Download as PDF, PPTX
























![Thinking About Your Data (MongoDB)
from pymongo import Connection
connection = Connection()
db = connection['blog']
posts = db['posts']
post = {"author": "Lorraine",
"title": "Who on Earth lets Chris Lea Talk on Stage?",
"post": "Seriously. That's just not cool.",
"comments": ["Is he really that bad?", "Yes, he really is."],
"date": datetime.datetime.utcnow()}
posts.insert(post)](https://image.slidesharecdn.com/fowadublin2010nosql-100526105440-phpapp02/75/Chris-Lea-What-does-NoSQL-Mean-for-You-27-2048.jpg)
![Thinking About Your Data (MongoDB)
from pymongo import Connection
connection = Connection()
db = connection['blog']
posts = db['posts']
post = posts.find_one({“author”: “Lorraine”})](https://image.slidesharecdn.com/fowadublin2010nosql-100526105440-phpapp02/75/Chris-Lea-What-does-NoSQL-Mean-for-You-28-2048.jpg)
![Say Goodbye to Schemas
from pymongo import Connection
connection = Connection()
db = connection['blog']
posts = db['posts']
post = {"author": "Lorraine",
"title": "Who on Earth lets Chris Lea Talk on Stage?",
"post": "Seriously. That's just not cool.",
"comments": ["Is he really that bad?", "Yes, he really is."],
"date": datetime.datetime.utcnow()}
posts.insert(post)](https://image.slidesharecdn.com/fowadublin2010nosql-100526105440-phpapp02/75/Chris-Lea-What-does-NoSQL-Mean-for-You-29-2048.jpg)
![Say Goodbye to Schemas
from pymongo import Connection
connection = Connection()
db = connection['blog']
posts = db['posts']
post = {"author": "Lorraine",
"title": "Who on Earth lets Chris Lea Talk on Stage?",
"post": "Seriously. That's just not cool.",
"comments": ["Is he really that bad?", "Yes, he really is."],
"tags": ["fowa", "nosql", "nerds"],
"date": datetime.datetime.utcnow()}
posts.insert(post)](https://image.slidesharecdn.com/fowadublin2010nosql-100526105440-phpapp02/75/Chris-Lea-What-does-NoSQL-Mean-for-You-30-2048.jpg)
![Say Goodbye to Schemas
from pymongo import Connection
connection = Connection()
db = connection['blog']
If you want new fields... just start
posts = db['posts'] using them!
post = {"author": "Lorraine",
"title": "Who on Earth lets Chris Lea Talk on Stage?",
"post": "Seriously. That's just not cool.",
"comments": ["Is he really that bad?", "Yes, he really is."],
"tags": ["fowa", "nosql", "nerds"],
"date": datetime.datetime.utcnow()}
posts.insert(post)](https://image.slidesharecdn.com/fowadublin2010nosql-100526105440-phpapp02/75/Chris-Lea-What-does-NoSQL-Mean-for-You-31-2048.jpg)
![Enjoy a Wealth of Query Options
from pymongo import Connection
connection = Connection()
db = connection['blog']
posts = db['posts']
posts.find_one({“author”: “Lorraine”})](https://image.slidesharecdn.com/fowadublin2010nosql-100526105440-phpapp02/75/Chris-Lea-What-does-NoSQL-Mean-for-You-32-2048.jpg)
![Enjoy a Wealth of Query Options
from pymongo import Connection
connection = Connection()
db = connection['blog']
posts = db['posts']
posts.find({“author”: “Lorraine”}).limit(5)](https://image.slidesharecdn.com/fowadublin2010nosql-100526105440-phpapp02/75/Chris-Lea-What-does-NoSQL-Mean-for-You-33-2048.jpg)
![Enjoy a Wealth of Query Options
from pymongo import Connection
connection = Connection()
db = connection['blog']
posts = db['posts']
posts.find({“author”: /^Lor/})](https://image.slidesharecdn.com/fowadublin2010nosql-100526105440-phpapp02/75/Chris-Lea-What-does-NoSQL-Mean-for-You-34-2048.jpg)
![Enjoy a Wealth of Query Options
from pymongo import Connection
connection = Connection()
db = connection['blog']
posts = db['posts']
posts.find({“author”: {$not: “Lorraine”} })](https://image.slidesharecdn.com/fowadublin2010nosql-100526105440-phpapp02/75/Chris-Lea-What-does-NoSQL-Mean-for-You-35-2048.jpg)






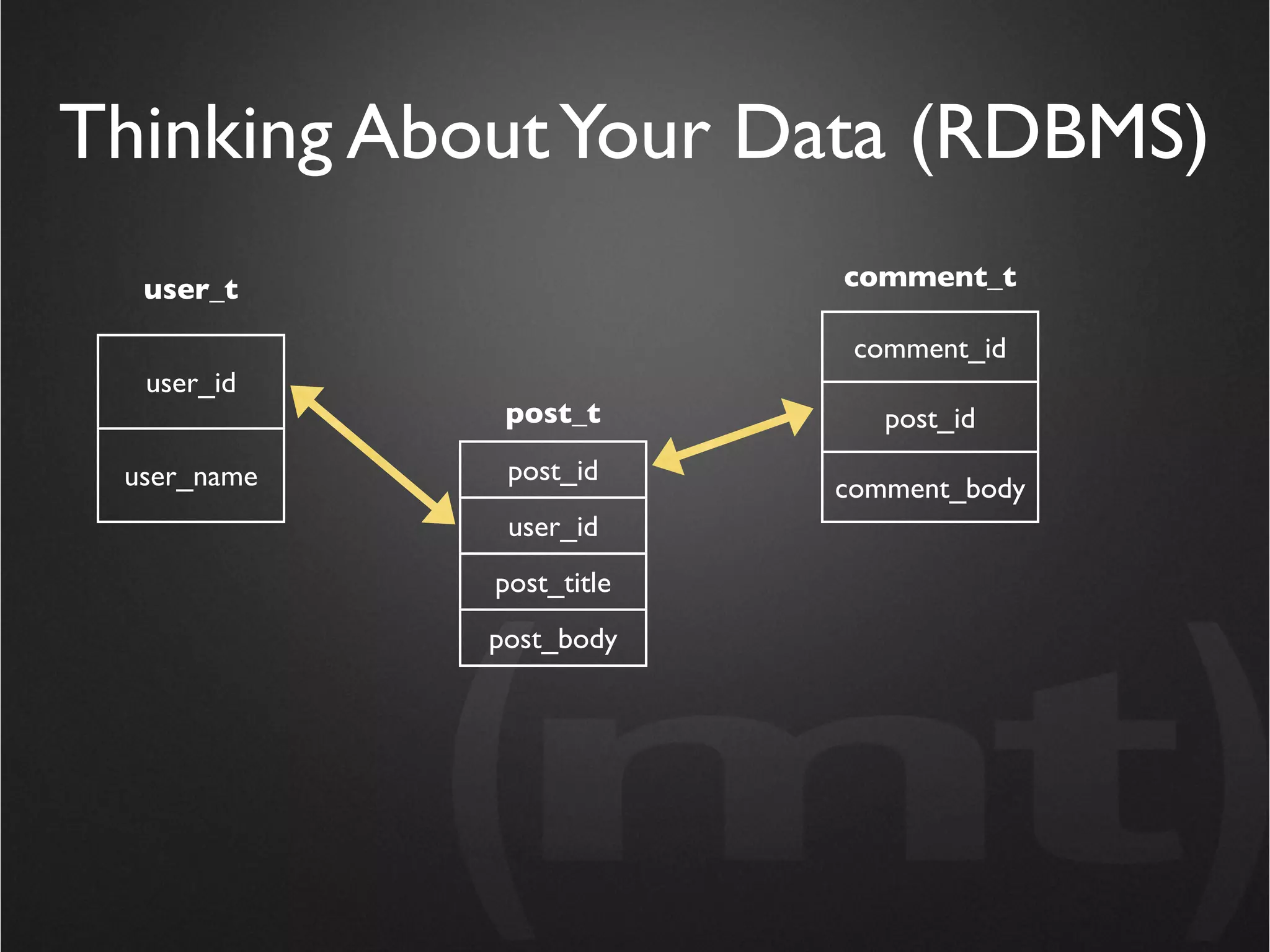
The document discusses NoSQL databases as an alternative to SQL databases. It defines NoSQL as structured data storage that does not rely on SQL for access. The document notes that NoSQL does not mean SQL is bad, and explores when a NoSQL database may be preferable to a SQL database, such as when an application's data needs are not well suited to the transactions and joins supported by SQL. It then summarizes different types of NoSQL databases and provides MongoDB as an example use case, highlighting how it avoids some of the overhead of SQL through its flexible schema and high performance.



































































