Can AI predict animal movements? Filling gaps in animal trajectories using inverse reinforcement learning, Ecosphere,
Modeling sensory-motor decisions in natural behavior, PLoS Comp. Biol.
Modeling sensory-motor decisionsin
natural behavior
R. Zhang , S. Zhang, M. H. Tong, Y. Cui, C. A. Rothkopf, D. H. Ballard,
M. M. Hayhoe
PLoS Computational Biology, 2018
割引率とは
• 報酬が有界なら、割引積算報酬も有界なので
扱いやすい
• Predictionof immediate and future rewards
differentially recruits cortico-basal ganglia loops
The robot does not move
towards the battery
The robot tries to catch
the battery
large 𝜸
small 𝜸𝑟 ≤ 𝑅max
𝑡
𝛾 𝑡
𝑟𝑡 ≤
𝑅max
1 − 𝛾
[Tanaka et al., 2004]
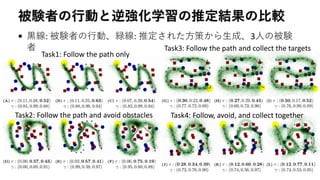
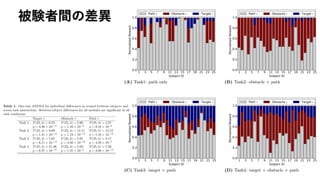
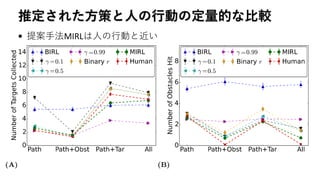
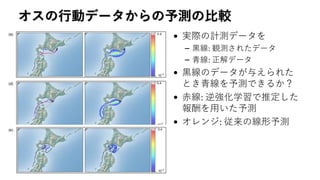
被験者の行動と逆強化学習の推定結果の比較
• 黒線: 被験者の行動、緑線:推定された方策から生成、3人の被験
者
Task1: Follow the path only
Task2: Follow the path and avoid obstacles
Task3: Follow the path and collect the targets
Task4: Follow, avoid, and collect together
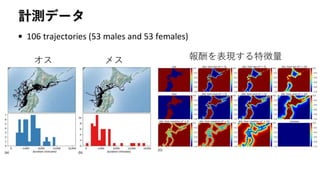
Can AI predictanimal movements? Filling
gaps in animal trajectories using inverse
reinforcement learning
T. Hirakawa, T. Yamashita, T. Tamaki, H. Fujiyoshi, Y. Umezu,
I. Takeuchi, S. Matsumoto, and K. Yoda
Ecosphere, 2018
References
• Doya K.(2008). Modulators of decision making. Nature neuroscience, 11(4):410–416.
• Hirakawa, T., Yamashita, T., Tamaki, T., Fujiyoshi, H., Umezu, Y., Takeuchi, I., Matsumoto, S., and
Yoda, K. (2018). Can AI predict animal movements? Filling gaps in animal trajectories using inverse
reinforcement learning. Ecosphere.
• Tanaka, S.C., Doya, K., Okada, G., Ueda, K., Okamoto, Y., and Yamawaki, S. (2004). Prediction of
immediate and future rewards differentially recruits cortico-basal ganglia loops. Nature
Neuroscience, 7(8): 887-893.
• Zhang , R., Zhang, S., Tong, M. H., Cui, Y., Rothkopf, C. A., Ballard, D. H., and Hayhoe, M. M. (2018).
Modeling sensory-motor decisions in natural behavior. PLoS Computational Biology.
• Ziebart, B., et al. (2008). Maximum entropy inverse reinforcement learning. In Proc. of AAAI.



![逆強化学習の行動解析への応用例
[Mueling et al., 2014]
[Shimosaka et al., 2014; 2015] [Collette et al., 2017]
[Yamaguchi et al., 2018]](https://image.slidesharecdn.com/hirakawa2018a-181112045325/85/NIPS-KANSAI-Reading-Group-7-3-320.jpg)

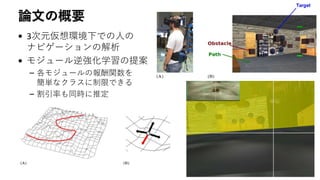
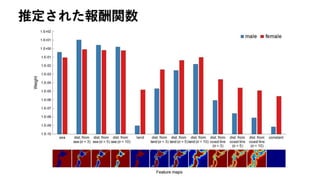
![モジュール化による価値関数の簡単化
• 各モジュールはfollow a path across the room, avoiding obstacles,
heading towards target objectsなど単純化されていると仮定
• さらに状態遷移が決定論的だと仮定
• モジュール𝑛の行動価値が次のように表現できる
– 𝑟 𝑛 , 𝛾 𝑛 が逆強化学習で推定するパラメータ
– 𝑑(𝑠(𝑛.𝑚), 𝑎)が状態𝑠 𝑛,𝑚 で行動𝑎をとった
あと、オブジェクト𝑚までの「距離」
𝑄 𝑛
𝑠 𝑛,𝑚
, 𝑎 = 𝑟 𝑛
× 𝛾 𝑛 𝑑 𝑠 𝑛,𝑚 ,𝑎
[Doya, 2008]](https://image.slidesharecdn.com/hirakawa2018a-181112045325/85/NIPS-KANSAI-Reading-Group-7-7-320.jpg)
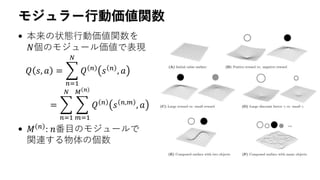
![割引率とは
• 報酬が有界なら、割引積算報酬も有界なので
扱いやすい
• Prediction of immediate and future rewards
differentially recruits cortico-basal ganglia loops
The robot does not move
towards the battery
The robot tries to catch
the battery
large 𝜸
small 𝜸𝑟 ≤ 𝑅max
𝑡
𝛾 𝑡
𝑟𝑡 ≤
𝑅max
1 − 𝛾
[Tanaka et al., 2004]](https://image.slidesharecdn.com/hirakawa2018a-181112045325/85/NIPS-KANSAI-Reading-Group-7-8-320.jpg)

![実際に最適化計算をするときの注意
• 𝑟 1
, … , 𝑟 𝑁
についてのスパースネス正則項(L1)を導入
• 𝛾 1 , … , 𝛾 𝑁 は基本的にスパースではないので何もしない
• 𝜂は報酬との積の形でしか対数尤度に出てこないので推定不可
• 𝑟 1:𝑁 と𝛾 1:𝑁 を同時に推定すると対数尤度は凸ではないので、
最適化が困難
– 𝛾 1:𝑁
はグリッドサーチ
– 𝑟 1:𝑁 は勾配法で最適化。𝛾 1:𝑁 が与えられたとき対数尤度は凸
[Dvijotham and Todorov, 2010]](https://image.slidesharecdn.com/hirakawa2018a-181112045325/85/NIPS-KANSAI-Reading-Group-7-10-320.jpg)



![最大エントロピ逆強化学習の適用
• モデルベース逆強化学習MaxEnt IRL [Ziebart et al., 2010]を適用
• 環境を量子化し、離散状態・離散行動MDP環境を作成
– 元の連続状態は位置(𝑥𝑡, 𝑦𝑡)と経過時間𝑧𝑡](https://image.slidesharecdn.com/hirakawa2018a-181112045325/85/NIPS-KANSAI-Reading-Group-7-19-320.jpg)
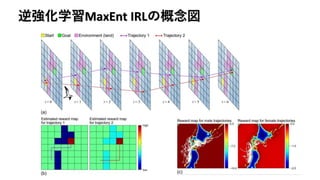
![MaxEnt IRL [Ziebart et al., 2008]
• 前述のModular IRLとは異なり、軌跡𝜏 = {𝑠1, 𝑎1, … , 𝑠 𝑇, 𝑎 𝑇}に対して
確率モデルを導入
– 𝜽は即時報酬のパラメータ
• 勾配計算には𝑍 𝜃 の微分
が必要だが、𝑍(𝜃)の評価
には順方向の強化学習計算が必要
• 何度も順方向の問題を解く必要がある
𝑃 𝜏 𝜽 =
1
𝑍 𝜽
exp
𝑡=1
𝑇
𝑟(𝑠𝑡, 𝑎 𝑡; 𝜽) , 𝑍(𝜽) =
𝜏
exp
𝑡=1
𝑇
𝑟 𝑠𝑡, 𝑎 𝑡; 𝜽
𝜏 総報酬
𝜏
Pr(𝜏𝑖)
𝜏](https://image.slidesharecdn.com/hirakawa2018a-181112045325/85/NIPS-KANSAI-Reading-Group-7-21-320.jpg)







![[DL輪読会]Learning Robust Rewards with Adversarial Inverse Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/180201dllearningrobustrewardswithadversarial3-180205170610-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会] Adversarial Skill Chaining for Long-Horizon Robot Manipulation via T...](https://cdn.slidesharecdn.com/ss_thumbnails/211210dlseminarnakamoto-211210051019-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)





