Download as PDF, PPTX






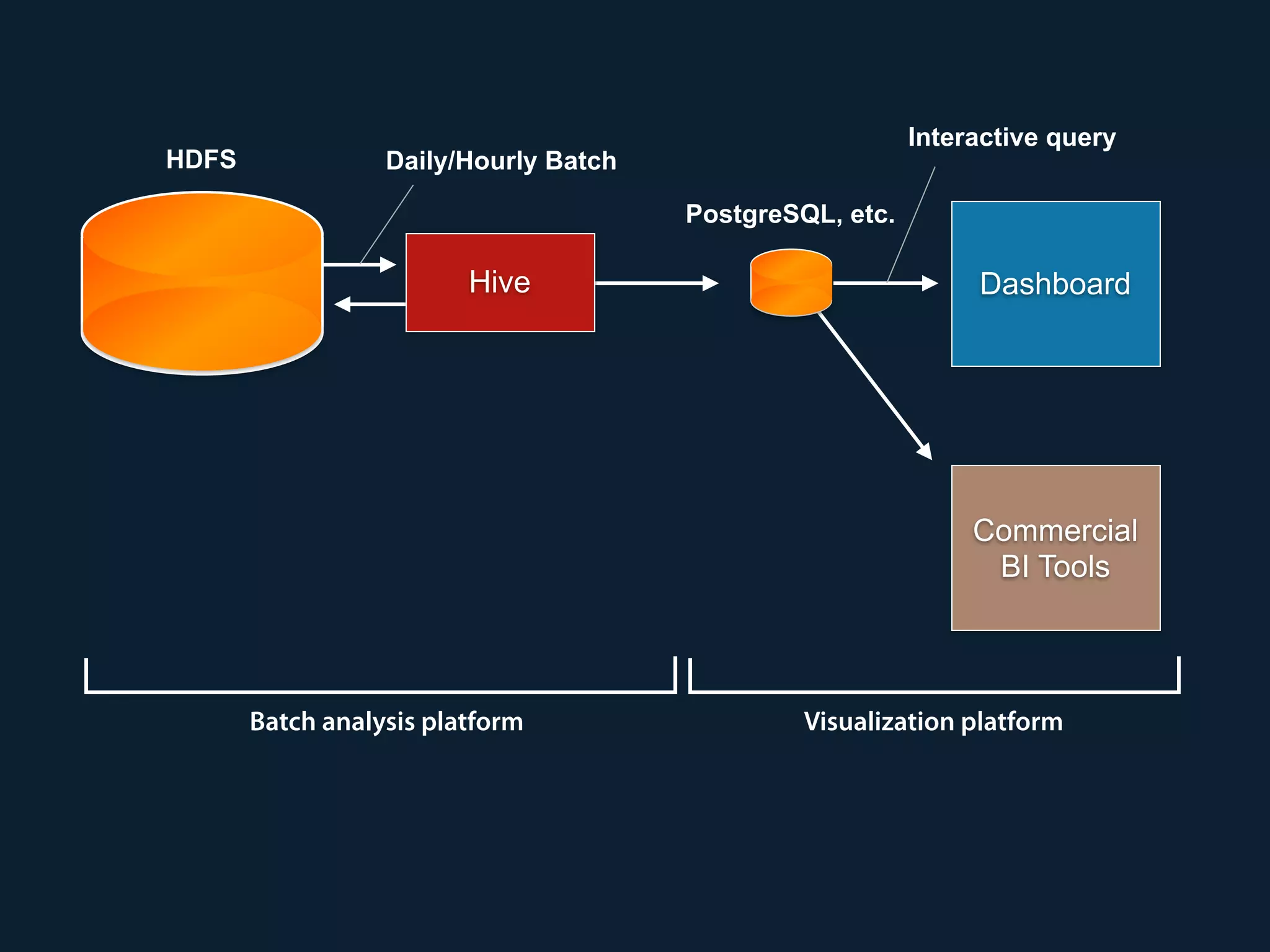
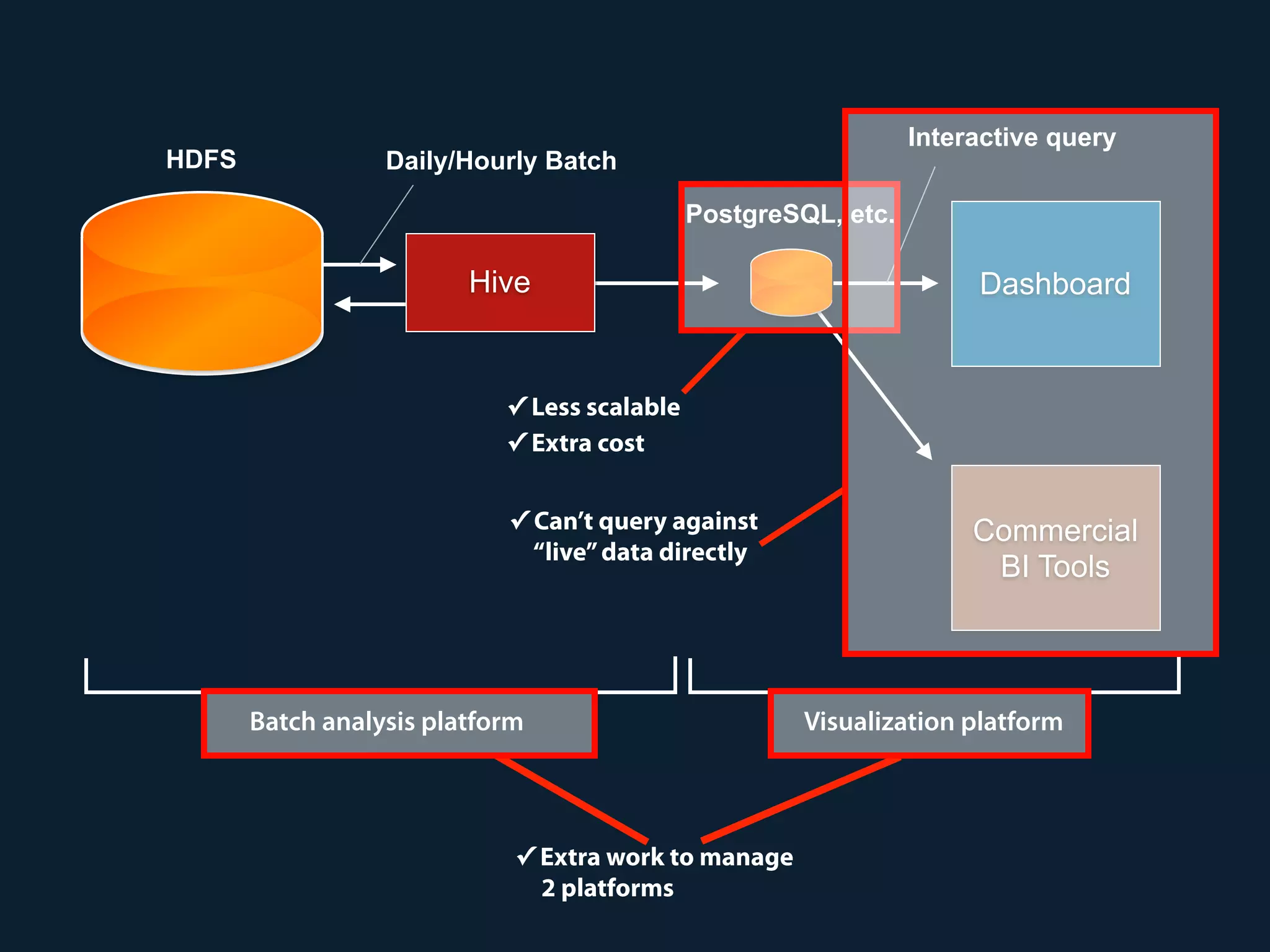
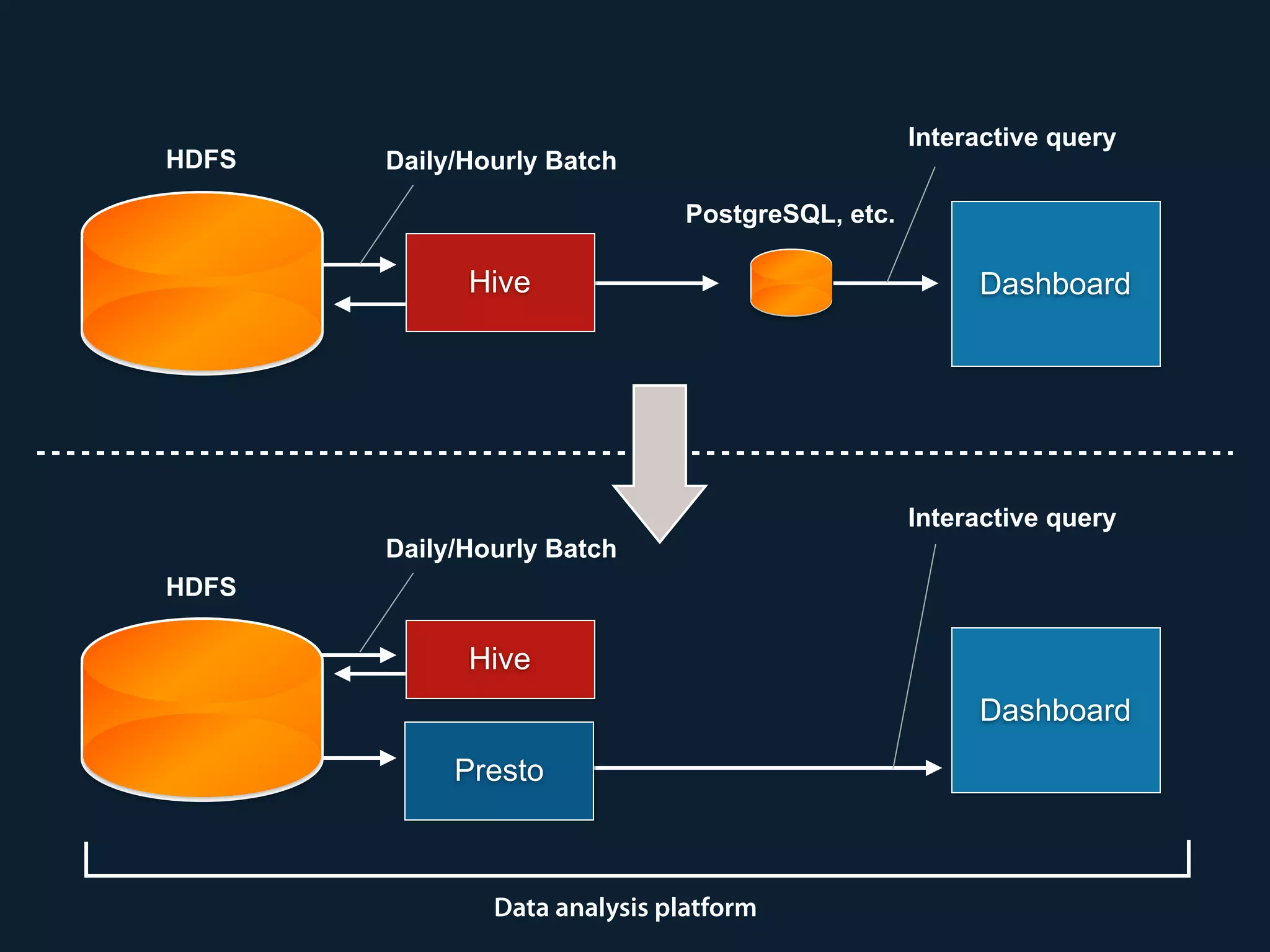
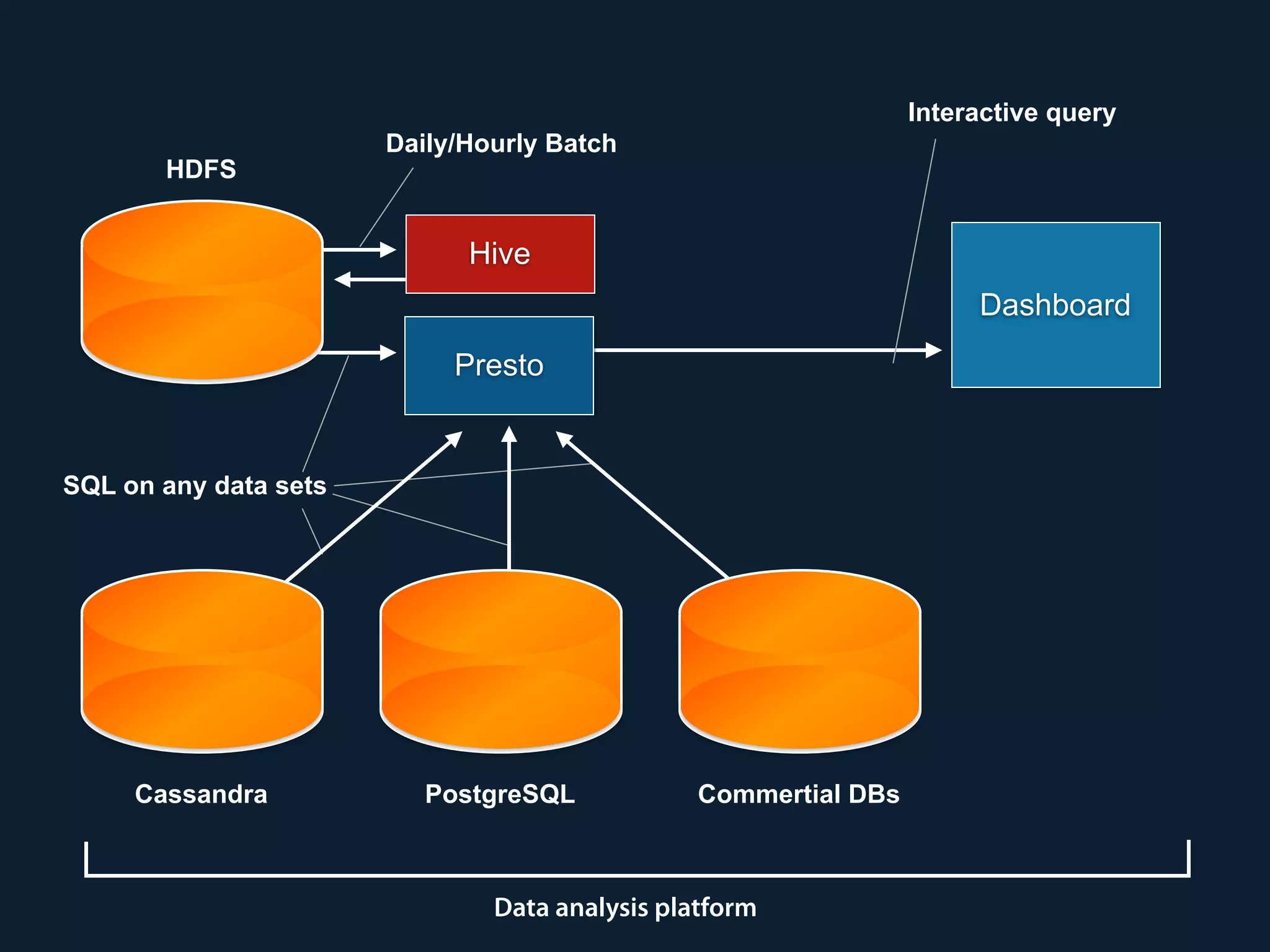
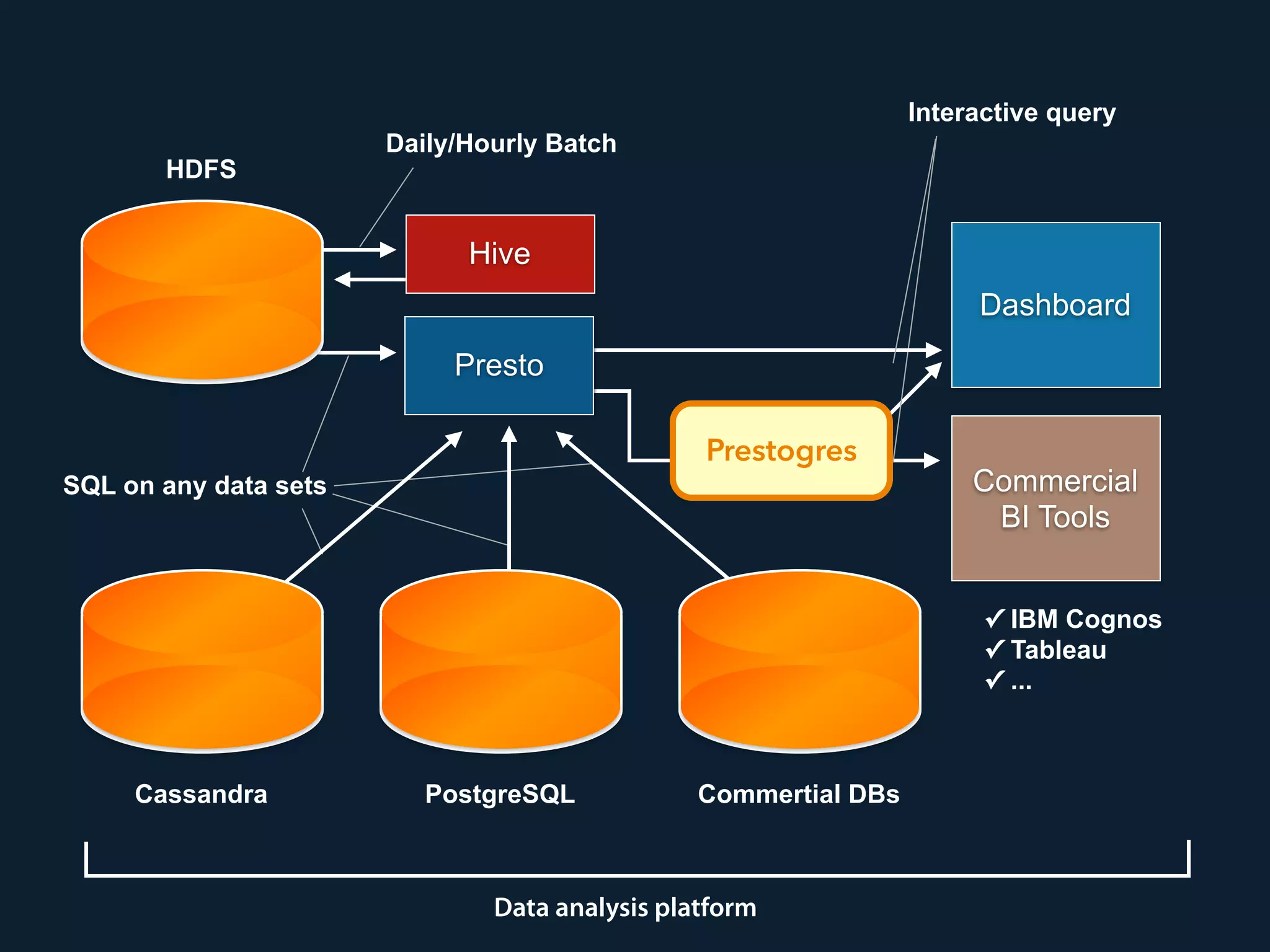
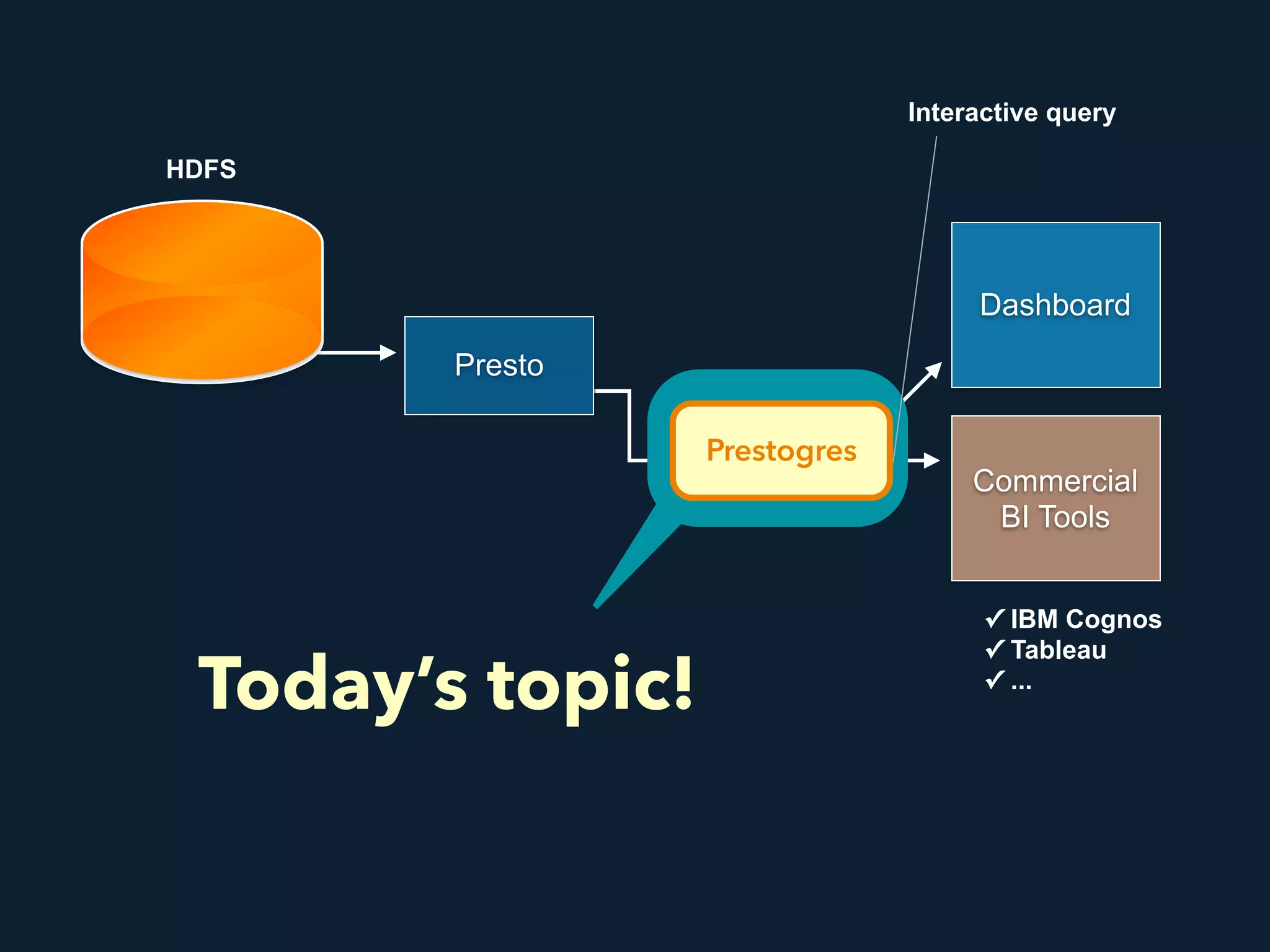









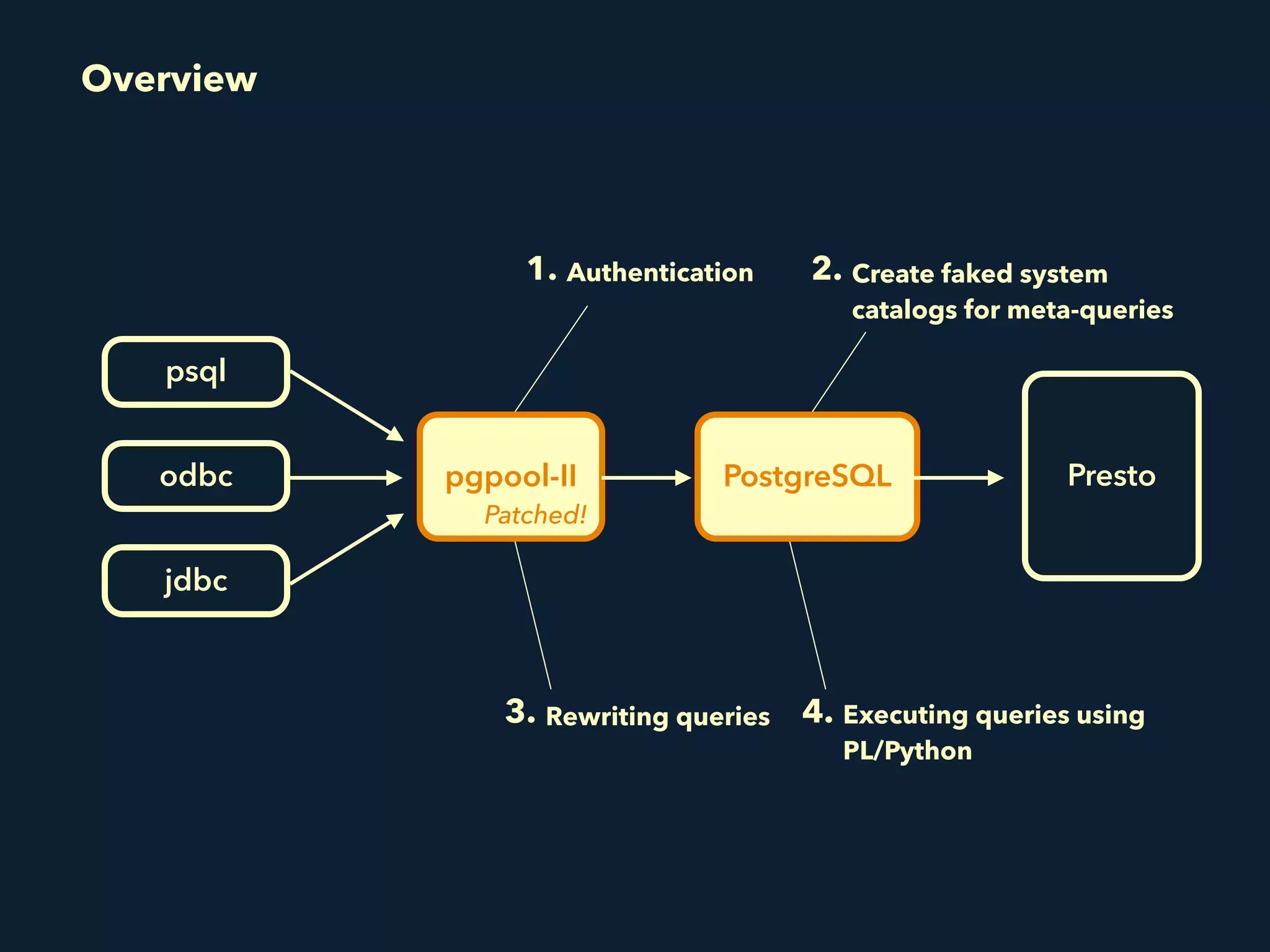
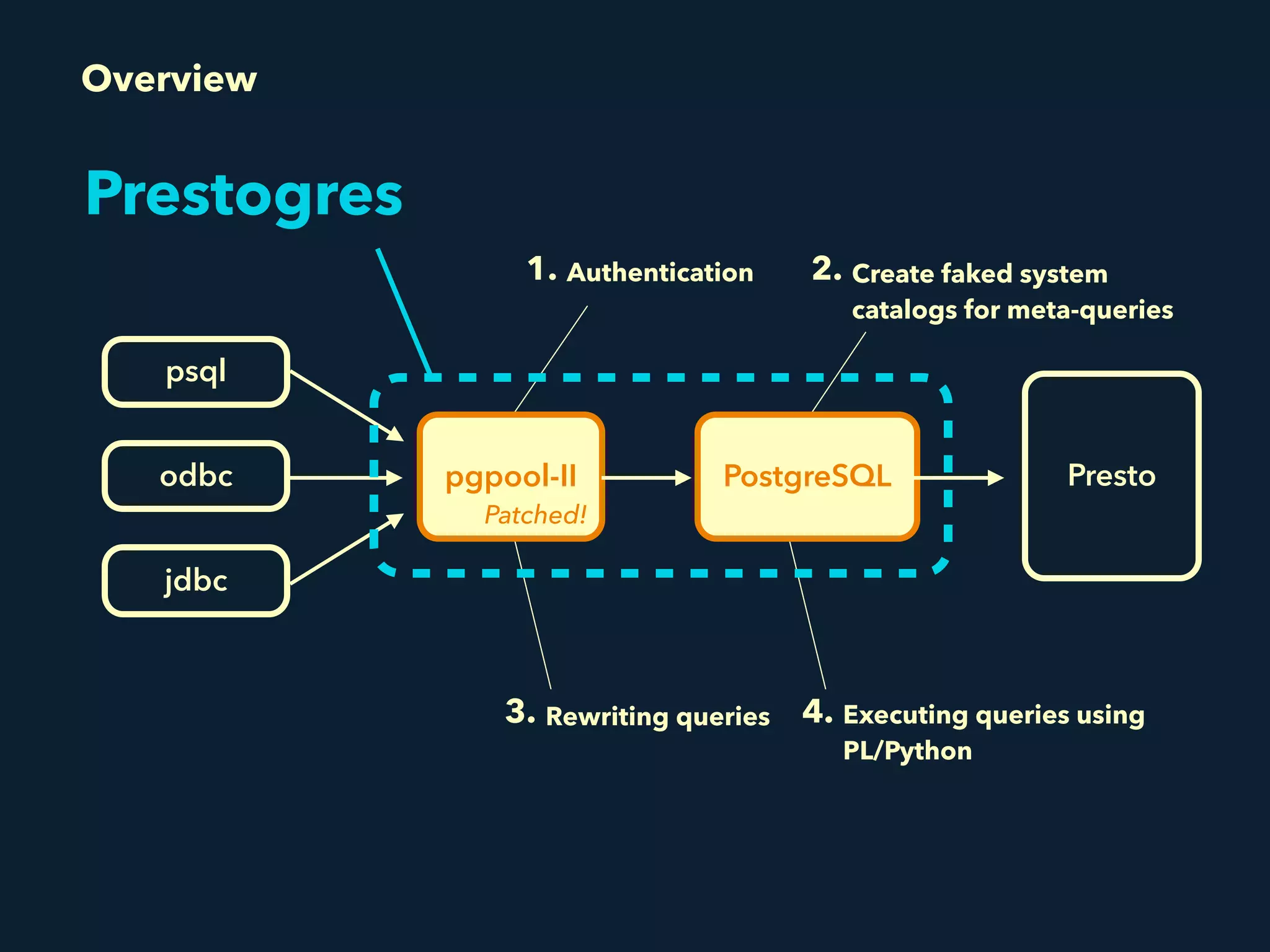
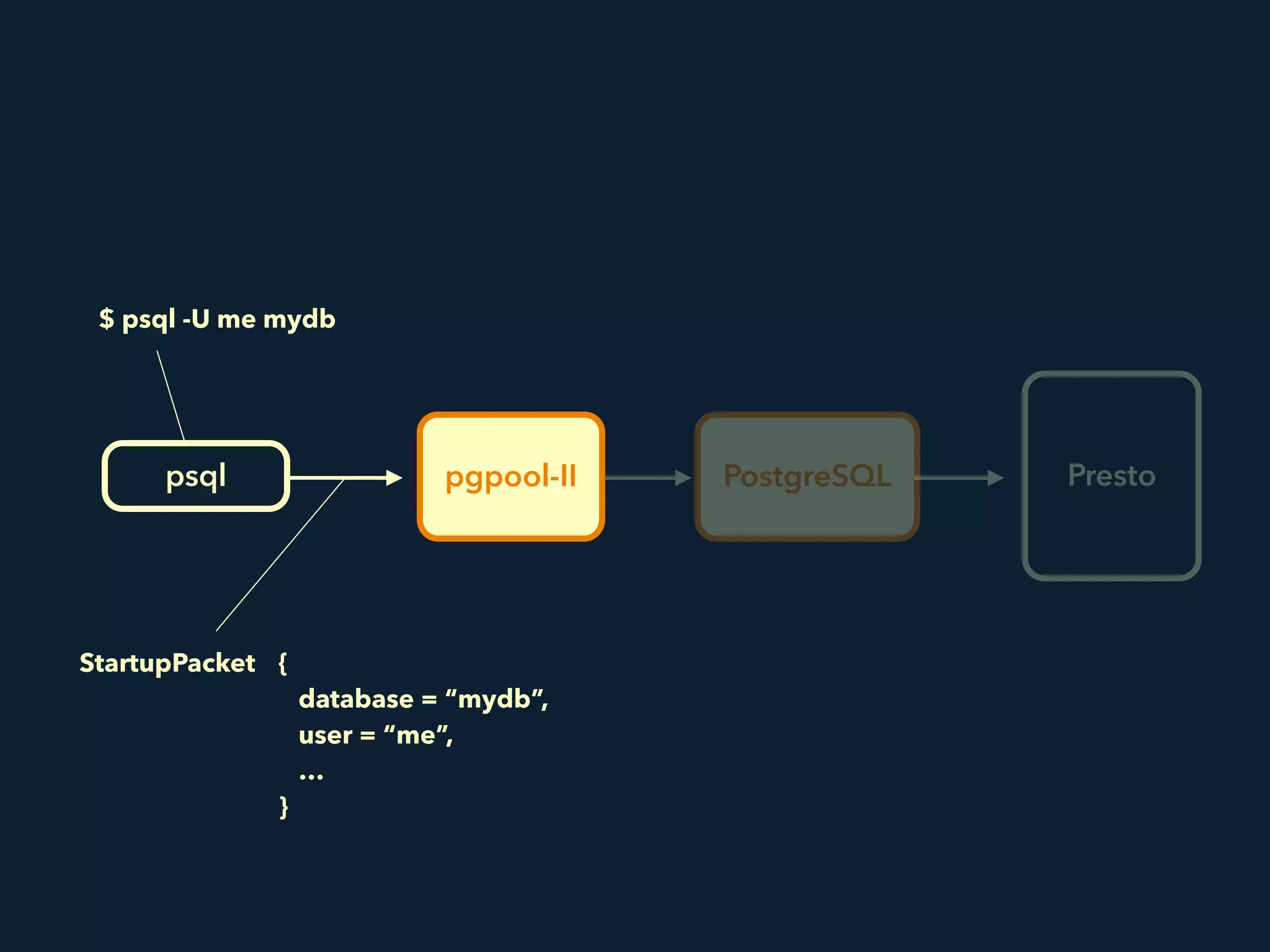
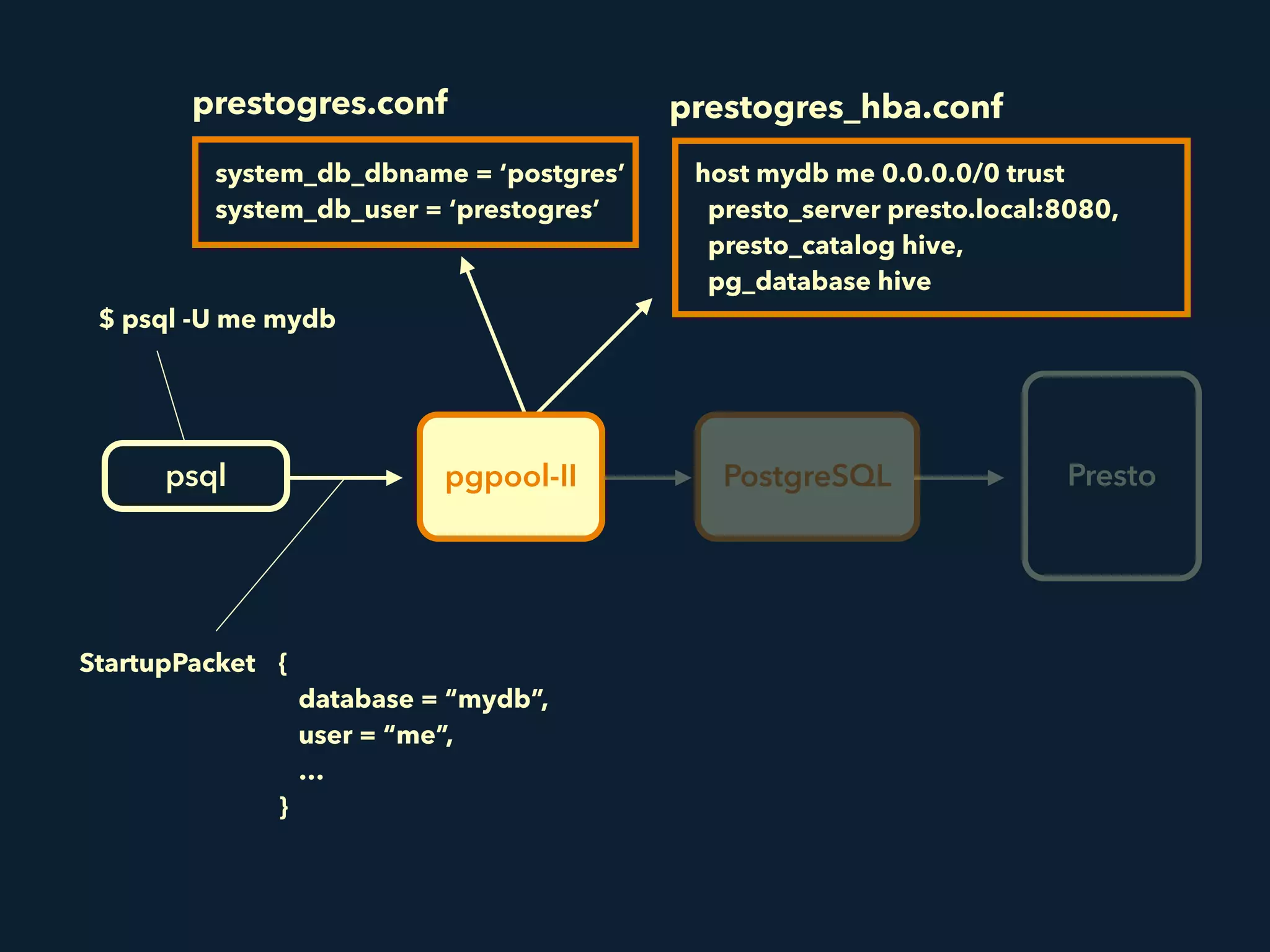
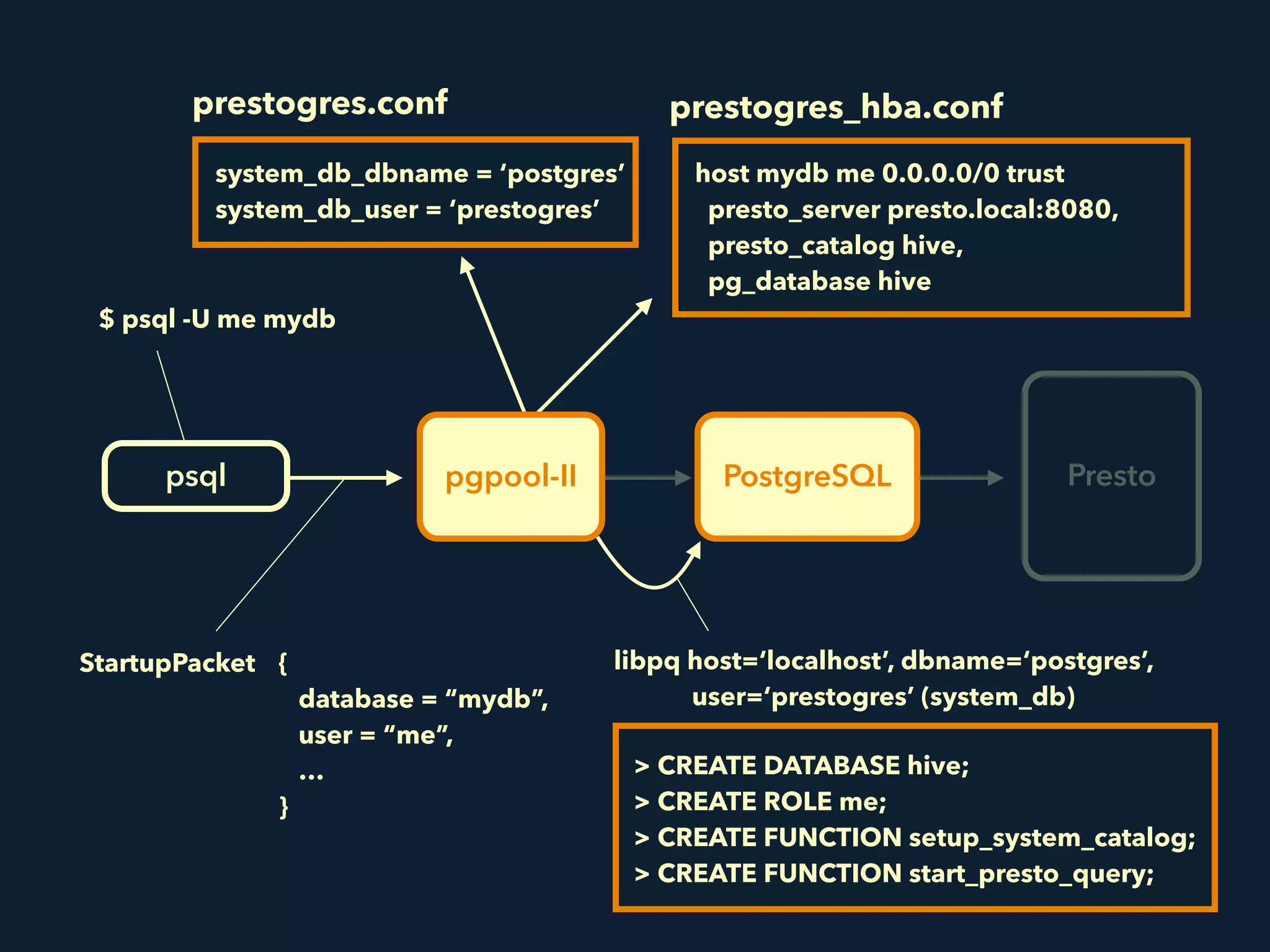
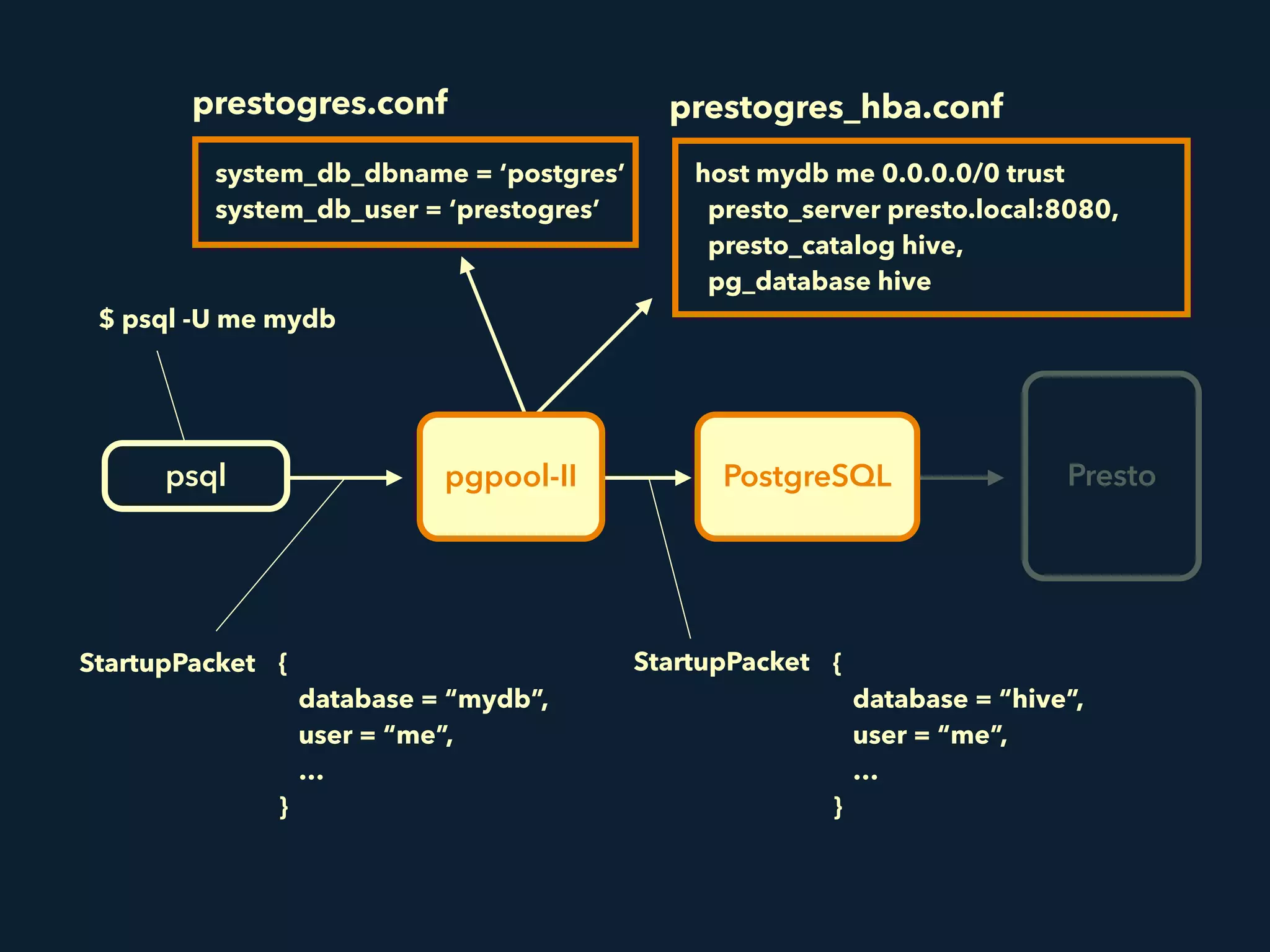
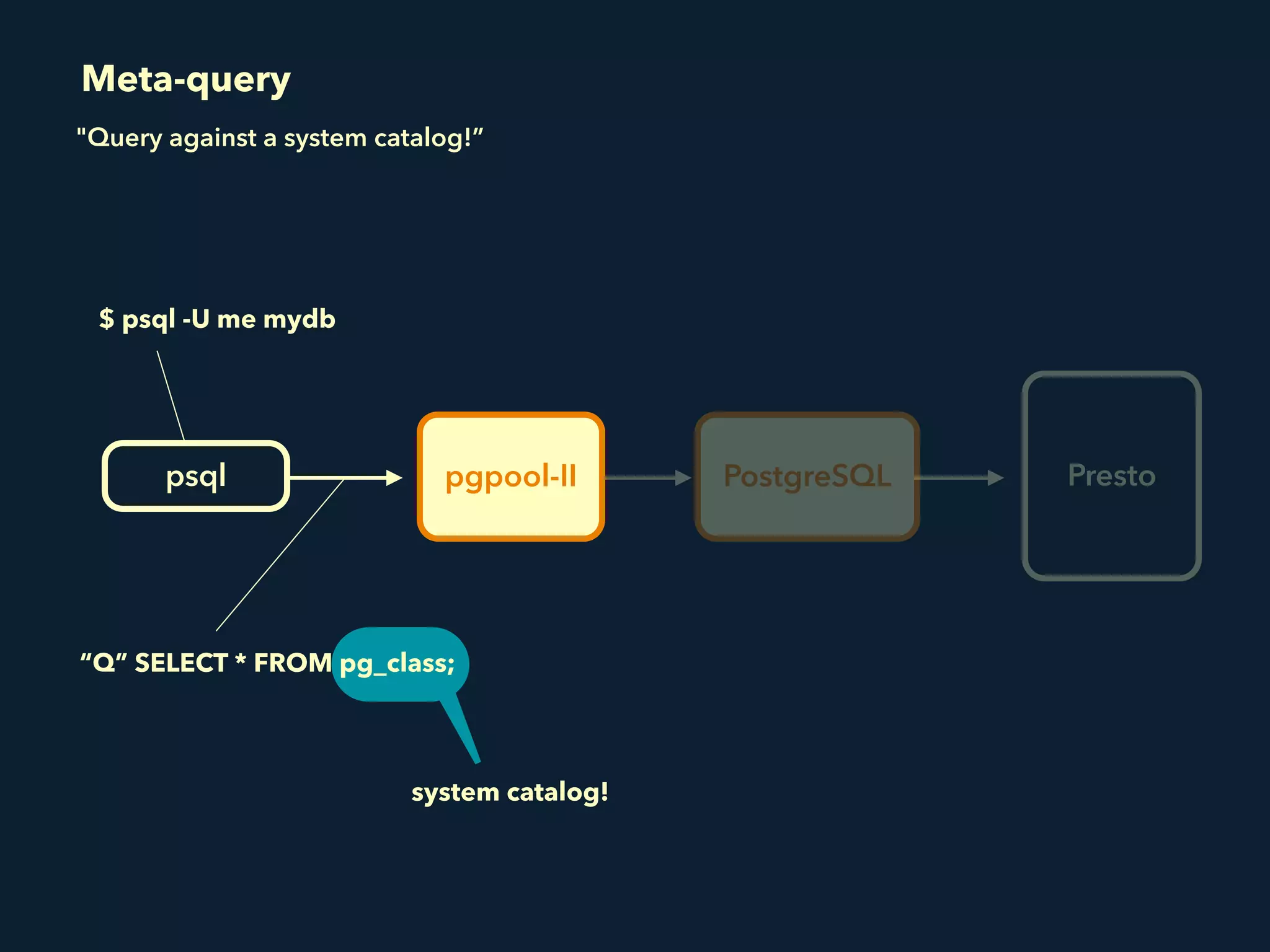
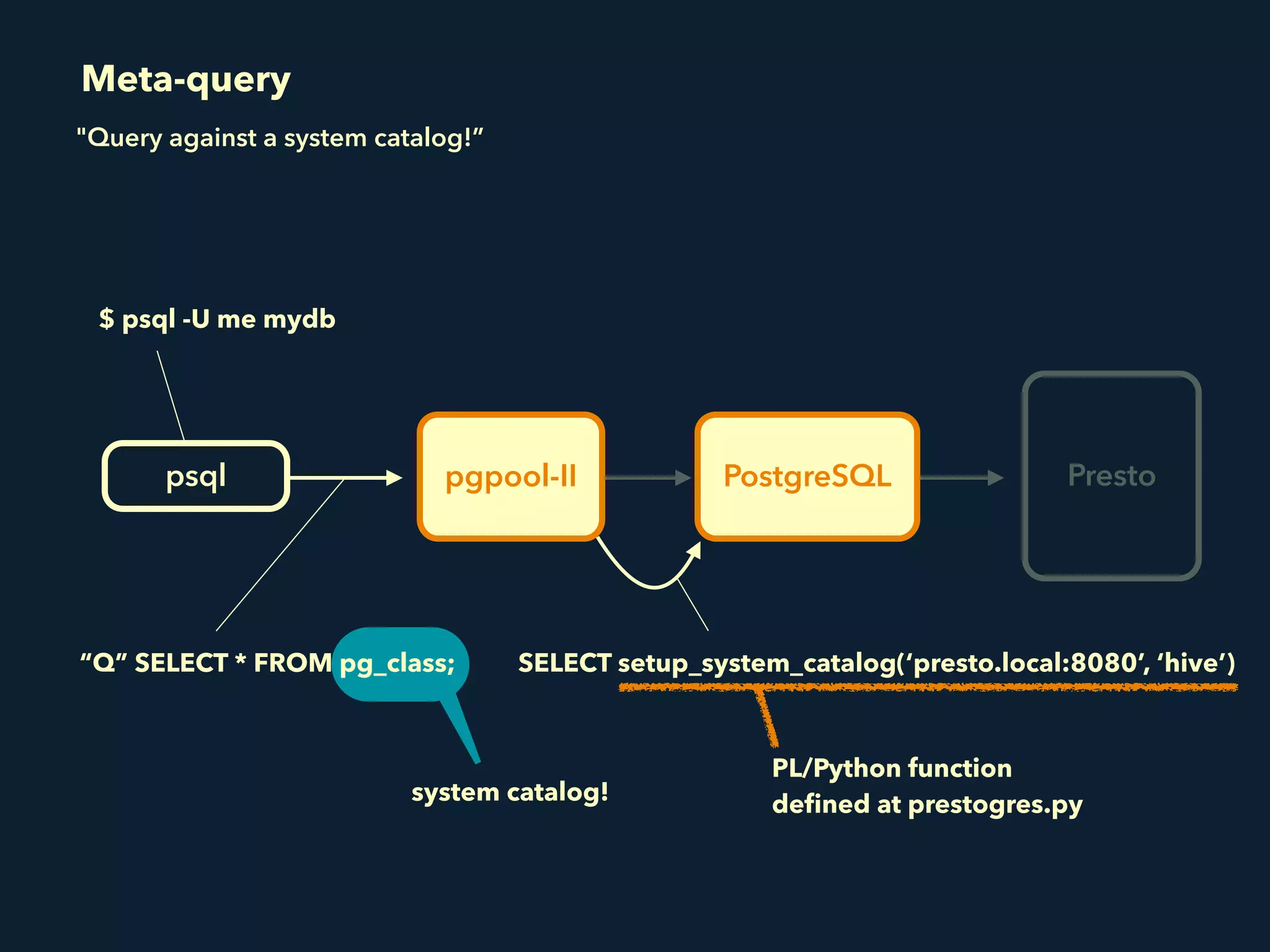
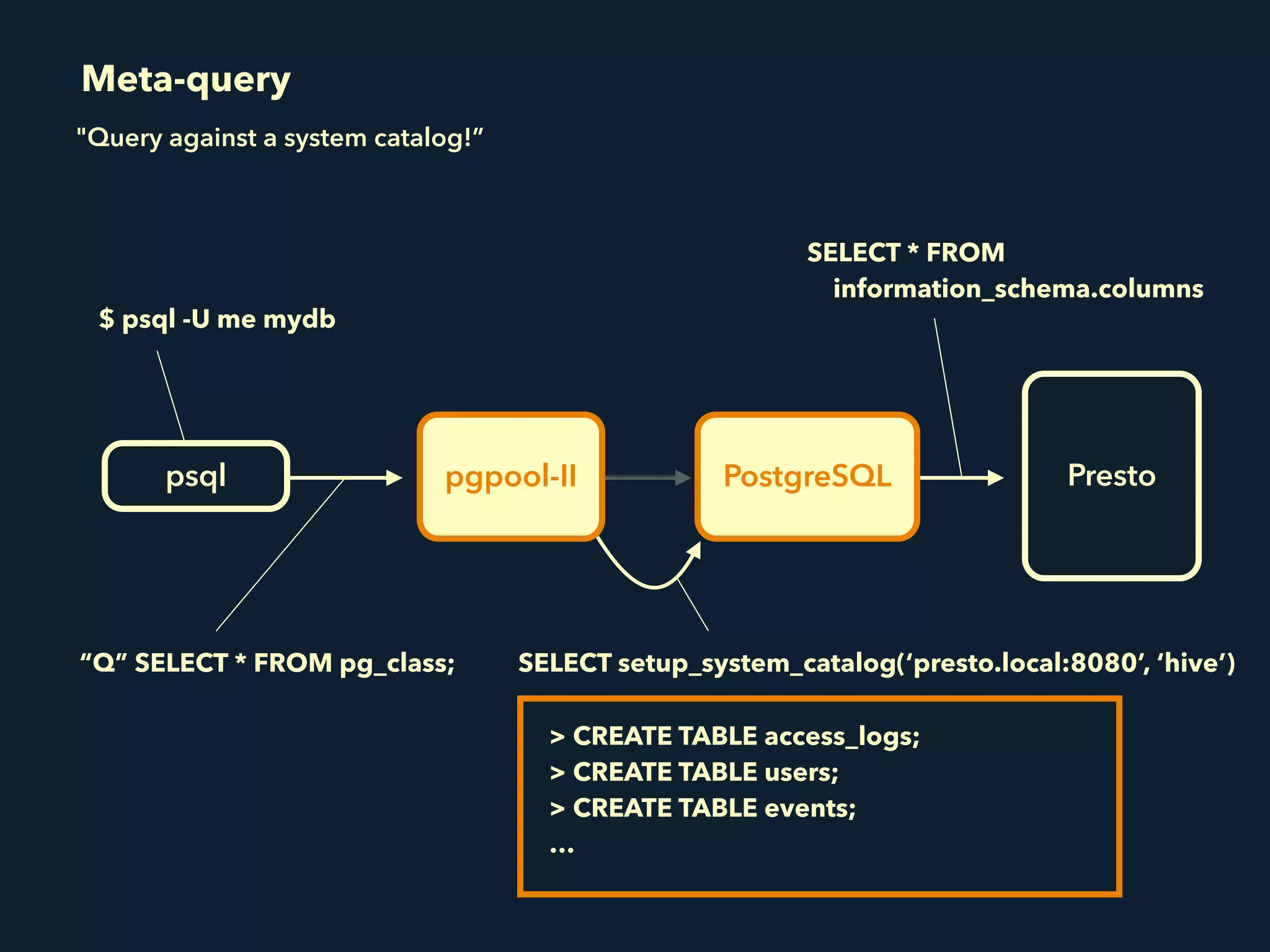
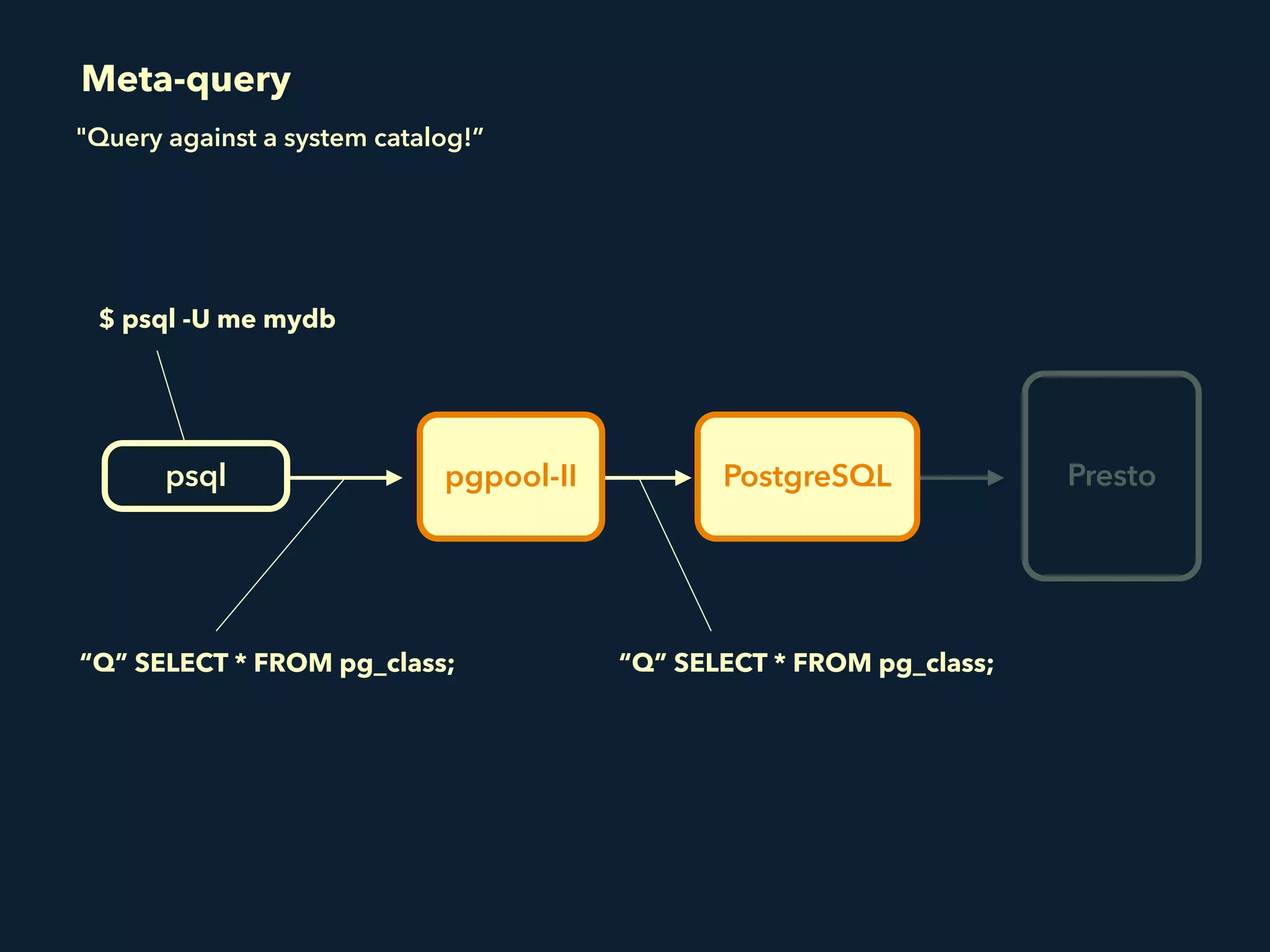
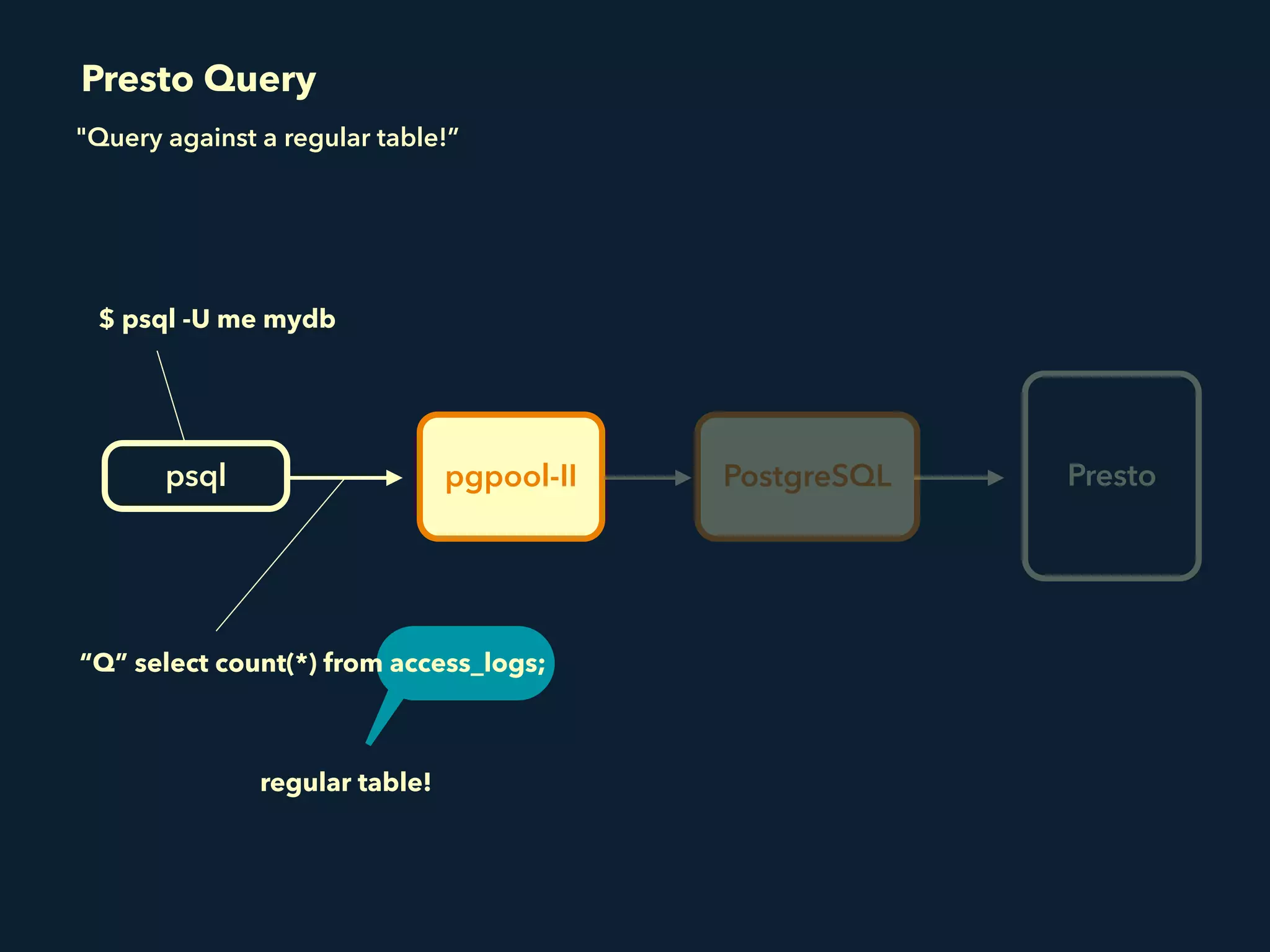
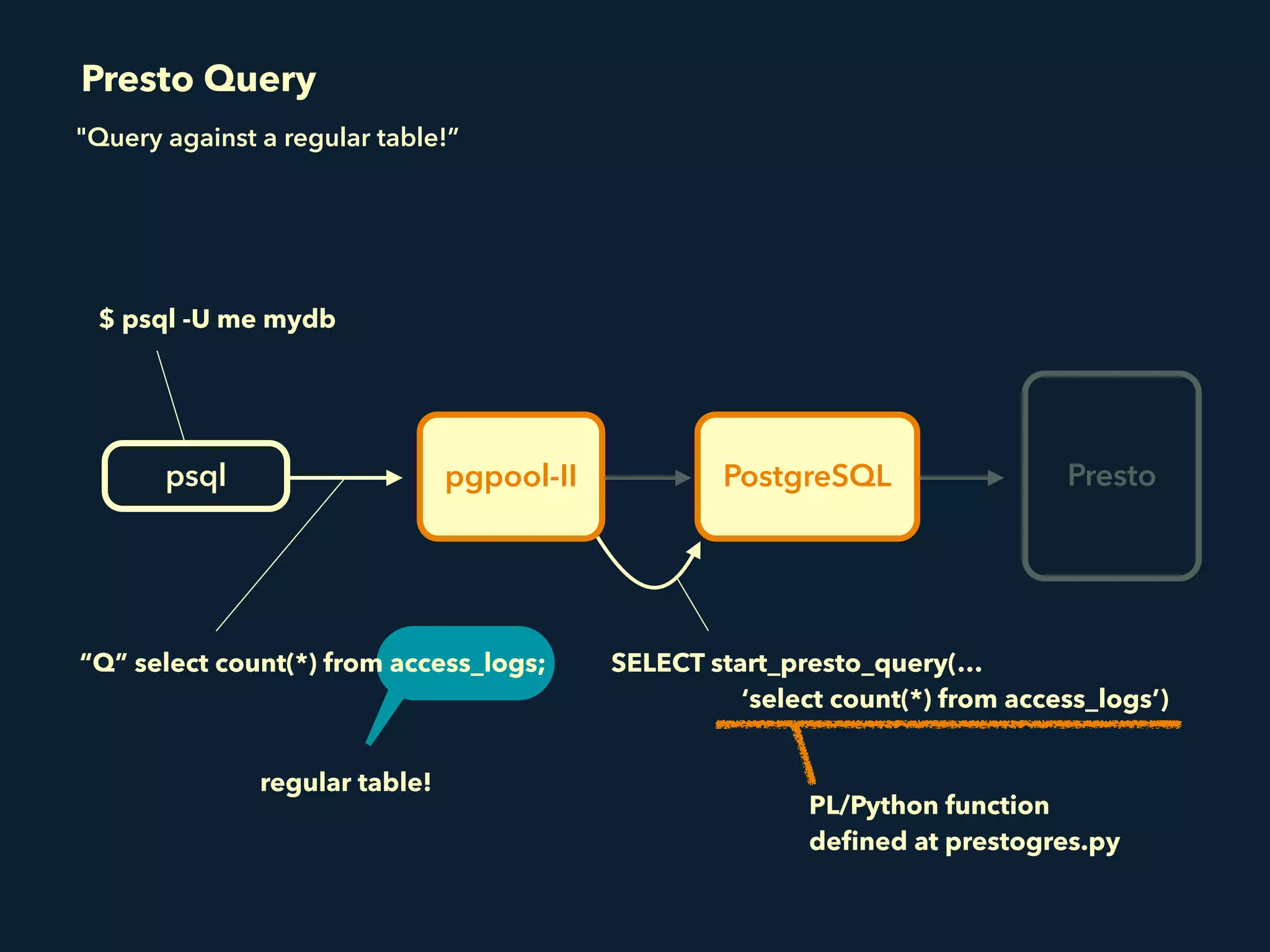
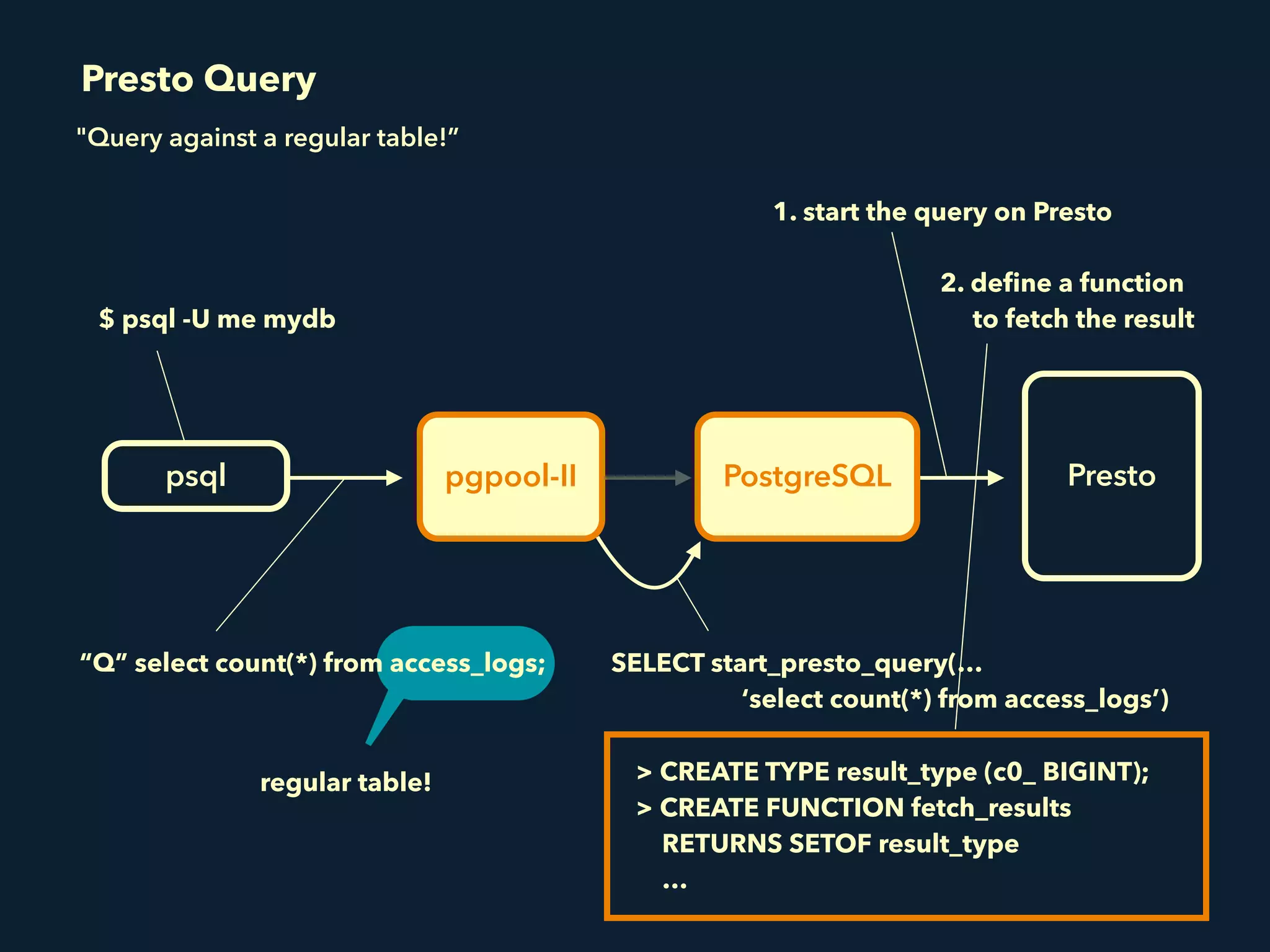
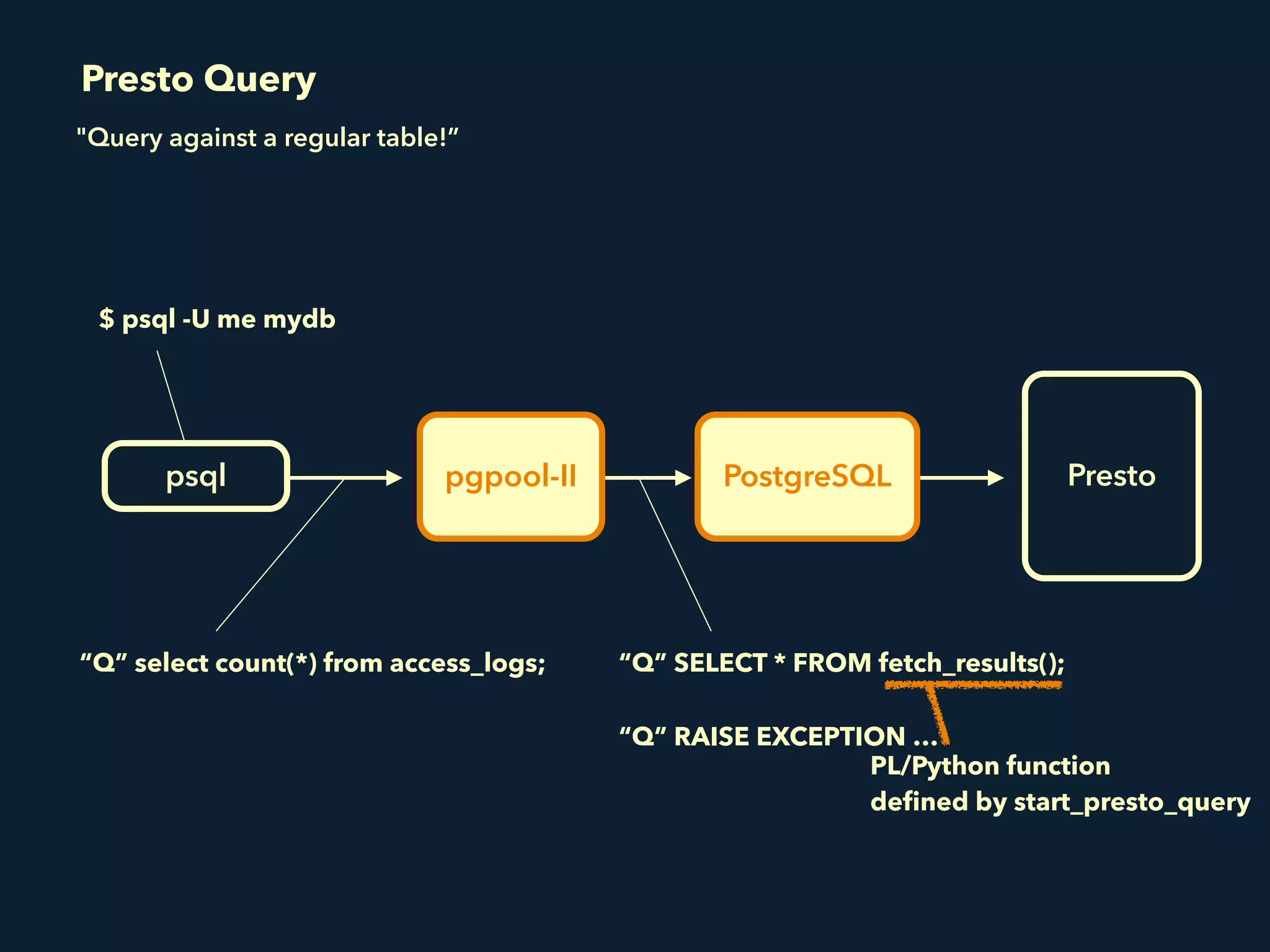


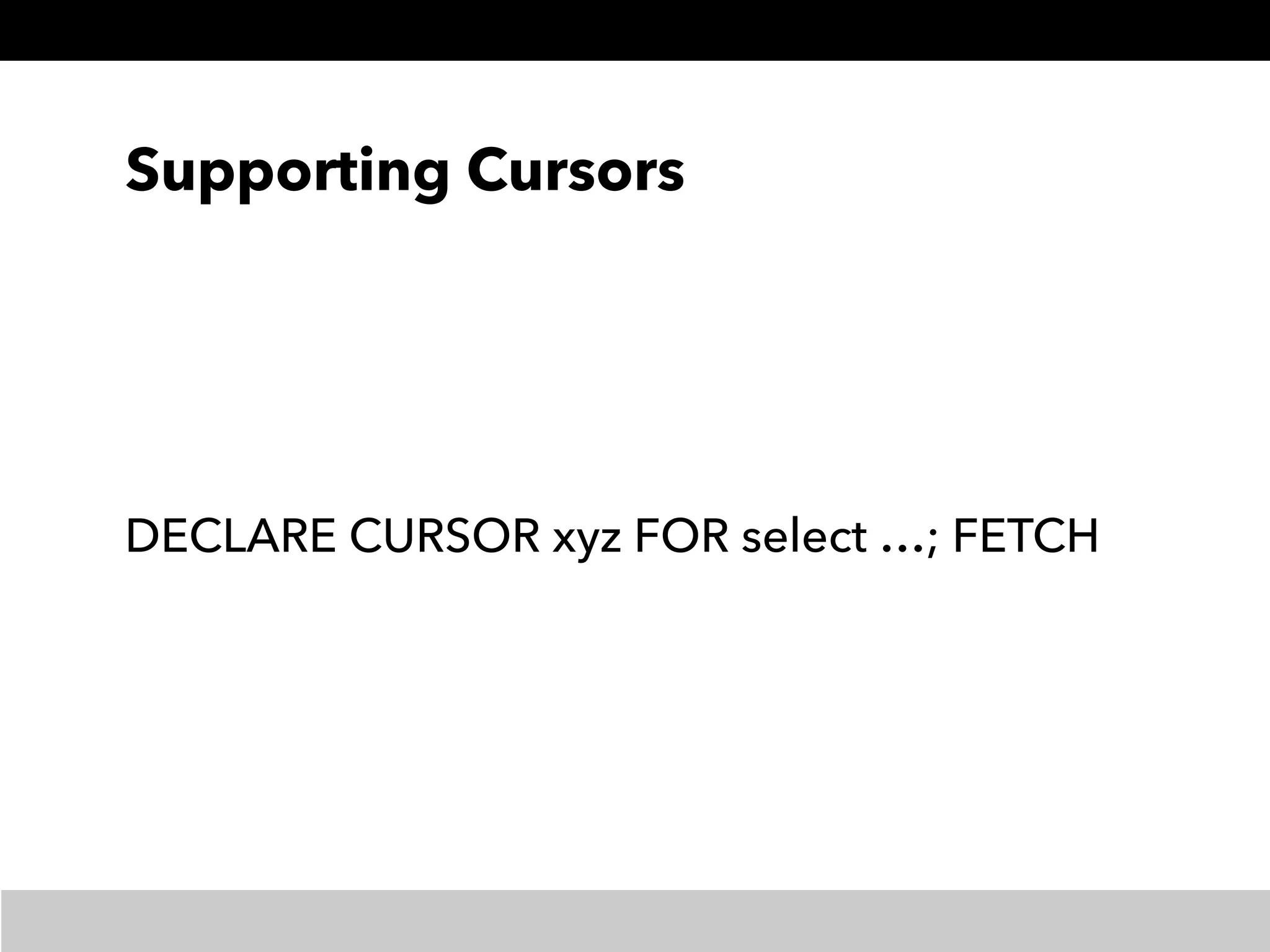









Prestogres is a PostgreSQL protocol gateway for Presto that allows Presto to be queried using standard BI tools through ODBC/JDBC. It works by rewriting queries at the pgpool-II middleware layer and executing the rewritten queries on Presto using PL/Python functions. This allows Presto to integrate with the existing BI tool ecosystem while avoiding the complexity of implementing the full PostgreSQL protocol. Key aspects of the Prestogres implementation include faking PostgreSQL system catalogs, handling multi-statement queries and errors, and security definition. Future work items include better supporting SQL syntax like casts and temporary tables.
















![[Meetup] a successful migration from elastic search to clickhouse](https://cdn.slidesharecdn.com/ss_thumbnails/meetupasuccessfulmigrationfromelasticsearchtoclickhouse-191004114403-thumbnail.jpg?width=640&height=640&fit=bounds)






































































