








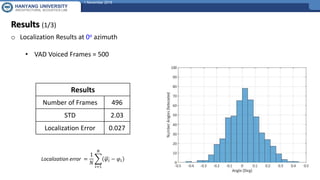
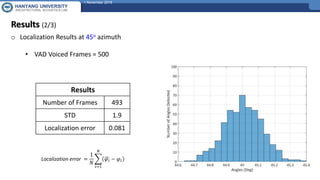
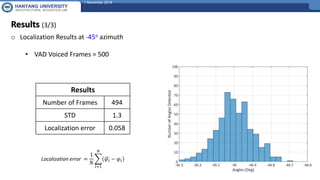


The document presents a framework for sound source localization using six-channel spherical microphone arrays, focusing on the steered-response power (SRP) method optimized with Minimum Variance Distortionless Response (MVDR) and phase transform (PHAT) weighting. It outlines the methodology, real-time implementation, and evaluation results, indicating successful localization within an accuracy of ±2 degrees at a signal-to-noise ratio of 15 dB. Additionally, the use of voice activity detection (VAD) and a clustering approach improves the precision of tracking multiple sound sources in reverberant environments.









![3_Antenna Array [Modlue 4] (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/3antennaarraymodlue41-220419112111-thumbnail.jpg?width=640&height=640&fit=bounds)


























































