Download as PDF, PPTX

























![30
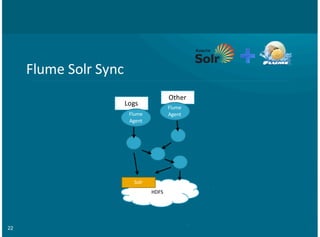
Morphlines+Example+Config
morphlines+:+[
+{
+++id+:+morphline1
+++importCommands+:+["com.cloudera.**",+"org.apache.solr.**"]
+++commands+:+[
+++++{+readLine+{}+}++++++++++++++++++++
+++++{+
+++++++grok+{+
+++++++++dictionaryFiles+:+[/tmp/grokFdictionaries]+++++++++++++++++++++++++++++++
+++++++++expressions+:+{+
+++++++++++message+:+"""<%{POSINT:syslog_pri}>%{SYSLOGTIMESTAMP:syslog_timestamp}+%
{SYSLOGHOST:syslog_hostname}+%{DATA:syslog_program}(?:[%{POSINT:syslog_pid}])?:+%
{GREEDYDATA:syslog_message}"""
+++++++++}
+++++++}
+++++}
+++++{+loadSolr+{}+}+++++
++++]
+}
]
Example(Input
<164>Feb++4+10:46:14+syslog+sshd[607]:+listening+on+0.0.0.0+port+22
Output(Record
syslog_pri:164
syslog_timestamp:Feb++4+10:46:14
syslog_hostname:syslog
syslog_program:sshd
syslog_pid:607
syslog_message:listening+on+0.0.0.0+port+22.](https://image.slidesharecdn.com/hadoopplussolrbigdatasearch-130715115557-phpapp02/85/Solr-Hadoop-Big-Data-Search-30-320.jpg)


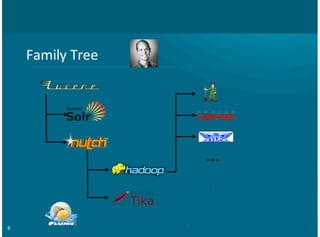
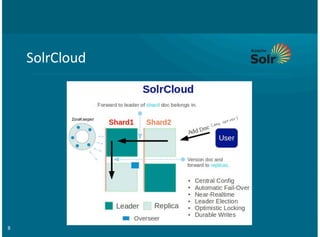
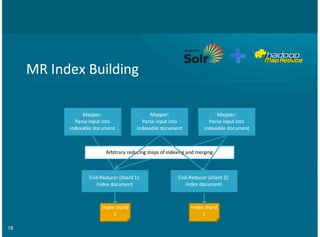
This document provides an overview of integrating Solr with Hadoop for big data search capabilities. It discusses Lucene as the core search library that Solr is built on top of. It then covers ways Solr has been integrated with Hadoop, including putting the Solr index and transaction log directly in HDFS, running Solr on HDFS, and enabling Solr replication on HDFS. Other topics include using MapReduce for scalable index building, integrating Flume and HBase with Solr, and using Morphlines for extraction, transformation, and loading data into Solr.























































































