Download as KEY, PPTX







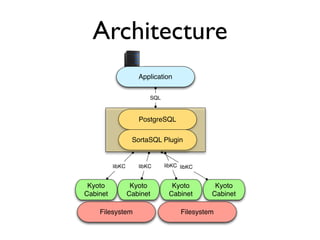











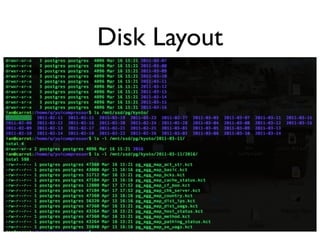
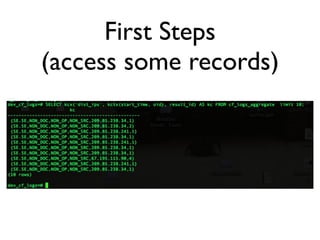


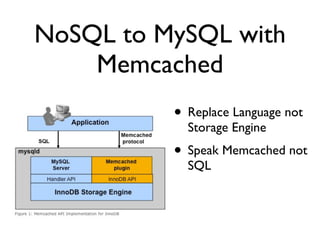


SortaSQL is a proposal to add seamless horizontal scalability to SQL databases by using the filesystem to store and retrieve data. The SQL database would store metadata and handle queries, while an embedded key-value store manages record storage on files in the local or distributed filesystem. This allows queries to scale across many servers by letting the filesystem handle replication, performance and locking of distributed data files. The architecture involves an application communicating with PostgreSQL over SQL, which uses a SortaSQL plugin to retrieve rows from Kyoto Cabinet key-value files on the POSIX filesystem. Case studies at CloudFlare show how a 400GB per day dataset can be efficiently stored and queried at scale using this approach.











































































































