Downloaded 28 times












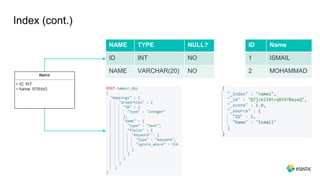

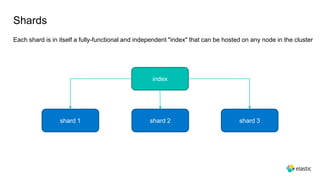
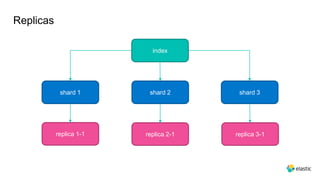

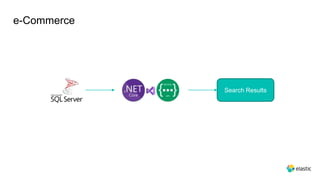
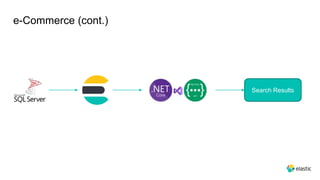

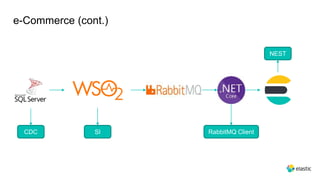



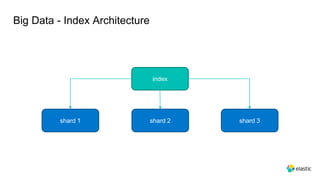
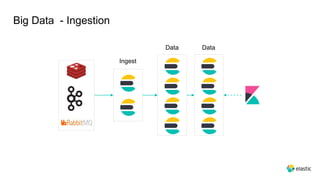
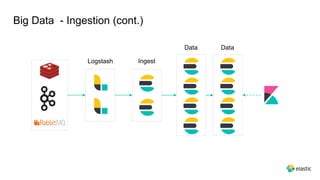
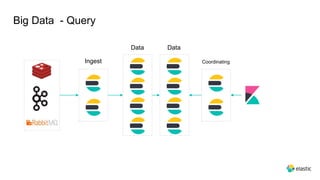
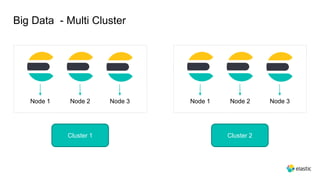
















This document provides an overview and introduction to Elasticsearch. It discusses the speaker's experience and community involvement. It then covers how to set up Elasticsearch and Kibana locally. The rest of the document describes various Elasticsearch concepts and features like clusters, nodes, indexes, documents, shards, replicas, and building search-based applications. It also discusses using Elasticsearch for big data, different search capabilities, and text analysis.






















































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)
