Downloaded 28 times





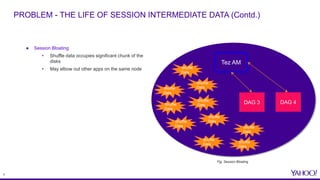





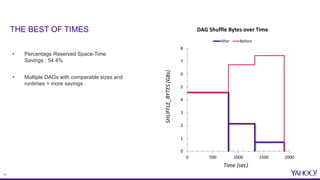
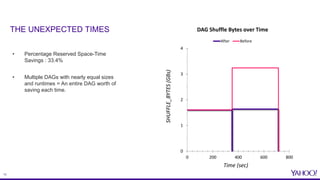
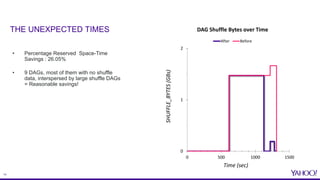
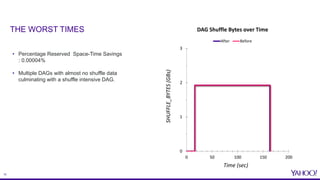






The document discusses improvements in reserved space utilization through the concept of 'dag delete' within Apache Tez, which aims to manage intermediate shuffle data across multiple DAGs within a single session. Key features include container reuse to reduce initialization costs and a deletion policy that can be customized to optimize resource usage. The evaluation shows significant percentage savings in reserved space-time, especially in shuffle-heavy sessions, leading to better performance and utilization of disk space.








































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










