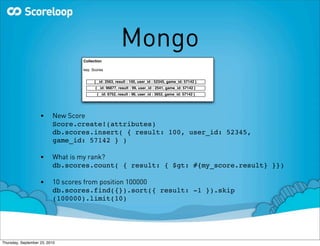
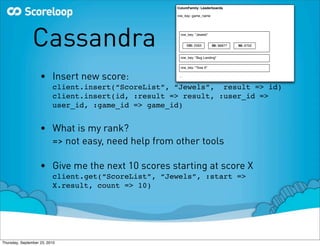
The document discusses evaluating different NoSQL databases to replace a PostgreSQL database that is expected to become a performance bottleneck due to high volume growth that is unpredictable and non-linear. It summarizes the criteria for the NoSQL solution, including the ability to scale horizontally, good performance for Ruby, and active development. Several NoSQL databases are evaluated, including MongoDB, Redis, Cassandra, HBase, and Membase. MongoDB, Redis, and Cassandra are discussed in more detail regarding experiences and performance.