Downloaded 24 times





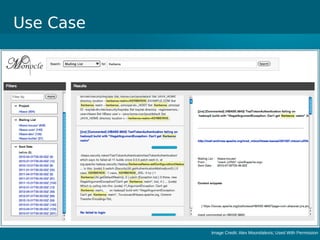
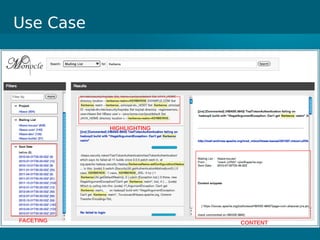
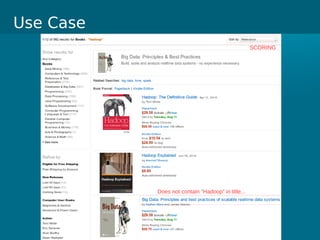

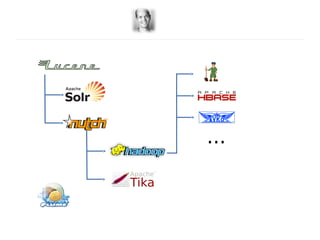




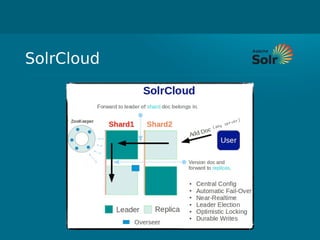






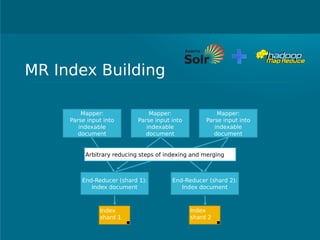



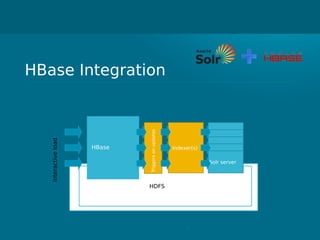

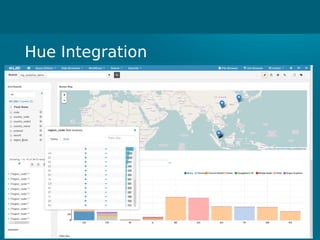



- Cloudera Search provides an overview of using Solr on Hadoop for search capabilities. - Key projects involved include Lucene, Solr, and Hadoop which can be integrated to allow indexing of data on HDFS and querying via search. - The presentation discusses architectural details of running Solr on HDFS and integrating other Hadoop projects like HBase, MapReduce, and Hue.























































































