Downloaded 219 times
![Building a modern Application
w/ DataFrames
Meetup @ [24]7 in Campbell, CA
Sept 8, 2015](https://image.slidesharecdn.com/dataframesmeetup5-150914232035-lva1-app6891/85/Building-a-modern-Application-with-DataFrames-1-320.jpg)










![Write Less Code: Compute an Average
private IntWritable one =
new IntWritable(1)
private IntWritable output =
new IntWritable()
proctected void map(
LongWritable key,
Text value,
Context context) {
String[] fields = value.split("t")
output.set(Integer.parseInt(fields[1]))
context.write(one, output)
}
IntWritable one = new IntWritable(1)
DoubleWritable average = new DoubleWritable()
protected void reduce(
IntWritable key,
Iterable<IntWritable> values,
Context context) {
int sum = 0
int count = 0
for(IntWritable value : values) {
sum += value.get()
count++
}
average.set(sum / (double) count)
context.Write(key, average)
}
data = sc.textFile(...).split("t")
data.map(lambda x: (x[0], [x.[1], 1]))
.reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]])
.map(lambda x: [x[0], x[1][0] / x[1][1]])
.collect()
20](https://image.slidesharecdn.com/dataframesmeetup5-150914232035-lva1-app6891/85/Building-a-modern-Application-with-DataFrames-20-320.jpg)
![Write Less Code: Compute an Average
Using RDDs
data = sc.textFile(...).split("t")
data.map(lambda x: (x[0], [int(x[1]), 1]))
.reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]])
.map(lambda x: [x[0], x[1][0] / x[1][1]])
.collect()
Using DataFrames
sqlCtx.table("people")
.groupBy("name")
.agg("name", avg("age"))
.collect()
Full API Docs
• Python
• Scala
• Java
• R
21](https://image.slidesharecdn.com/dataframesmeetup5-150914232035-lva1-app6891/85/Building-a-modern-Application-with-DataFrames-21-320.jpg)




![Use DataFrames
30
# Create a new DataFrame that contains only "young" users
young = users.filter(users["age"] < 21)
# Alternatively, using a Pandas-like syntax
young = users[users.age < 21]
# Increment everybody's age by 1
young.select(young["name"], young["age"] + 1)
# Count the number of young users by gender
young.groupBy("gender").count()
# Join young users with another DataFrame, logs
young.join(log, logs["userId"] == users["userId"], "left_outer")](https://image.slidesharecdn.com/dataframesmeetup5-150914232035-lva1-app6891/85/Building-a-modern-Application-with-DataFrames-30-320.jpg)





















![Schema Inference :: Scala
57
import sqlContext.implicits._
case class Person(firstName: String,
lastName: String,
gender: String,
age: Int)
val rdd = sc.textFile("people.csv")
val peopleRDD = rdd.map { line =>
val cols = line.split(",")
Person(cols(0), cols(1), cols(2), cols(3).toInt)
}
val df = peopleRDD.toDF
// df: DataFrame = [firstName: string, lastName: string,
gender: string, age: int]](https://image.slidesharecdn.com/dataframesmeetup5-150914232035-lva1-app6891/85/Building-a-modern-Application-with-DataFrames-57-320.jpg)




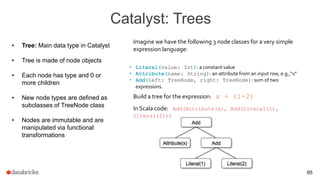



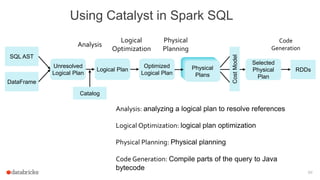
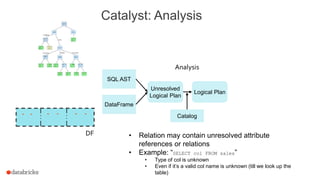
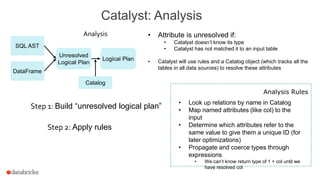

![Catalyst: Logical Optimizations
73
Logical Plan
Optimized
Logical Plan
Logical
Optimization • Applies rule-based optimizations to the logical
plan:
• Constant folding
• Predicate pushdown
• Projection pruning
• Null propagation
• Boolean expression simplification
• [Others]
• Example: a 12-line rule optimizes LIKE
expressions with simple regular expressions
into String.startsWith or String.contains calls.](https://image.slidesharecdn.com/dataframesmeetup5-150914232035-lva1-app6891/85/Building-a-modern-Application-with-DataFrames-73-320.jpg)







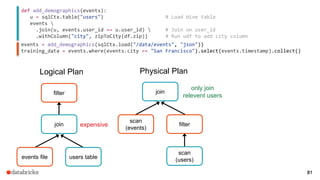
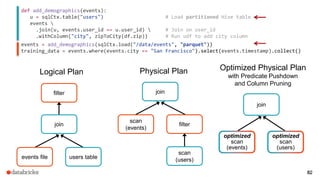
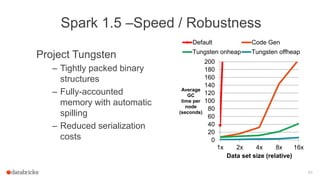





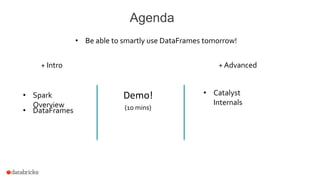
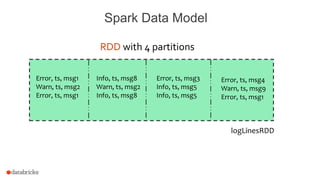
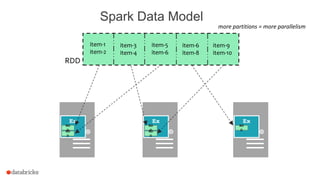
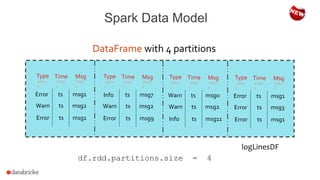
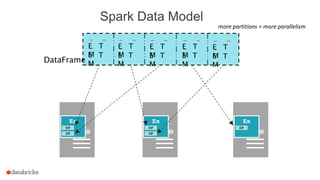
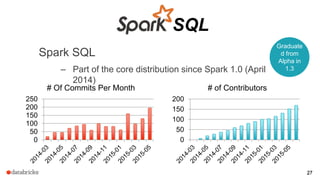
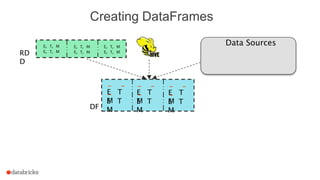
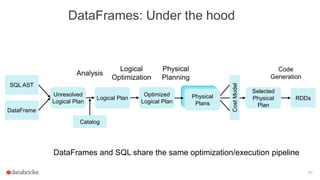
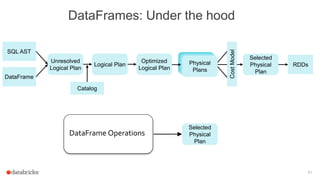
The document discusses a meetup about building modern applications with DataFrames in Spark. It provides an agenda for the meetup that includes an introduction to Spark and DataFrames, a discussion of the Catalyst internals, and a demo. The document also provides background on Spark, noting its open source nature and large-scale usage by many organizations.
























































































![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Srdj Stanisic - Local and Private AI in UX.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vwmetykqmztgmokmmkfa-3-srdjan-stanisic-local-and-small-ai-in-ux-260120105855-55a31869-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Marcos Heidemann - Beyond the Hype: Making AI Coding Assistan...](https://cdn.slidesharecdn.com/ss_thumbnails/eexkhvldrjsopspdjbur-marcos-heidemann-beyond-the-hype-getting-real-value-out-of-ai-assisted-coding-260121115910-7e9d41ec-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tali Fulman - Guild Meetings, Then What? Building Data Commun...](https://cdn.slidesharecdn.com/ss_thumbnails/fgohhi33rwmhqdowdj5k-tali-fulman-guild-meetings-then-what-building-data-communities-that-actually-ch-260120105855-528492c3-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)
