Downloaded 94 times







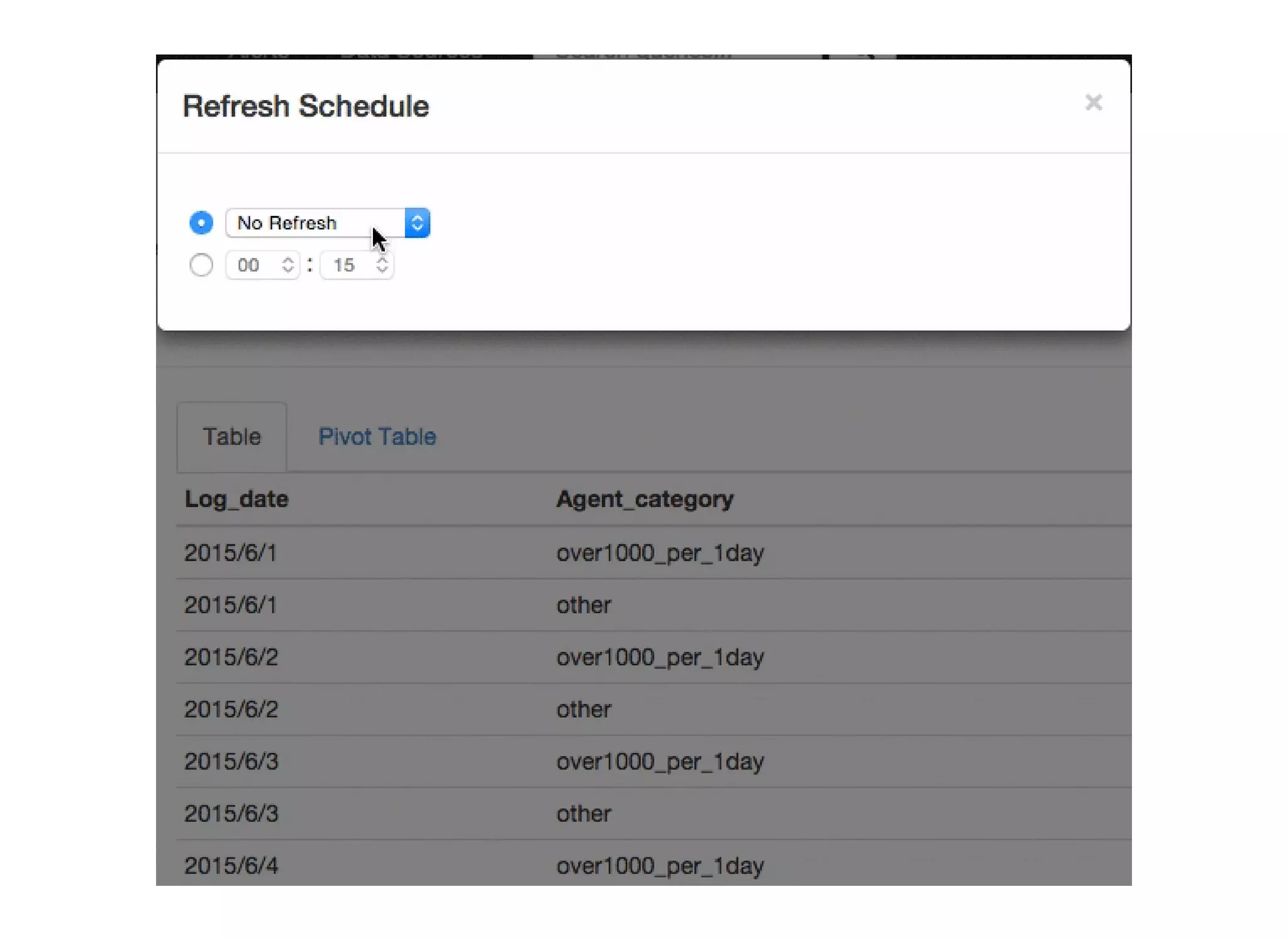





















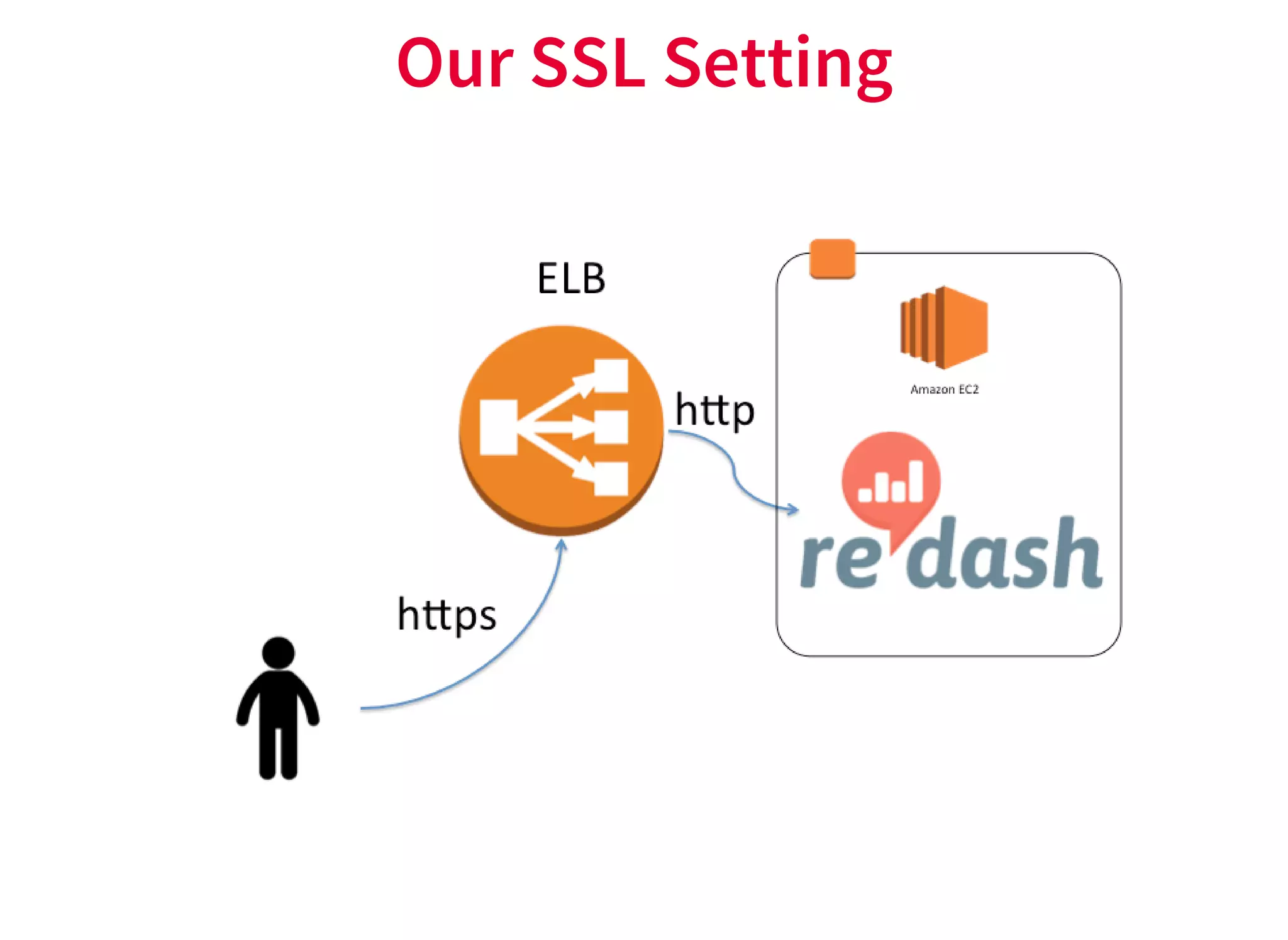




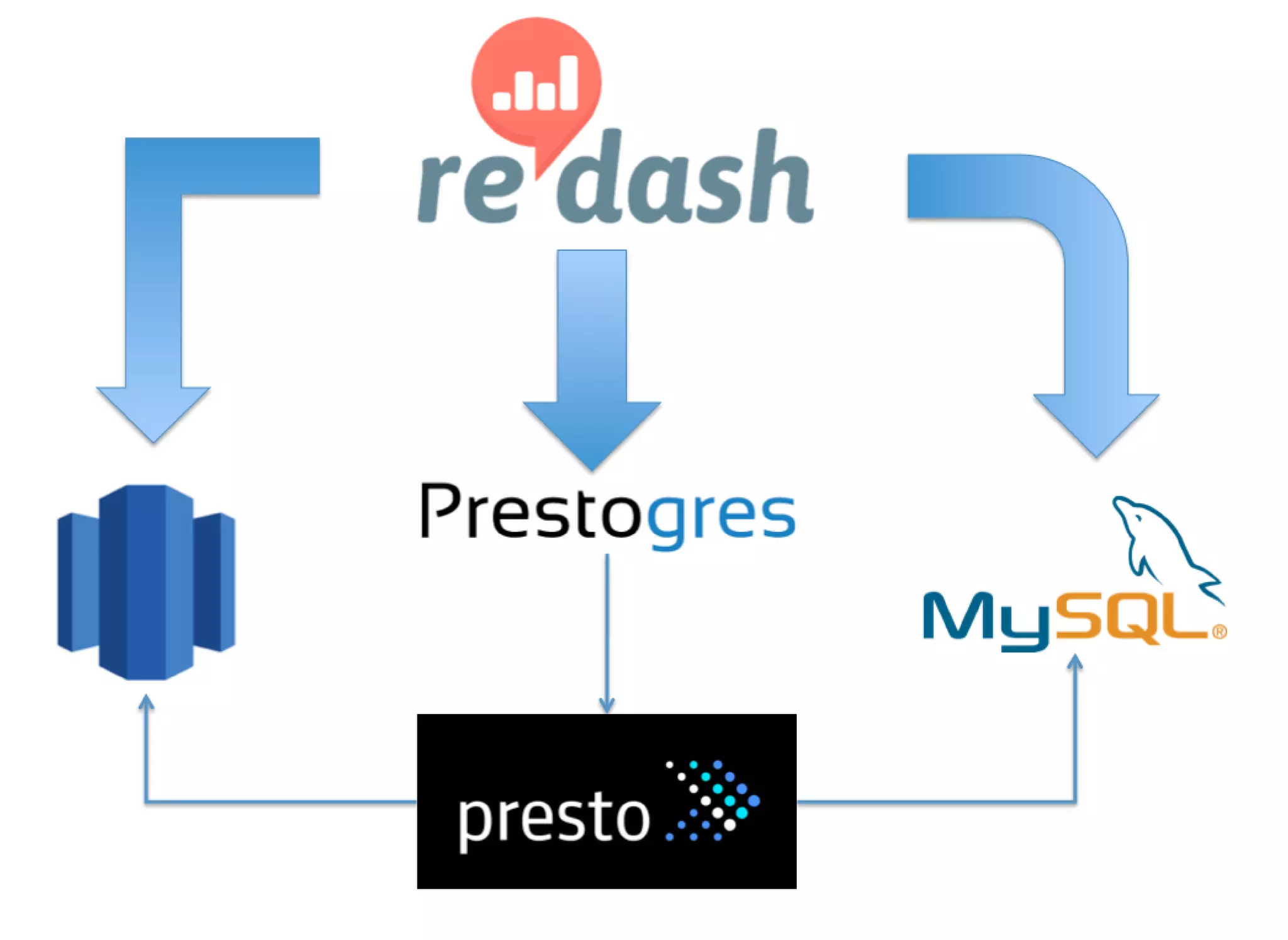






re:dash is a tool for sharing SQL queries, visualizing results, and scheduling automated refreshes. It supports connecting to various data sources, provides a low-cost option on AWS, and enables caching of query results for improved performance. Key features include sharing queries with team members, running queries on a schedule, connecting to backends like PostgreSQL, and programming visualizations and parameters through the HTTP API. It also focuses on security features such as authentication, authorization, auditing, and SSL encryption.



![[Cloud OnAir] #01 徹底解剖 GCP のここがすごい](https://cdn.slidesharecdn.com/ss_thumbnails/cloudonairgcp-171005103254-thumbnail.jpg?width=640&height=640&fit=bounds)
























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)











