Download as PDF, PPTX




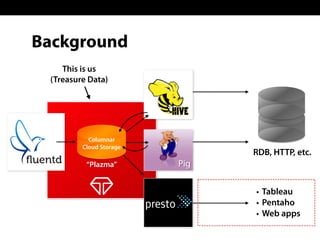
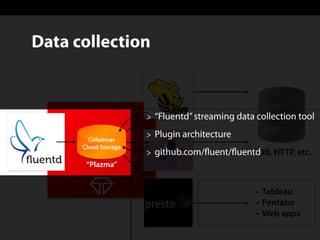
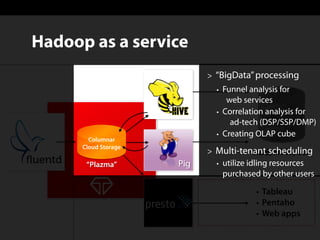
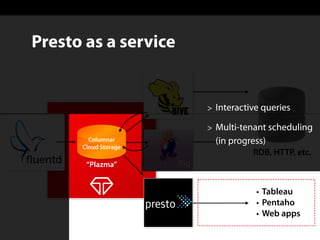
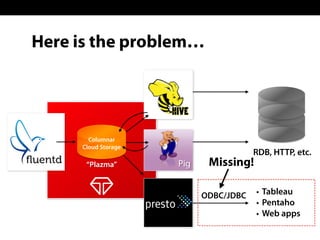
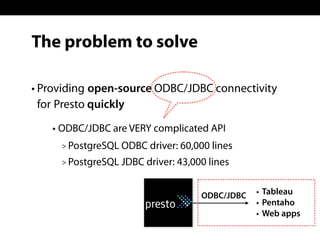



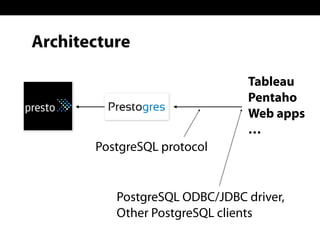
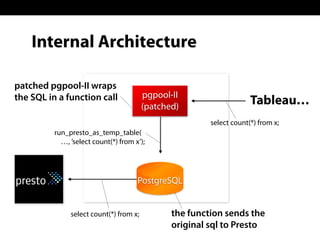
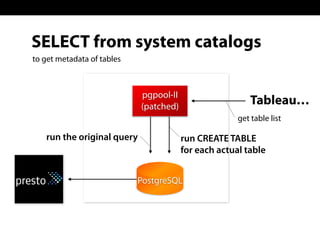




Sadayuki Furuhashi, founder and software architect at Treasure Data, focuses on providing open-source ODBC/JDBC connectivity for Presto. The document outlines a solution using PostgreSQL ODBC/JDBC drivers and a PostgreSQL protocol gateway to facilitate data collection and processing for applications like Tableau and Pentaho. Additionally, it discusses architecture limitations and mentions that Treasure Data is hiring.























































































