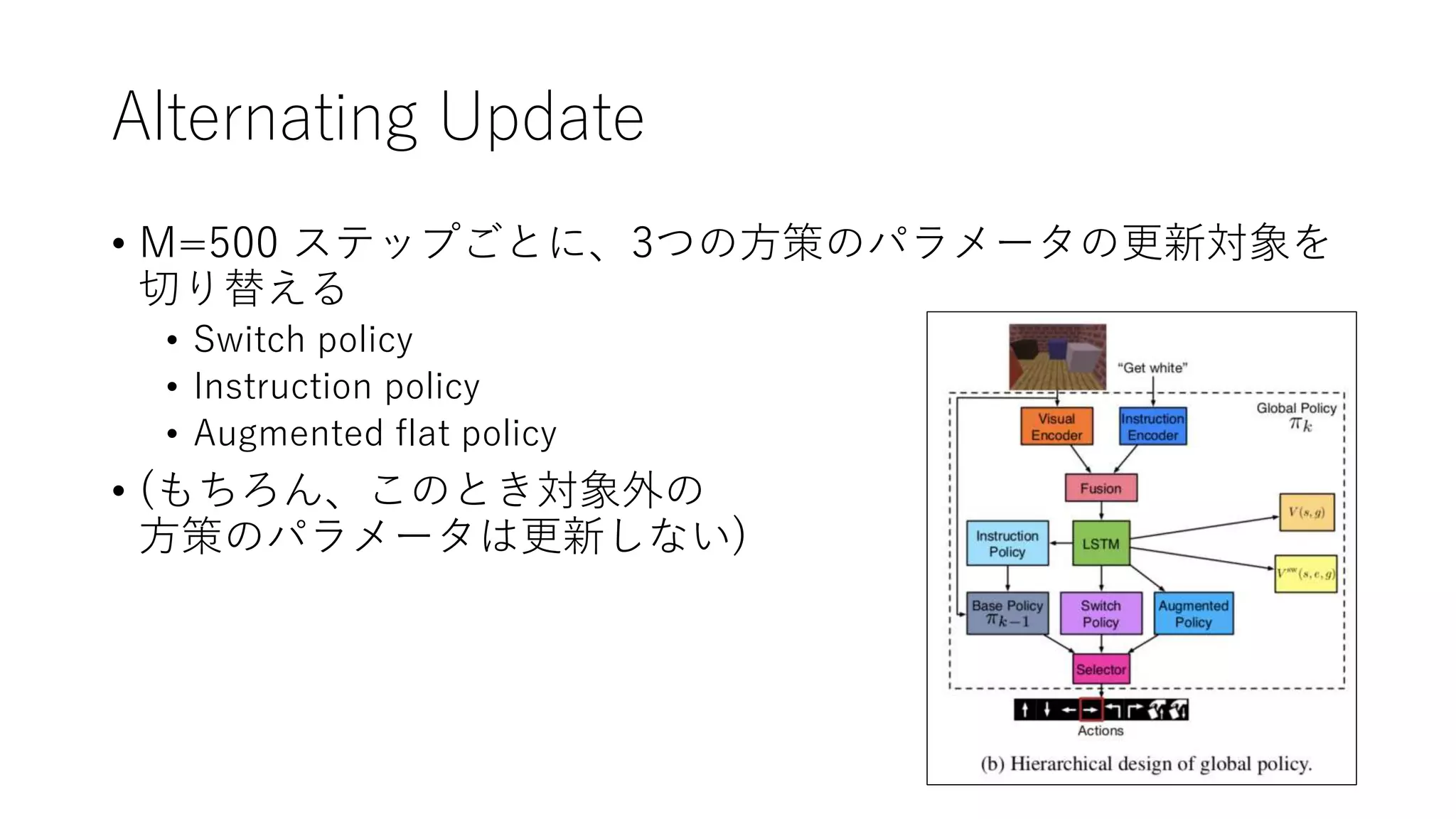
18. Alternating Update
• M=500 ステップごとに、3つの方策のパラメータの更新対象を
切り替える
• Switch policy
• Instruction policy
• Augmented flat policy
• (もちろん、このとき対象外の
方策のパラメータは更新しない)
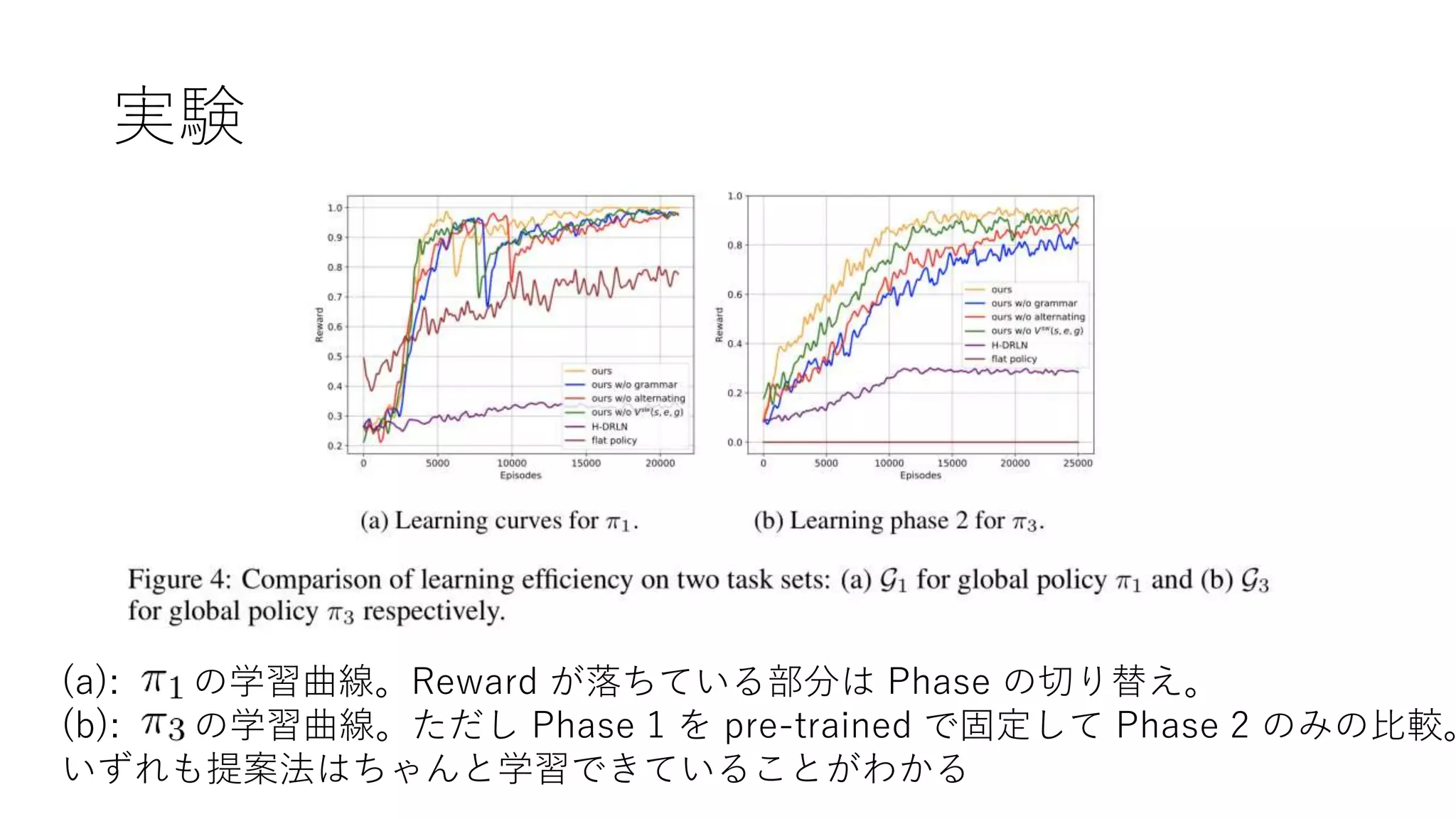
19. 20. 実験
• Minecraft で、「ブロックを重ねる」というタスクを解かせ
る:
=={“Find x”}
={“Find x”, “Get x”}
={“Find x”, ”Get x”, “Put x”}
={“Find x”, “Get x”, “Put x”, “Stack x”}
={“Find x”, “Get x”, “Put x”, “Stack x”, “Put x on y”}
x, y には色の名前 (6種類) が入る。ただし x と y は異なる色。
よってタスクはぜんぶで 種類ある。
各タスクを完遂すると+1の報酬を貰ってエピソード終了。
実行不可能なサブタスクを生成すると-0.5の罰則を受けてエピソード終了。
21. 22. 23. 24. 感想
• かなりの hand-engineering
• 問題設定やモデル設計、学習方法の工夫に人間の事前知識をだいぶ入
れている印象
• この点は論文中でも将来の課題として触れられている
• 下位方策に完全に操作を委譲してしまう提案法のアプローチだ
と、「状況が変わったので、実行中の下位方策を一旦中断して
再度上位方策で方針を決め直す」とかはできなさそう
• 例えば、マルチエージェント系だと、他のエージェントによって状況
を変えられてしまうことが特に起こりやすい気がする
25. 26. 感想
• progressinve/curriculum learning によって簡単なタスクを強制的に先に
学習させ、階層的スキルの未分化/過分化の問題を防止しているように見
える
• 方策蒸留系 (H-DRLN等?) のアプローチも、progressive learning に見える。スキル
の未分化/過分化が自然に防げると思われる
• ICLR2018 には、階層的強化学習系として progressive RL のポスターも通っている
• Progressive Reinforcement Learning with Distillation for Multi-Skilled Motion Control
• https://openreview.net/forum?id=B13njo1R-
27. 参考資料
• Thinking out loud: hierarchical and interpretable multi-task
reinforcement learning
• https://einstein.ai/research/hierarchical-reinforcement-learning
• NIPS2017読み会@PFN: Hierarchical Reinforcement
Learning + α
• https://www.slideshare.net/yukono1/nips2017pfn-hierarchical-
reinforcement-learning
28. 参考文献
• Shu, T., Xiong, C., & Socher, R. (2018). Hierarchical and Interpretable Skill
Acquisition in Multi-task Reinforcement Learning. ICLR.
• Tessler, C., Givony, S., Zahavy, T., Mankowitz, D. J., & Mannor, S. (2017). A
Deep Hierarchical Approach to Lifelong Learning in Minecraft. AAAI.
• Berseth, G., Xie, C., Cernek, P., & Panne, M. Van de. (2018). Progressive
Reinforcement Learning with Distillation for Multi-Skilled Motion Control.
ICLR.
• Hermann, K. M., Hill, F., Green, S., Wang, F., Faulkner, R., Soyer, H., et al.
(2017). Grounded Language Learning in a Simulated 3D World. arXiv preprint.
• Rusu, A. A., Colmenarejo, S. G., Gulcehre, C., Desjardins, G., Kirkpatrick, J.,
Pascanu, R., et al. (2016). Policy Distillation. ICLR.
• Su, P.-H., Budzianowski, P., Ultes, S., Gasic, M., & Young, S. (2017). Sample-
efficient Actor-Critic Reinforcement Learning with Supervised Data for
Dialogue Management. ICLR.































![[DL輪読会]GENESIS: Generative Scene Inference and Sampling with Object-Centric L...](https://cdn.slidesharecdn.com/ss_thumbnails/20191206genesis-191206004127-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Track2-2] 最新のNVIDIA AmpereアーキテクチャによるNVIDIA A100 TensorコアGPUの特長とその性能を引き出す方法](https://cdn.slidesharecdn.com/ss_thumbnails/2020801nvidia-200807073343-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190621dlhack-190621022108-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]マルチエージェント強化学習と⼼の理論 〜Hanabiゲームにおけるベイズ推論を⽤いたマルチエージェント 強化学習⼿法〜](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai1-210917021923-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Learn What Not to Learn: Action Elimination with Deep Reinforcement Le...](https://cdn.slidesharecdn.com/ss_thumbnails/learnwhatnottolearn-180914011647-thumbnail.jpg?width=640&height=640&fit=bounds)