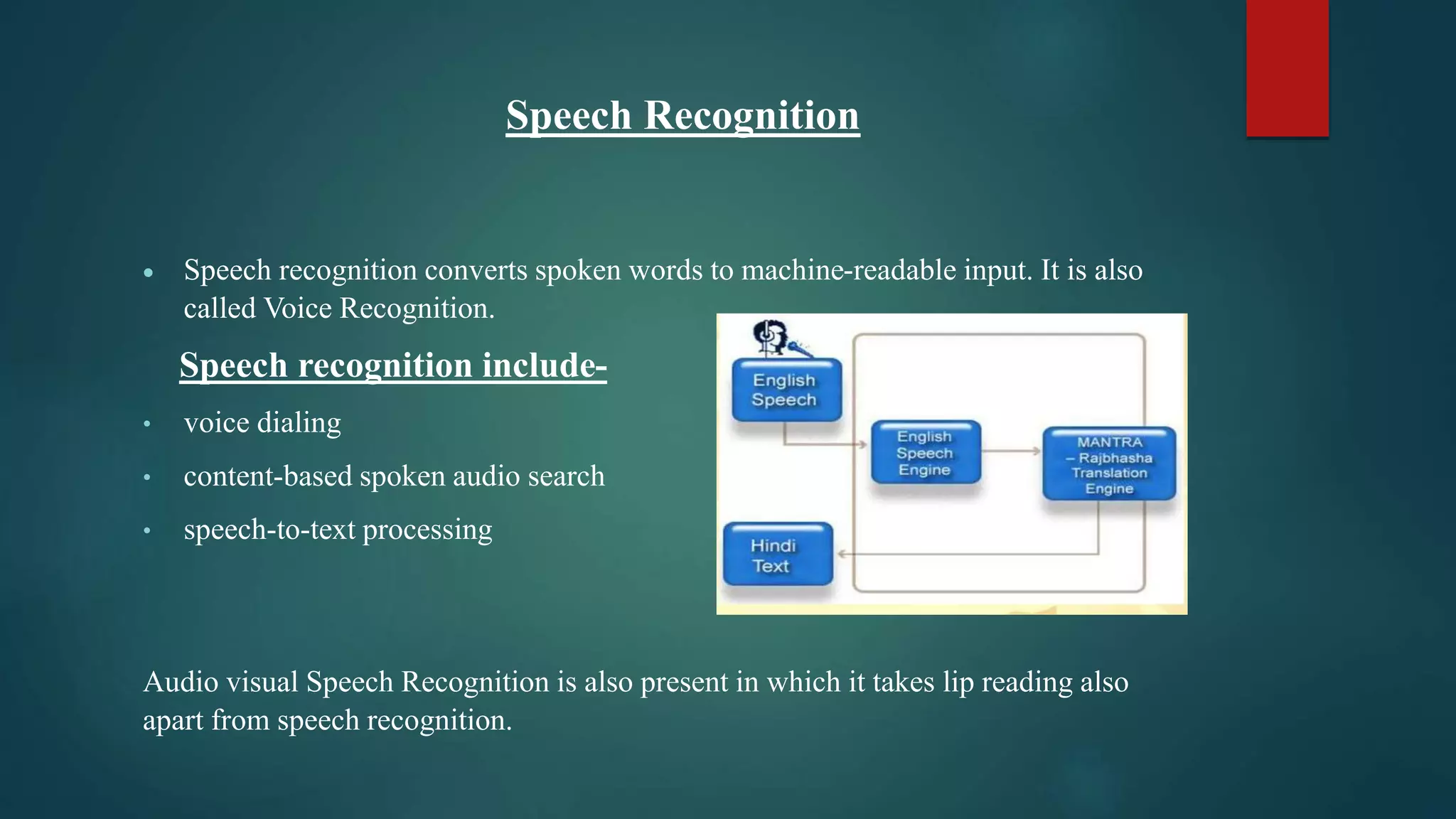
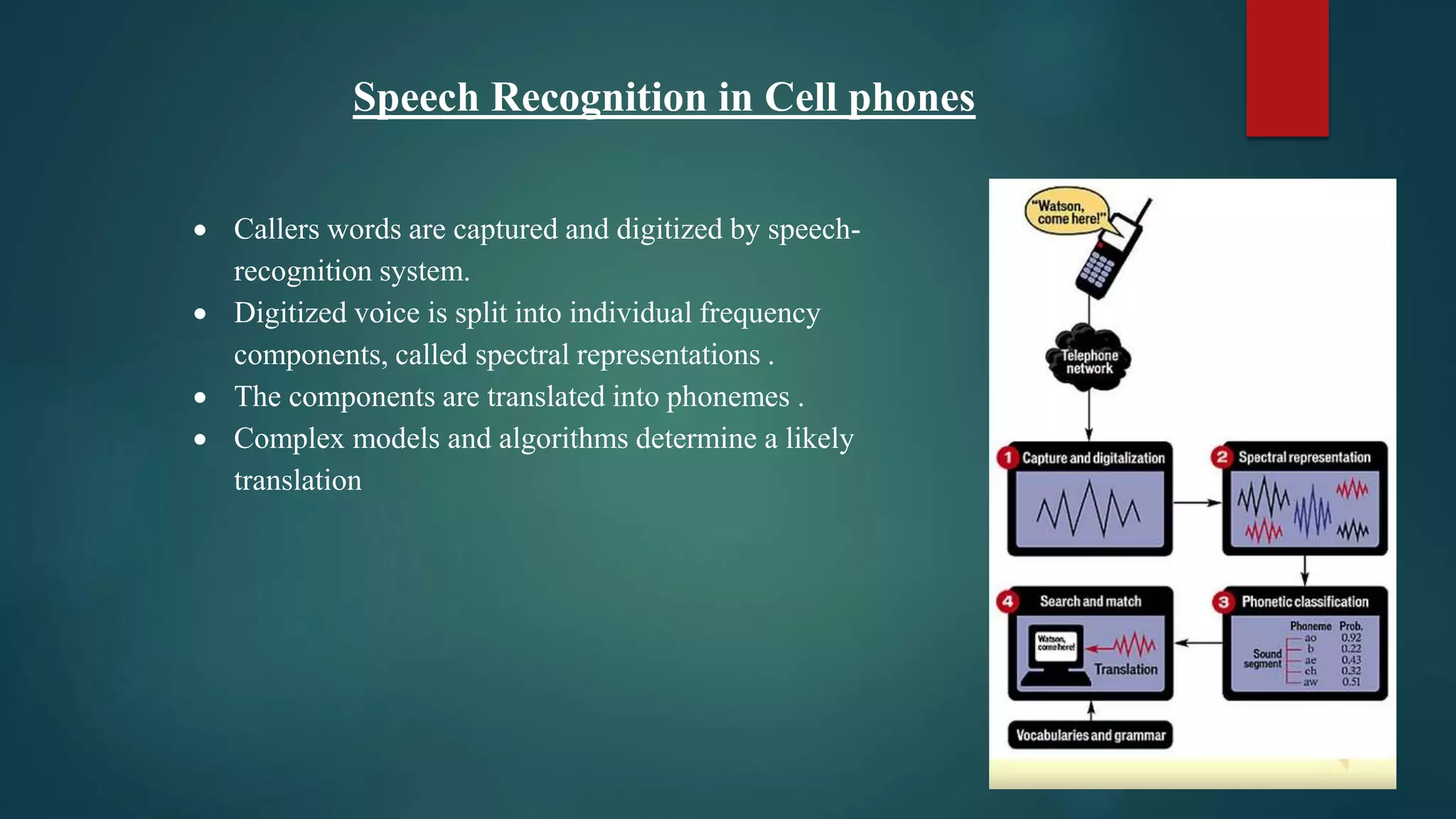
This document provides an overview of a seminar on AI for speech recognition. It includes an introduction to AI and speech recognition, different models for speech recognition including HMM and DTW, applications of speech recognition in various domains, and challenges. The content list covers topics like performance of speech recognition systems, applications, and failures of speech recognition. Statistical models are important for decoding speech accurately. AI is recognized as an efficient method for speech recognition.