Download to read offline


![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
Stochastic Dominance and Related Indices
• First Order Stochastic Dominance (cf standard stochastic order, st)
X 1 Y ⇐⇒ FX(t) ≥ FY (t), ∀t ⇐⇒ VaRX(u) ≤ VaRY (u), ∀u
• Convex Stochastic Dominance (cf martingale property)
X cx Y ⇐⇒ E[ ˜Y | ˜X] = ˜X ⇐⇒ ESX(u) ≤ ESY (u), ∀u and E(X) = E(Y )
• Second Order Stochastic Dominance (cf submartingale property,
stop-loss order, icx)
X 2 Y ⇐⇒ E[ ˜Y | ˜X] ≥ ˜X ⇐⇒ ESX(u) ≤ ESY (u), ∀u
• Lorenz Stochastic Dominance (cf dilatation order)
X L Y ⇐⇒
X
E[X]
cx
X
E[Y ]
⇐⇒ LX(u) ≤ LY (u), ∀u
2](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-2-320.jpg)




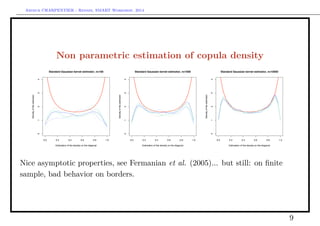
![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
Non parametric estimation of copula density
see C., Fermanian & Scaillet (2005), bias of kernel estimators at endpoints
0.0 0.2 0.4 0.6 0.8 1.0
0.00.20.40.60.81.01.2
Kernel based estimation of the uniform density on [0,1]
Density
0.0 0.2 0.4 0.6 0.8 1.00.00.20.40.60.81.01.2
Kernel based estimation of the uniform density on [0,1]
Density
7](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-7-320.jpg)
![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
Non parametric estimation of copula density
e.g. E(c(0, 0, h)) =
1
4
· c(u, v) −
1
2
[c1(0, 0) + c2(0, 0)]
1
0
ωK(ω)dω · h + o(h)
0.2 0.4 0.6 0.8
0.2
0.4
0.6
0.8
0
1
2
3
4
5
Estimation of Frank copula
0.2 0.4 0.6 0.8
0.2
0.4
0.6
0.8
0
1
2
3
4
5
Estimation of Frank copula
0.0 0.2 0.4 0.6 0.8 1.0
0.00.20.40.60.81.0
with a symmetric kernel (here a Gaussian kernel).
8](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-8-320.jpg)
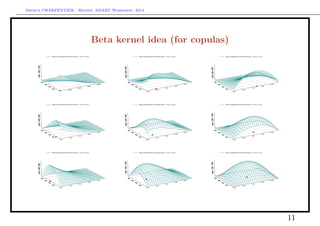
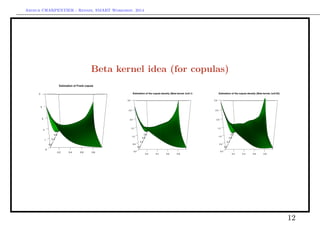
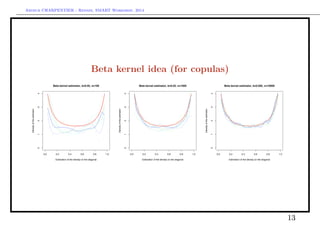
![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
Beta kernel idea (for copulas)
see Chen (1999, 2000), Bouezmarni & Rolin (2003),
Kxi (u) ∝ exp −
(u − xi)2
h2
vs. Kxi (u) ∝ u
x1,i
b
1 [1 − u1]
x1,i
b · u
x2,i
b
2 [1 − u2]
x2,i
b
10
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q q
q
q
qq
q
q
q
q
q
qq
q
q
q
q
q
q
q
q
q
q
q q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q q
q
q
q
q q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
qq
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q q
q
q
q
q
q
q
q
q
q
q
q
q
q
q q
q
q
q
q
q
q
q
q
q
q
q
q
qq
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
qq
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
qq
qq
q
q
q
q q
q
q q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
qq
q
q
q
q
q
q
q
q
q
q
q
q
q
q q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q q
q
q
q
q
q
q q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q
q](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-10-320.jpg)
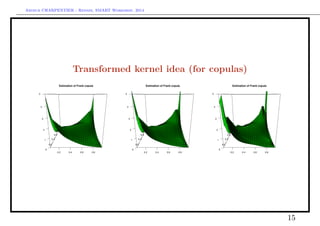
![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
Transformed kernel idea (for copulas)
[0, 1] × [0, 1] → R × R → [0, 1] × [0, 1]
14](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-14-320.jpg)
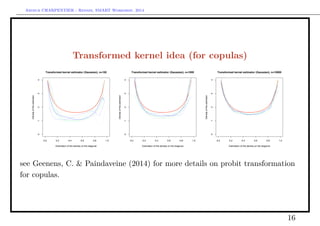
![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
Combining the two approaches
See Devroye & Györfi (1985), and Devroye & Lugosi (2001)
... use the transformed kernel the other way, R → [0, 1] → R
17](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-17-320.jpg)

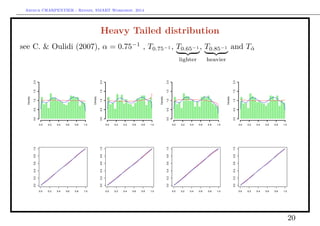
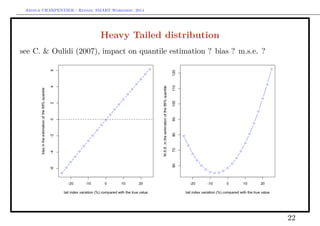
![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
Heavy Tailed distribution
Let X denote a (heavy-tailed) random variable with tail index α ∈ (0, ∞), i.e.
P(X > x) = x−α
L1(x)
where L1 is some regularly varying function.
Let T denote a R → [0, 1] function, such that 1 − T is regularly varying at
infinity, with tail index β ∈ (0, ∞).
Define Q(x) = T−1
(1 − x−1
) the associated tail quantile function, then
Q(x) = x1/β
L2(1/x), where L2 is some regularly varying function (the de Bruyn
conjugate of the regular variation function associated with T). Assume here that
Q(x) = bx1/β
Let U = T(X). Then, as u → 1
P(U > u) ∼ (1 − u)α/β
.
19](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-19-320.jpg)
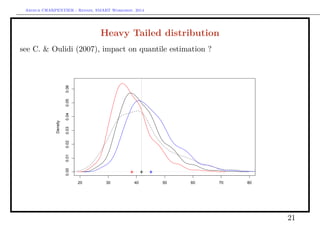
![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
Which transformation ?
GB2 : t(y; a, b, p, q) =
|a|yap−1
bapB(p, q)[1 + (y/b)a]p+q
, for y > 0,
GB2
q→∞
a=1
p=1
55
q=1
@@
GG
a→0
ÓÓ
a=1
p=1
%%
Beta2
q→∞
ww
SM
q→∞
xx
q=1
99
Dagum
p=1
Lognormal Gamma Weibull Champernowne
23](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-23-320.jpg)
![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
Estimating a density on R+
• Stay on R+ : xi’s
• Get on [0, 1] : ui = Tθ
(xi) (distribution as uniform as possible)
◦ Use Beta Kernels on ui’s
◦ Mixtures of Beta distributions on ui’s
◦ Bernstein Polynomials on ui’s
• Get on R : use standard kernels (e.g. Gaussian)
◦ On xi = log(xi)
◦ On xi = BoxCoxλ
(xi)
◦ On xi = Φ−1
[Tθ
(xi)]
24](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-24-320.jpg)
![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
Beta kernel
g(u) =
n
i=1
1
n
· b u;
Ui
h
,
1 − Ui
h
u ∈ [0, 1].
with some possible boundary correction, as suggested in Chen (1999),
u
h
→ ρ(u, h) = 2h2
+ 2.5 − (4h4
+ 6h2
+ 2.25 − u2
− u/h)1/2
Problem : choice of the bandwidth h ? Standard loss function
L(h) = [gn(u) − g(u)]2
du = [gn(u)]2
du − 2 gn(u) · g(u)du
CV (h)
+ [g(u)]2
du
where
CV (h) = gn(u)du
2
−
2
n
n
i=1
g(−i)(Ui)
25](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-25-320.jpg)
![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
Mixture of Beta distributions
g(u) =
k
j=1
πj · b u; αj, βj u ∈ [0, 1].
Problem : choice the number of components k (and estimation...). Use of
stochastic EM algorithm (or sort of) see Celeux Diebolt (1985).
Bernstein approximation
g(u) =
m
k=1
[mωk] · b (u; k, m − k) u ∈ [0, 1].
where ωk = G
k
m
− G
k − 1
m
.
26](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-26-320.jpg)
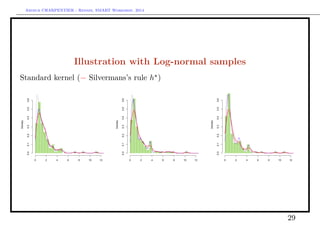
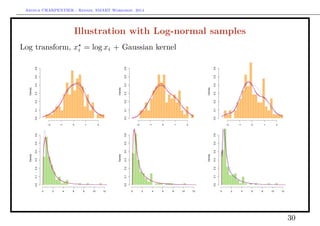
![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
On the log-transform
With a standard Gaussian kernel
fX(x) =
1
n
n
i=1
φ(x; xi, h)
A Gaussian kernel on a log transform,
fX(x) =
1
x
fX (log x) =
1
n
n
i=1
λ(x; log xi, h)
where λ(·; µ, σ) is the density of the log-normal distribution. Here, in 0,
bias[fX(x)] ∼
h2
2
[fX(x) + 3x · fX(x) + x2
· fX(x)]
and
Var[fX(x)] ∼
fX(x)
xnh
27](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-27-320.jpg)
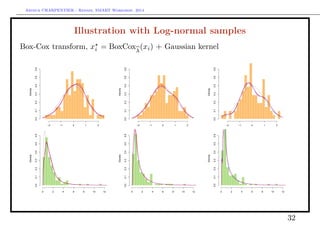
![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
On the Box-Cox-transform
More generally, instead of transformed sample Yi = log[Xi], consider
Yi =
Xλ
i − 1
λ
when λ = 0.
Find the optimal transformation using standard regression techniques (least
squares)
Xi =
Xλ
i − 1
λ
when λ = 0
and Xi = log[Xi] if λ = 0. The density estimation is here
fX(x) = xλ −1
fX
xλ
− 1
λ
28](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-28-320.jpg)
![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
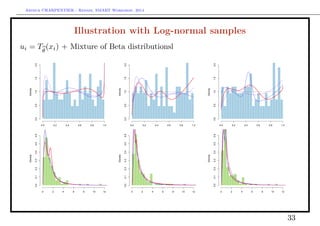
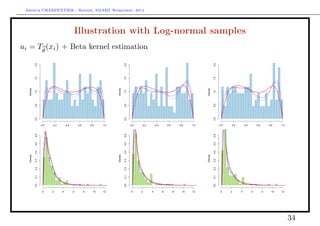
Illustration with Log-normal samples
Probit-type transform, xi = Φ−1
[Tθ
(xi)] + Gaussian kernel
Density
−2 −1 0 1 2
0.00.10.20.30.40.50.6
Density
−2 −1 0 1 20.00.10.20.30.40.50.6
Density
−2 −1 0 1 2
0.00.10.20.30.40.50.6
Density
0 2 4 6 8 10 12
0.00.10.20.30.40.50.6
Density
0 2 4 6 8 10 12
0.00.10.20.30.40.50.6
Density
0 2 4 6 8 10 12
0.00.10.20.30.40.50.6
31](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-31-320.jpg)

![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
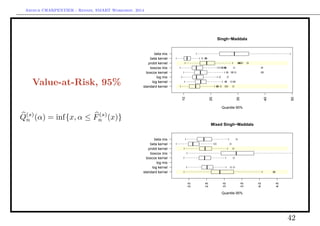
Quantities of interest
Inequality indices and risk measures, based on F(x) =
x
0
f(t)dt,
• Gini,
1
µ
∞
0
F(t)[1 − F(t)]dt
• Theil,
∞
0
t
µ
log
t
µ
f(t)dt
• Entropy −
∞
0
f(t) log[f(t)]dt
• VaR-quantile, x such that F(x) = P(X ≤ x) = α, i.e. F−1
(α)
• TVaR-expected shorfall, E[X|X F−1
(α)]
where µ =
∞
0
[1 − F(x)]dx.
36](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-36-320.jpg)
![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
Computations Aspects
Here, for each method, we return two functions,
• function fn(·)
• a random generator for distribution fn(·)
◦ H-transform and Gaussian kernel
draw i ∈ {1, · · · , n} and X = H−1
(Z) where Z ∼ N(H(xi), b2
)
◦ H-transform and Beta kernel
draw i ∈ {1, · · · , n} and X = H−1
(U) where U ∼ B(H(xi)/h, [1 − H(xi)]/h)
◦ H-transform and Beta mixture
draw k ∈ {1, · · · , K} and X = H−1
(U) where U ∼ B(αk, βk)
37](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-37-320.jpg)



![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
Gini Index
1
µ
(s)
n
∞
0
F(s)
n (t)[1 − F(s)
n (t)]dt
Singh−Maddala
Gini Index
q q
qq
q q
qq
q
qqq
q q
standard kernel
log kernel
log mix
boxcox kernel
boxcox mix
probit kernel
beta kernel
beta mix
0.45
0.50
0.55
0.60
Mixed Singh−Maddala
Gini Index
q
qq
q
q
q qq
qq
standard kernel
log kernel
log mix
boxcox kernel
boxcox mix
probit kernel
beta kernel
beta mix
0.55
0.60
0.65
0.70
41](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-41-320.jpg)
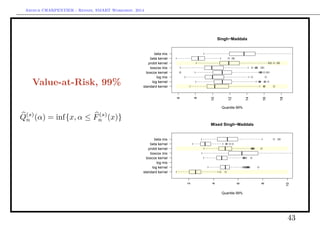
![Arthur CHARPENTIER - Rennes, SMART Workshop, 2014
Tail Value-at-Risk, 95%
E[X|X Q(s)
n (α)]
Singh−Maddala
Expected Shortfall 95%
q
q
qq
q
qq
q
standard kernel
log kernel
log mix
boxcox kernel
boxcox mix
probit kernel
beta kernel
beta mix
4.0
4.5
5.0
5.5
6.0
6.5
q
Mixed Singh−Maddala
Expected Shortfall 95%
q qqq
q qqq
q qqq
q qqq
q
standard kernel
log kernel
log mix
boxcox kernel
boxcox mix
probit kernel
beta kernel
beta mix
4
6
8
10
12
44](https://image.slidesharecdn.com/slides-smart-2015-150427043423-conversion-gate02/85/Slides-smart-2015-44-320.jpg)


This document discusses kernel-based estimation methods for inequality indices and risk measures. It begins with an overview of stochastic dominance and related indices like first-order, convex, and second-order stochastic dominance. It then discusses nonparametric estimation of densities and copula densities using kernel methods. Specifically, it proposes using beta kernels and transformed kernels to improve estimation at the boundaries. The document explores combining these approaches and using mixtures of distributions like beta distributions within the kernels. It concludes by discussing applications to heavy-tailed distributions.






















































































