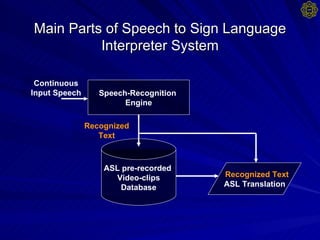
The document outlines the main parts and structure of a speech to sign language interpreter system being developed, including:
1. The system uses automatic speech recognition to convert speech to text, then matches the text to pre-recorded ASL video clips from a database for translation.
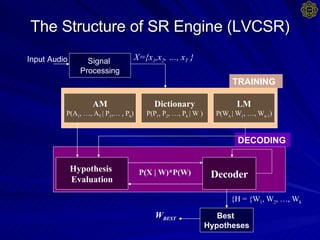
2. The speech recognition engine uses a large vocabulary, speaker independent, continuous recognition model with components like signal processing, acoustic modeling, dictionaries, and language modeling.
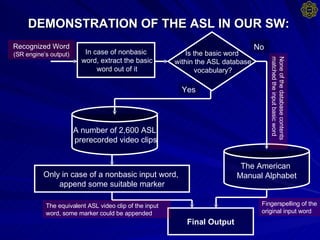
3. The document also discusses sign languages like ASL and Signed English, and provides an example of the system's demonstration translating speech to matching ASL video clips or fingerspelling if no match is found.






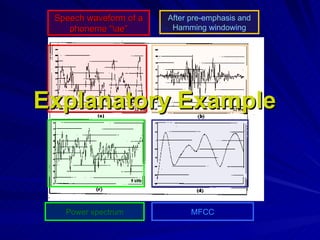
![SIGNAL PROCESSING (FRONT-END) : Pre-emphasis Framing Windowing Speech waveform y[n] y t ` [n] Power Spectrum Calculation y t [n] Mel Filterbank S t [k] ln| | 2 IDFT 13 c t [n] 13 c t [n] 13 c t [n] x[n] , 16-bits integer data S t [m] Pre-emphasis is the pre-emphasis parameter. MFCC computation: The MFCC is a representation defined as the real cepstrum of a windowed short-time signal derived from the FFT of that signal. MFCC computation consists of performing the inverse DFT on the logarithm of the magnitude of the filterbank output: TYPICALLY FOR SPEECH RECOGNITION ONLY THE FIRST 13 COEFFICIENTS ARE USED. Framing and Windowing Typical frame duration in speech recognition is 10 ms, while typical window duration is 25 ms. The mel filterbank: It is used to extract spectral features of speech through properly integrating a spectrum at defined frequency ranges. The transfer function of the triangular mel-weighting filters H m [k] is given by: The mel-spectrum of the power spectrum is computed by: where k is the DFT domain index, N is the length of the DFT, and M is total number of triangular mel-weighting filters. Power Spectrum SFT calculated using: TO reduce computational complexity, is evaluated only for a discrete number of values =2 k/N then the DFT of all frames of the signal is obtained: The phase information of the DFT samples of each frame is discarded Final output of this stage is: Delta and Double Delta computation First and Second order differences may be used to capture the dynamic evolution of the signal. The first order delta MFCC computed from: The second order delta MFCC computed from: The final output of the FE processing would comprise 39 features vector (observations vector X t ) per each processed frame.](https://image.slidesharecdn.com/speech-to-sign-language-interpreter-system4559/85/Speech-To-Sign-Language-Interpreter-System-8-320.jpg)




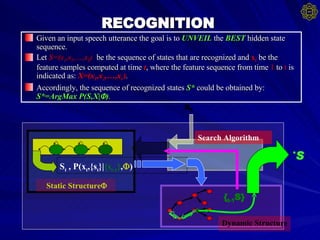
![The Veterbi Beam search Initialization: For Goto XX Recursive Step: For { Goto XX } Backtracking: XX: For Find p t (s t * )= Max[V t (i)] Calculate the threshold For { If p t (s t =j) MEMORIZE both V t (j) and path " j " Else DISCARD V t (j) } Return](https://image.slidesharecdn.com/speech-to-sign-language-interpreter-system4559/85/Speech-To-Sign-Language-Interpreter-System-15-320.jpg)











![OpenGL Mini Projects With Source Code [ Computer Graphics ]](https://cdn.slidesharecdn.com/ss_thumbnails/newmicrosoftpowerpointpresentation-180330204024-thumbnail.jpg?width=640&height=640&fit=bounds)








































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
