Downloaded 44 times








![<?php
$solr_options = array('secure' => false, 'hostname' => 'localhost', 'port' => 8080);
$solr = new SolrClient($solr_options);
$doc = new SolrInputDocument();
while ($row = mysql_fetch_array($result, MYSQL_ASSOC))
{
$doc = new SolrInputDocument();
$row['publish_date'] = strftime('%Y-%m-%dT00:00:01Z', strtotime($row['publish_date']));
foreach ($row as $key => $value) {
$doc->addField($key, $value);
}
$updateResponse = $solr->addDocument($doc);
$response = $updateResponse->getResponse();
if ($response->responseHeader->status != 0) {
print "Error importing into Solr: ";
print_r($response);
}
}
$solr->commit();
?>](https://image.slidesharecdn.com/opensourcesearchananalysis-120225071949-phpapp01/75/Open-Source-Search-An-Analysis-9-2048.jpg)

![$solr_options = array('secure' => false, 'hostname' => 'localhost', 'port' => 8080);
$solr = new SolrClient($solr_options);
$query = new SolrQuery();
$query->setQuery("research in china");
$query->setFacet(true);
$query->addFacetField('availability');
$query->addField('item_guid')->addField('name')->addField('publish_date')->addField('subtitle')->
addField('product_code')->addField('availability')->addField('price');
$query->addSortField('publish_date', SolrQuery::ORDER_DESC);
$query_response = $solr->query($query);
$response = $query_response->getResponse();
print "Found ".$response->response->numFound." results, for {$query_string} in ".$response-
>responseHeader->QTime." ms:nn";
foreach ($response->response->docs as $position=>$doc_data) {
$download = ($doc_data['availability'] == '1') ? 'Yes' : 'No';
print "{$position} - Date:{$pub_date} - {$doc_data['product_code']} - D/L:{$download} £".sprintf("%5d",
$doc_data['price'])." - {$doc_data['name']}n";
}
print "Facets for instant ".$response->facet_counts->facet_fields->availability->false;](https://image.slidesharecdn.com/opensourcesearchananalysis-120225071949-phpapp01/75/Open-Source-Search-An-Analysis-11-2048.jpg)





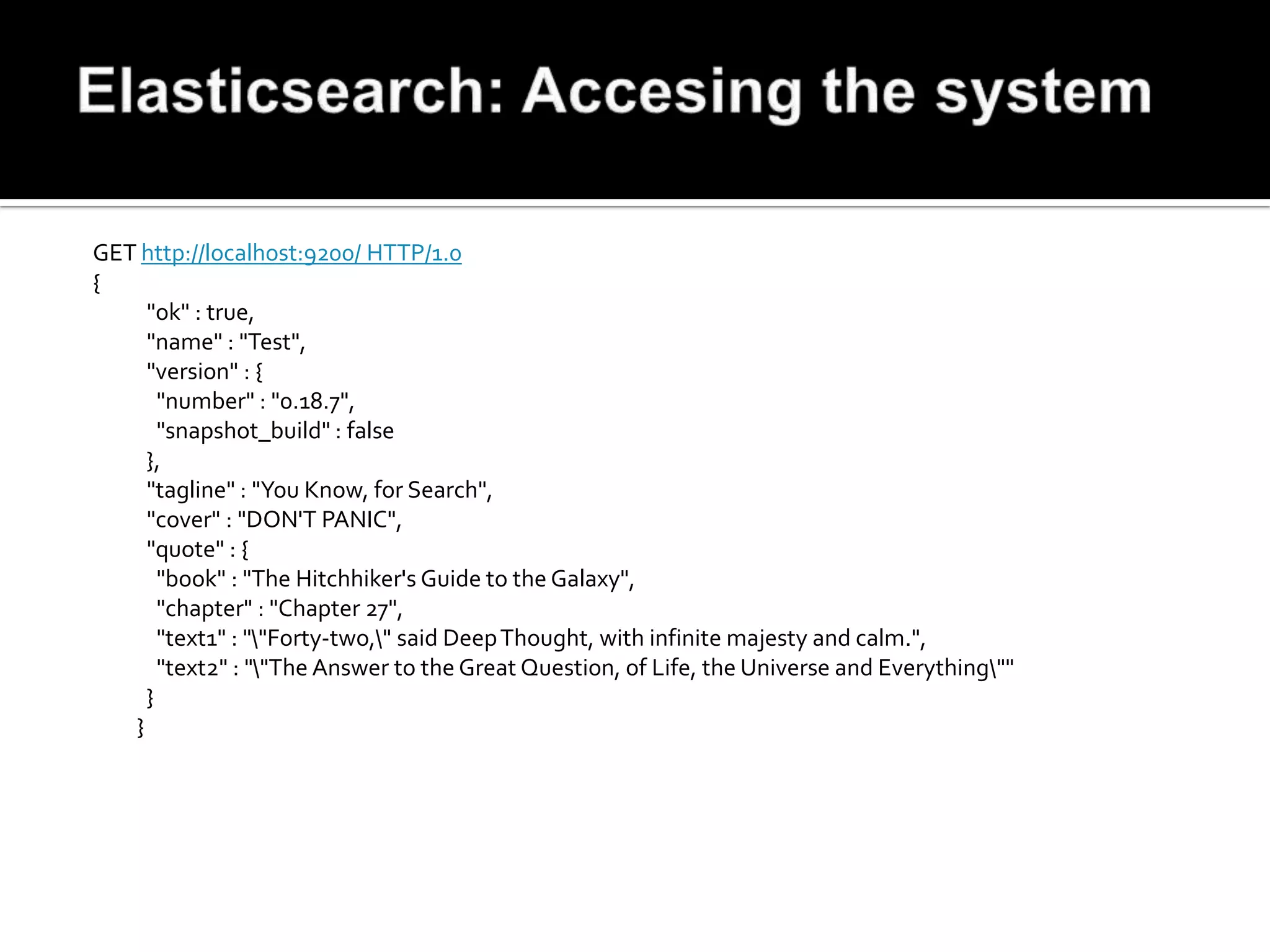
![curl -XPUT http://localhost:9200/reports/ -d '
{
"index:" {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"filter": ["standard", "lowercase", "my_stemmer"]
}
},
"filter": {
"my_stemmer": {
"type": "stemmer",
"name": "english"
}
}
}
}
}'](https://image.slidesharecdn.com/opensourcesearchananalysis-120225071949-phpapp01/75/Open-Source-Search-An-Analysis-18-2048.jpg)

![<?php
require_once("ElasticSearch.php");
$es = new ElasticSearch;
$es->index = 'reports';
$type = 'report';
$sql = "SELECT `item_guid`, `name`, `subtitle`, `summary`, `toc`, `supplier`,
`product_code`, `isbn`, `category`, `price`, `availibility` as `availability`,
`type`, `link`, `publish_date`
FROM `rb_search`";
$result = read_query($sql);
while ($row = mysql_fetch_array($result, MYSQL_ASSOC))
{
$es->add($type, $row['item_guid'], json_encode($row));
}
?>](https://image.slidesharecdn.com/opensourcesearchananalysis-120225071949-phpapp01/75/Open-Source-Search-An-Analysis-20-2048.jpg)
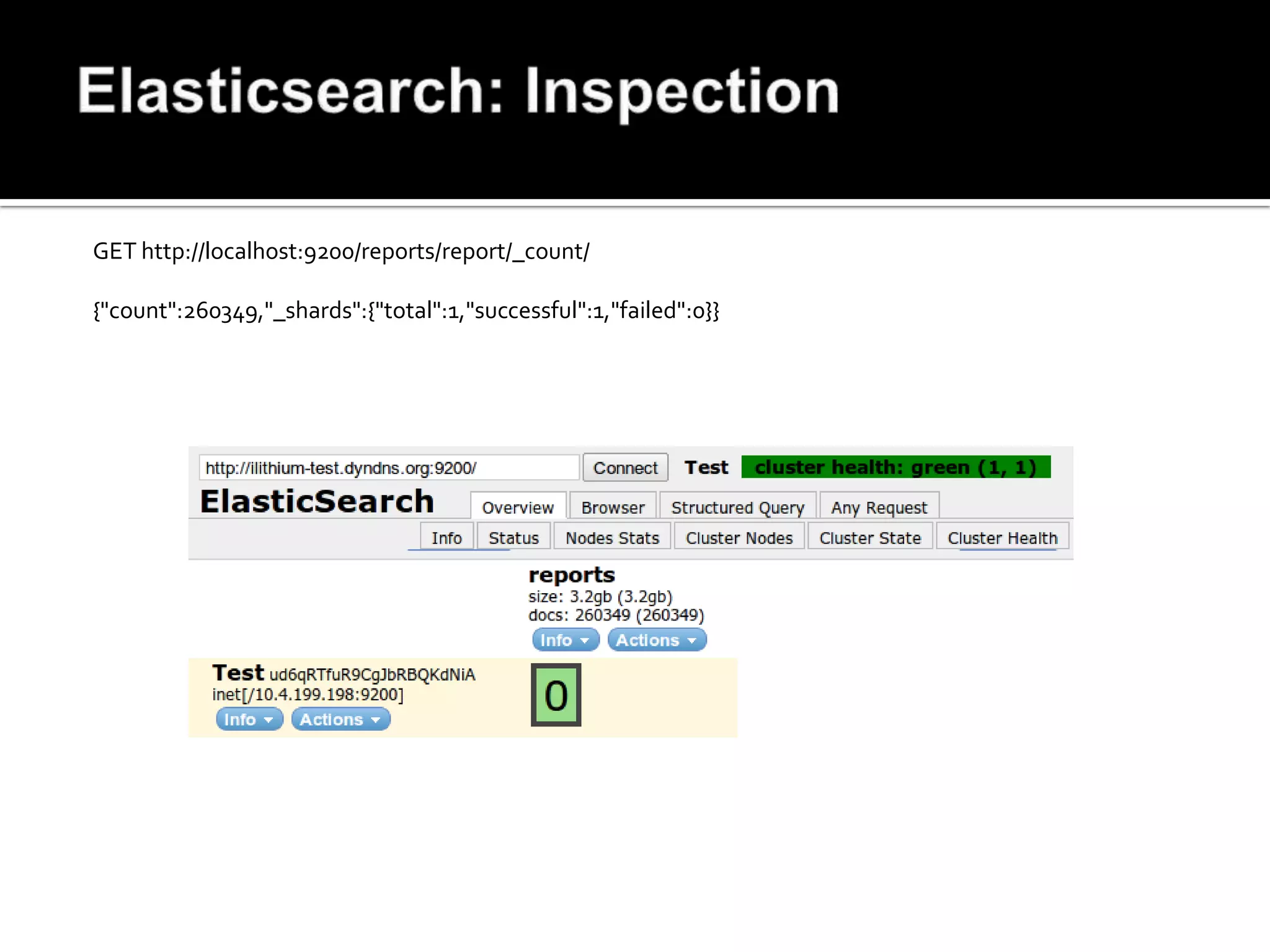







![<?php
require_once("mysql.inc.php");
$sql = "SELECT conv(mid(md5(`item_guid`), 1, 16), 16, 10) AS `id`, `item_guid`, `name`,
`subtitle`, `summary`, `toc`, `supplier`, `product_code`, `isbn`, `category`,
`price`, `availibility` as `availability`, `type`, `link`, UNIX_TIMESTAMP(`publish_date`) AS
`publish_date` FROM `rb_search`";
$result = read_query($sql);
$sphinx = mysql_connect("127.0.0.1:9306", "", "", true);
while ($row = mysql_fetch_array($result, MYSQL_ASSOC)) {
foreach ($row as $key=>$value) {
$row[$key] = mysql_escape_string($value);
}
$sql = "REPLACE INTO `rb_search` (`id`, `title`, `subtitle`,`availability`, `type`, `price`, `publish_date`,
`item_guid`, `supplier`, `product_code`, `isbn`, `category`, `link`, `summary`, `toc`)
VALUES
('{$row['id']}', '{$row['name']}', '{$row['subtitle']}', '{$row['availability']}',
'{$row['type']}','{$row['price']}', '{$row['publish_date']}', '{$row['item_guid']}', '{$row['supplier']}',
'{$row['product_code']}', '{$row['isbn']}', '{$row['category']}', '{$row['link']}','{$row['summary']}',
'{$row['toc']}')";
mysql_query($sql, $sphinx);
}
?>](https://image.slidesharecdn.com/opensourcesearchananalysis-120225071949-phpapp01/75/Open-Source-Search-An-Analysis-29-2048.jpg)





![<?php
$xapian_db = new XapianWritableDatabase($xapian, Xapian::DB_CREATE_OR_OVERWRITE);
$xapian_term_generator = new XapianTermGenerator();
$xapian_term_generator->set_stemmer(new XapianStem("english"));
while ($row = mysql_fetch_array($result, MYSQL_ASSOC)) {
$doc = new XapianDocument();
$xapian_term_generator->set_document($doc);
foreach ($xapian_term_weights as $field => $weight) {
$xapian_term_generator->index_text($row[$field], $weight);
}
$xapian_term_generator->index_text($row['name'], 75, 'S:');
$doc->add_boolean_term('CODE:' . $row['product_code']);
$doc->add_value($xapian_value_slots['price'], Xapian::sortable_serialise($row['price']));
$doc->add_value($xapian_value_slots['publish_date'], strftime("%Y%m%d",
strtotime($row['publish_date'])));
// add in additional values that we're going to use for facets
$doc->add_value($xapian_value_slots['availability'], $row['availability']);
$doc->set_data(serialize($doc_data));
$docid = 'Q'.$row['item_guid'];
$xapian_db->replace_document($docid, $doc);
}
?>](https://image.slidesharecdn.com/opensourcesearchananalysis-120225071949-phpapp01/75/Open-Source-Search-An-Analysis-35-2048.jpg)
![<?php
$xapian_db = new XapianDatabase($xapian);
$query_parser = new XapianQueryParser();
$query_parser->set_stemmer(new XapianStem("english"));
$query_parser->set_default_op(XapianQuery::OP_AND);
$dvrProcessor = new XapianDateValueRangeProcessor($xapian_value_slots['publish_date'], 'date:');
$query_parser->add_valuerangeprocessor($dvrProcessor);
$query_parser->add_prefix("code", "CODE:");
$query_parser->add_prefix("category", "CATEGORY:");
$query_parser->add_prefix("title", "S:");
$query = $query_parser->parse_query('“Medical devices” NEAR china NOT russian price:10..150 category:medical');
$enquire = new XapianEnquire($xapian_db);
$enquire->set_query($query);
$matches = $enquire->get_mset($offset, $pagesize);
while (!($start->equals($end))) {
$doc = $start->get_document();
$price = Xapian::sortable_unserialise($doc->get_value($xapian_value_slots['price']));
$start->next();
}?>](https://image.slidesharecdn.com/opensourcesearchananalysis-120225071949-phpapp01/75/Open-Source-Search-An-Analysis-36-2048.jpg)




The document provides a detailed analysis and comparison of various search engines from a developer's perspective, focusing on features, configuration options, and integration capabilities using APIs and frameworks like Apache Lucene, Solr, Elasticsearch, and Sphinx. It discusses aspects such as indexing, searching, data handling, and performance metrics relevant to enterprise-class applications. Additionally, it highlights the requirements and advantages of specific systems along with example code snippets for implementation.