Downloaded 53 times



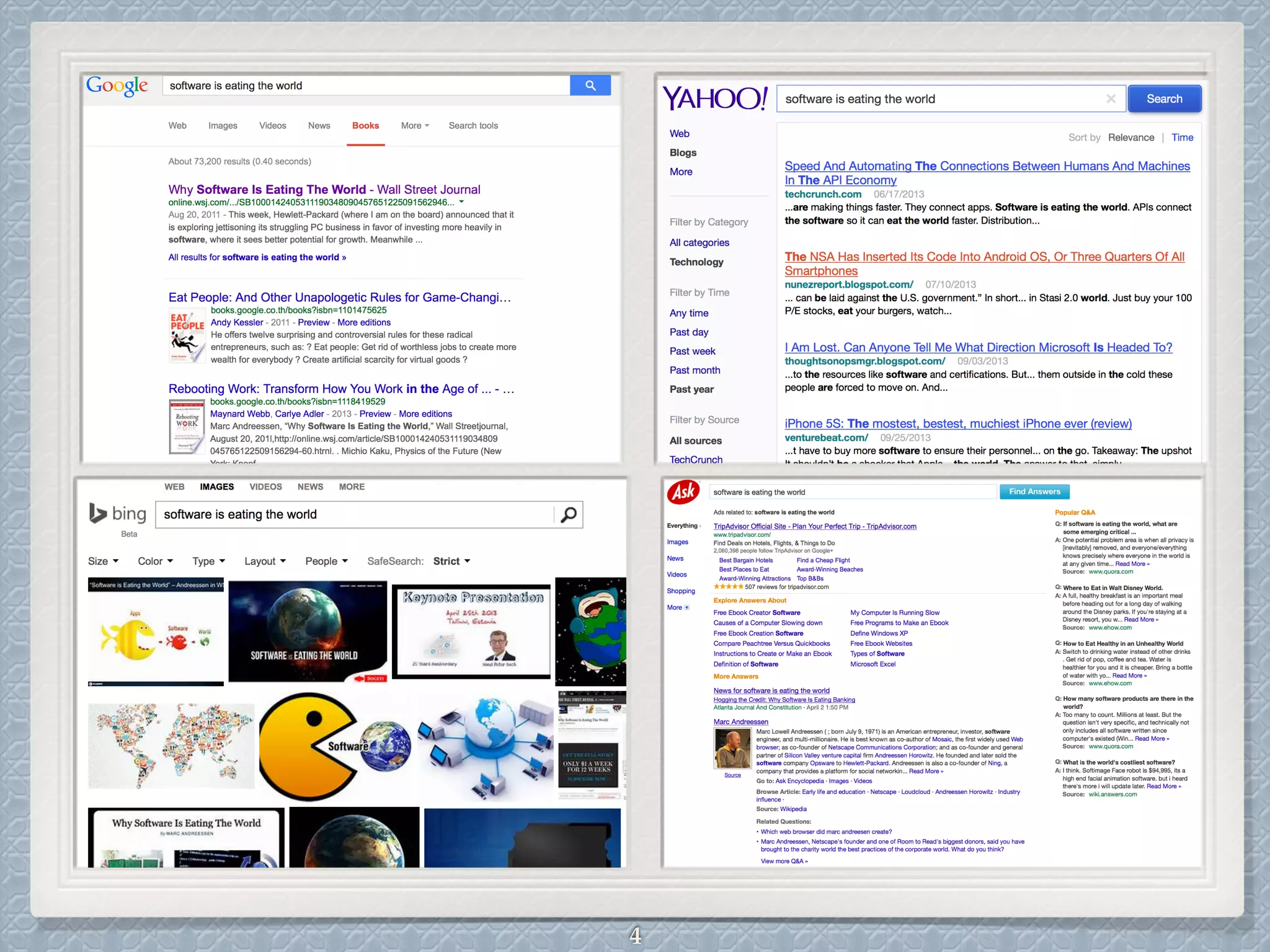

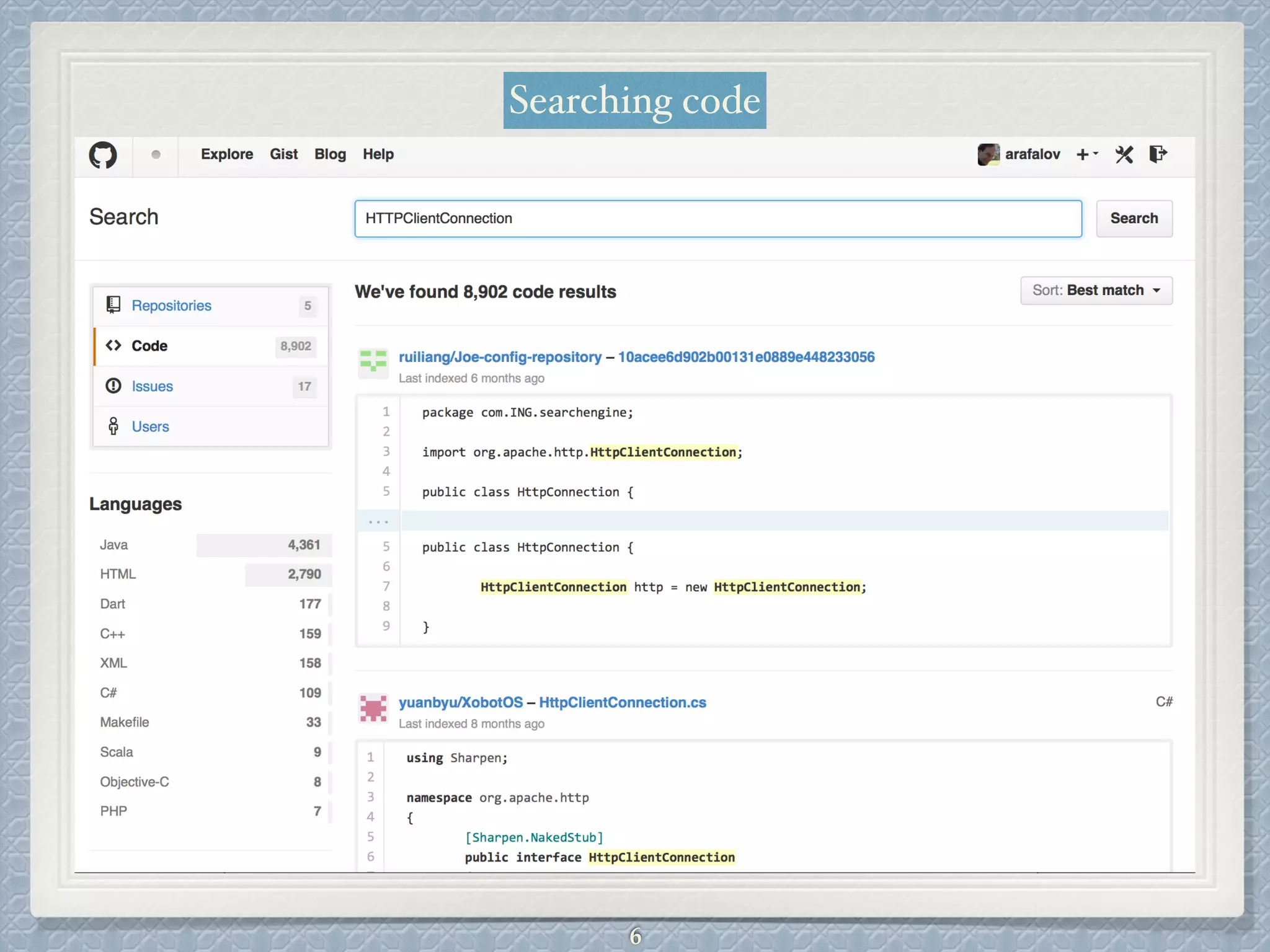
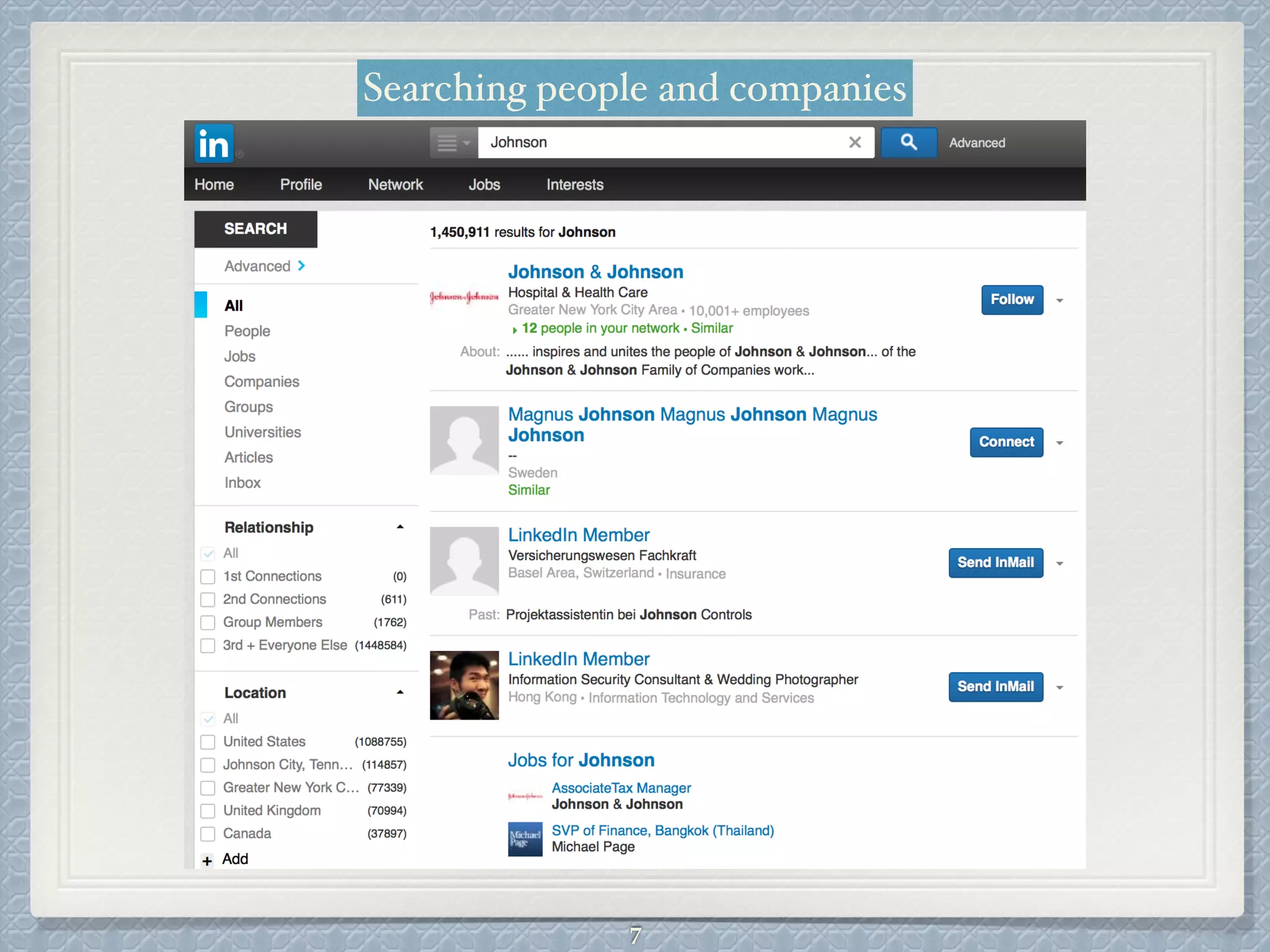
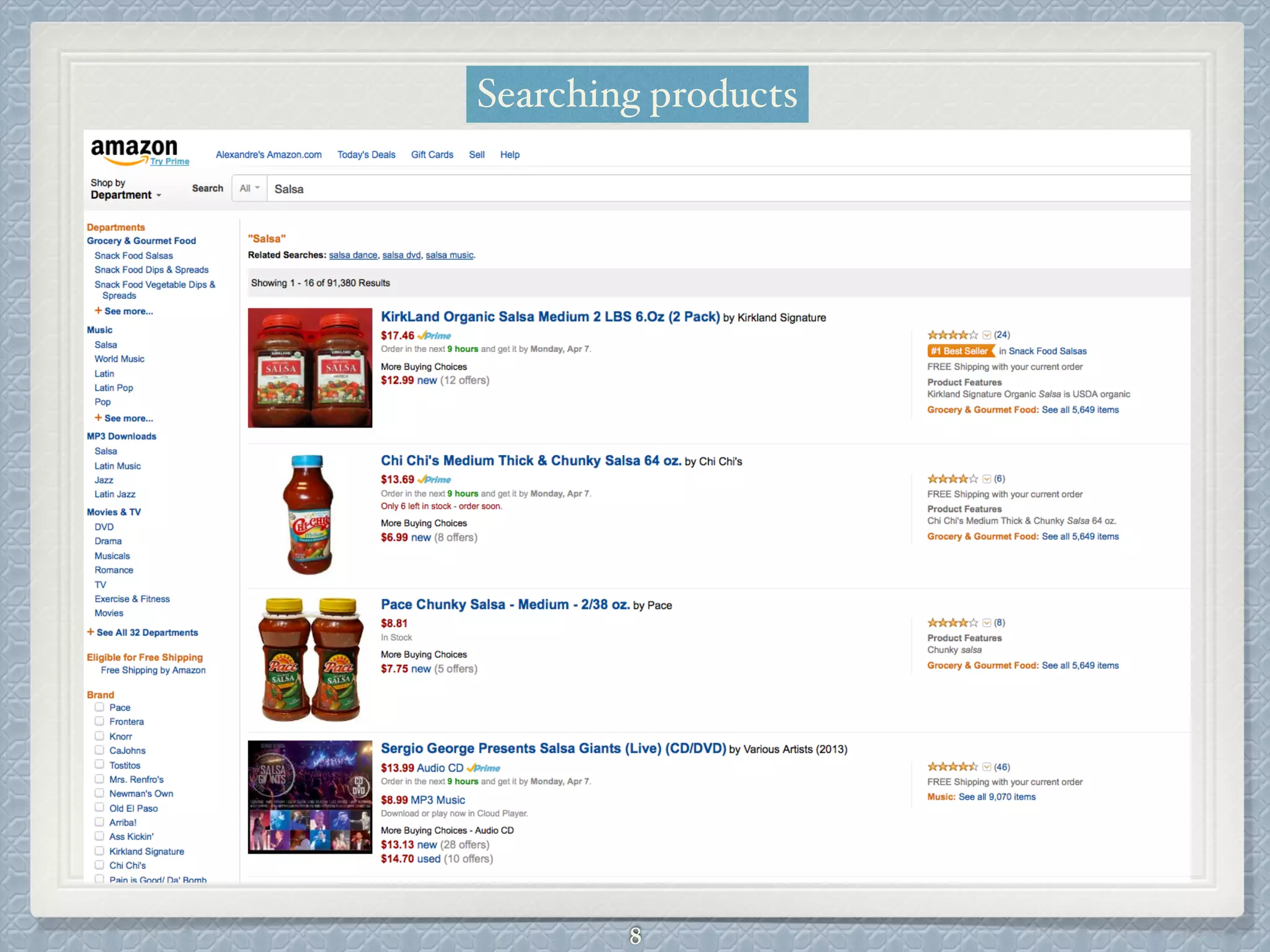











































This document provides an overview of the Apache Solr search engine. It begins with an introduction to full-text search and how it differs from basic SQL queries. It then covers the basic and advanced features of Solr, highlighting facets, language-specific processing, and geographic search. The document reviews how Solr uses Lucene for indexing and search capabilities. It concludes with discussing ways to get started with Solr, including downloading the software and importing sample data for testing.

















































![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)











