Download to read offline






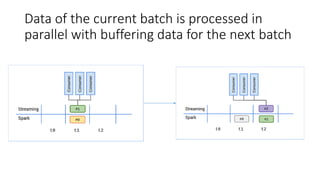



Spark streaming provides stream processing functionality as an abstraction over core Spark. It processes data in micro-batches, where streaming data is buffered for a given interval and then processed as RDDs by core Spark. The processing time of each micro-batch must be less than the batch interval to avoid bottlenecks. Performance can be tuned by parallelizing data consumption from sources like Kafka, and balancing Spark partitions for parallel processing with available cores.














































































