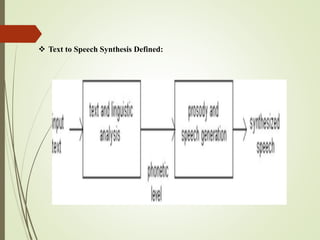
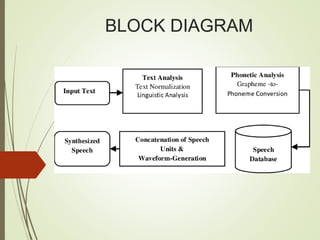
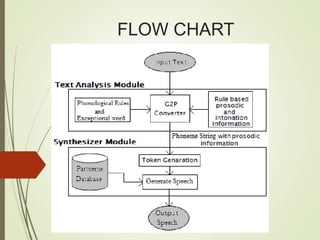
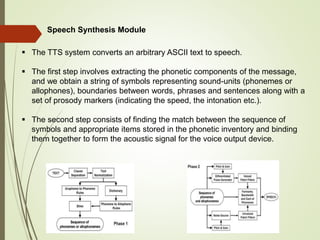
This document provides an outline and details of a student internship project on text-to-speech conversion using the Python programming language. The project was conducted at iPEC Solutions, which provides AI training and services. The student designed a text-to-speech system using tools including Praat, Audacity, and WaveSurfer. The system converts text to speech by extracting phonetic components, matching them to inventory items, and generating acoustic signals for output. The project aimed to help those with communication difficulties through improved accessibility of text-to-speech technology.















![REFERENCES:
Bailey MS, Hemmeter J. Characteristics of noninstitutionalized DI and SSI program
participants, 2010 update. 2014. [July 10, 2015].
Bainbridge K. Speech problems among US children (age 3-17 years). Washington, DC:
2015. [May 18]. (Workshop presentation to the Committee on the Evaluation of the
Supplemental Security Income (SSI) Disability Program for Children with Speech
Disorders and Language Disorders).
Campbell TF, Dollaghan CA, Rockette HE, Paradise JL, Feldman HM, Shriberg LD,
Sabo DL, Kurs-Lasky M. Risk factors for speech delay of unknown origin in 3-year-old
children. Child Development. 2003;74(2):346–357.
Clegg J, Hollis C, Mawhood L, Rutter M. Developmental language disorders—A follow-
up in later adult life. Cognitive, language and psychosocial outcomes. Journal of Child
Psychology and Psychiatry and Allied Disciplines. 2005;46(2):128–149.
Eadie P, Morgan A, Okoumunne OC, Eecen KT, Wake M, Reilly S. Speech sound
disorder at 4 years: Prevalence, comorbidities, and predictors in a community cohort of
children. Developmental Medicine & Child Neurology. 2015;57(6):578–584.](https://image.slidesharecdn.com/vishfin-221128022200-4c6fe426/85/visH-fin-pptx-20-320.jpg)




































































