Downloaded 12 times

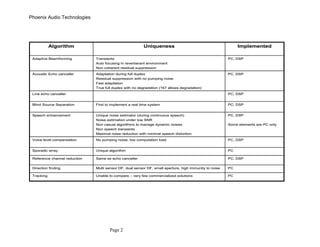











Phoenix Audio Technologies offers a diverse range of algorithms to extract desired audio signals from noisy environments and improve audio clarity. Their solutions include multi-sensor processing, adaptive beamforming, echo cancellation, and single sensor speech enhancement, designed to address various challenges in real-time audio processing. The document details the features, maturity, and specific use cases of these algorithms, showcasing their effectiveness in both operated and experimental environments.





















































































