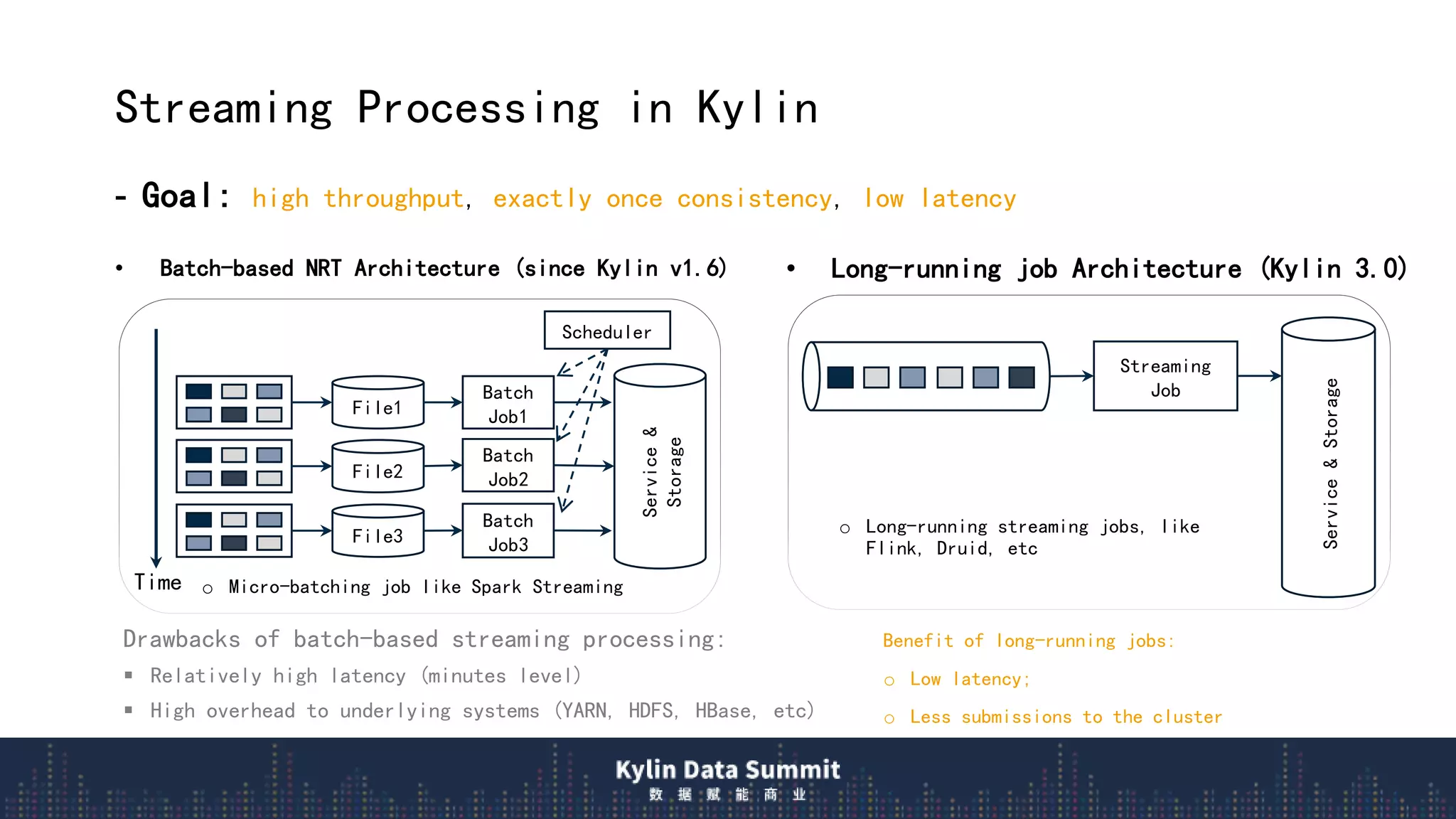
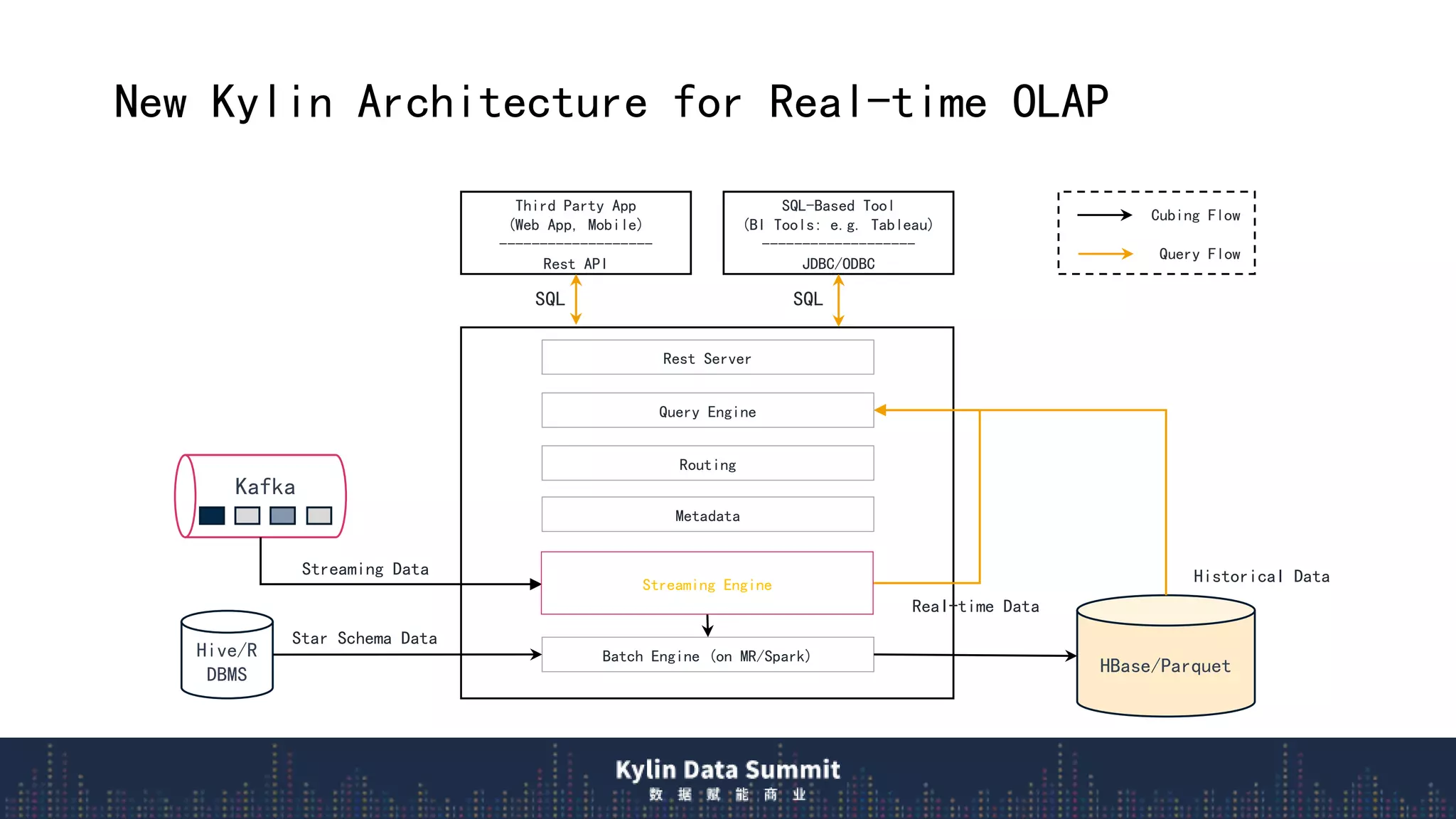
1) Apache Kylin v3.0 introduces a new real-time OLAP architecture using long-running streaming jobs to provide low latency queries over streaming data.
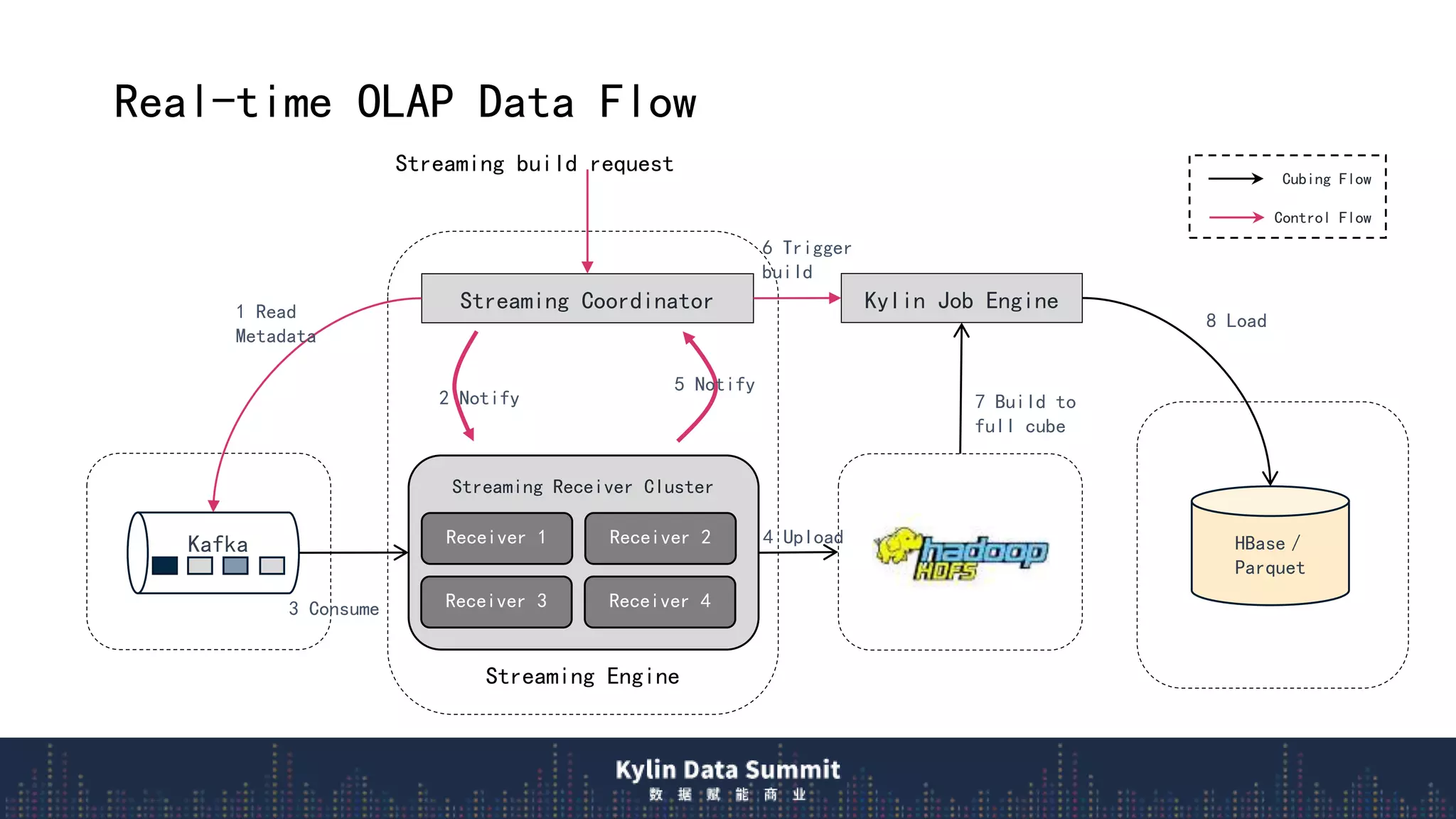
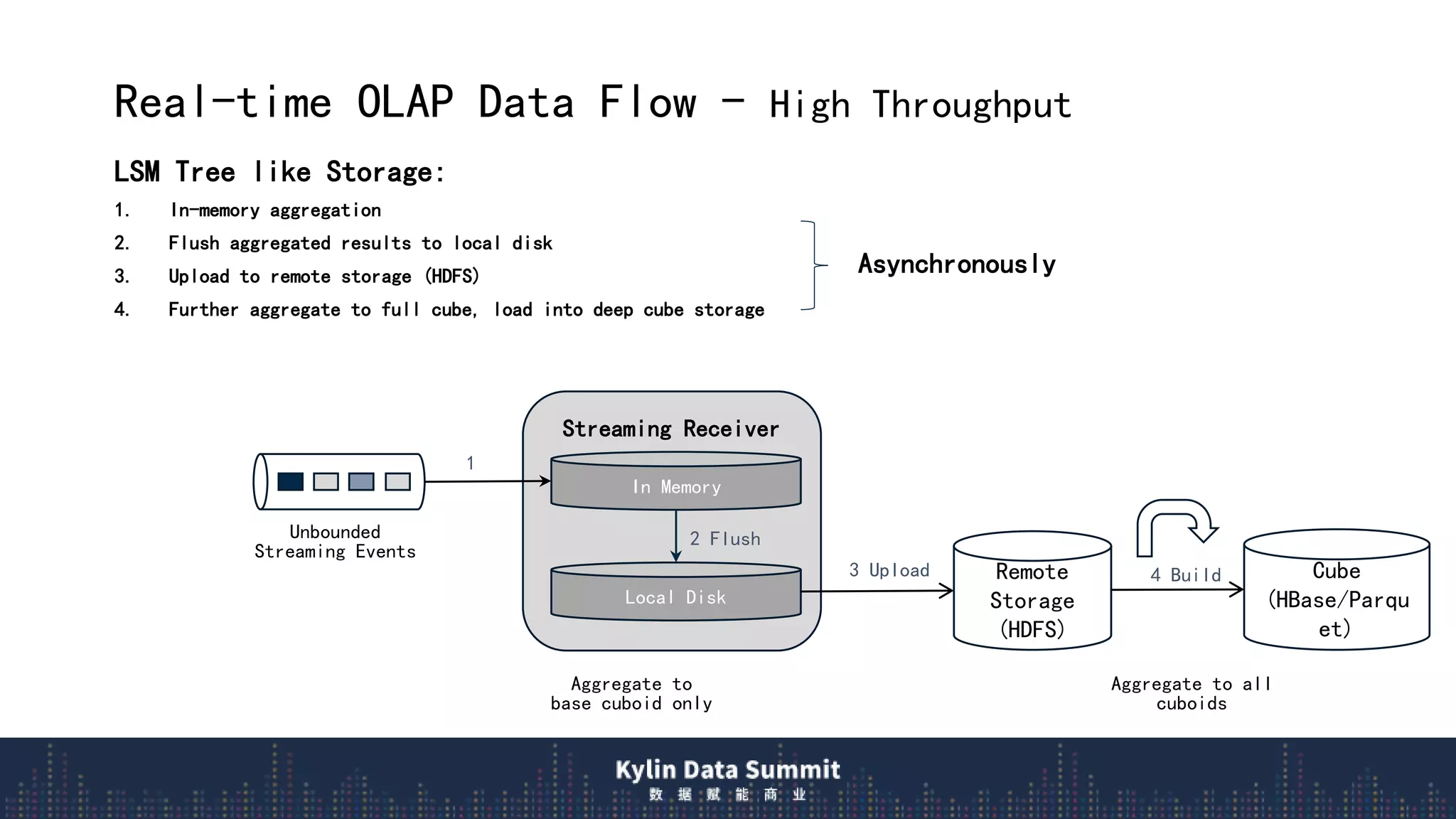
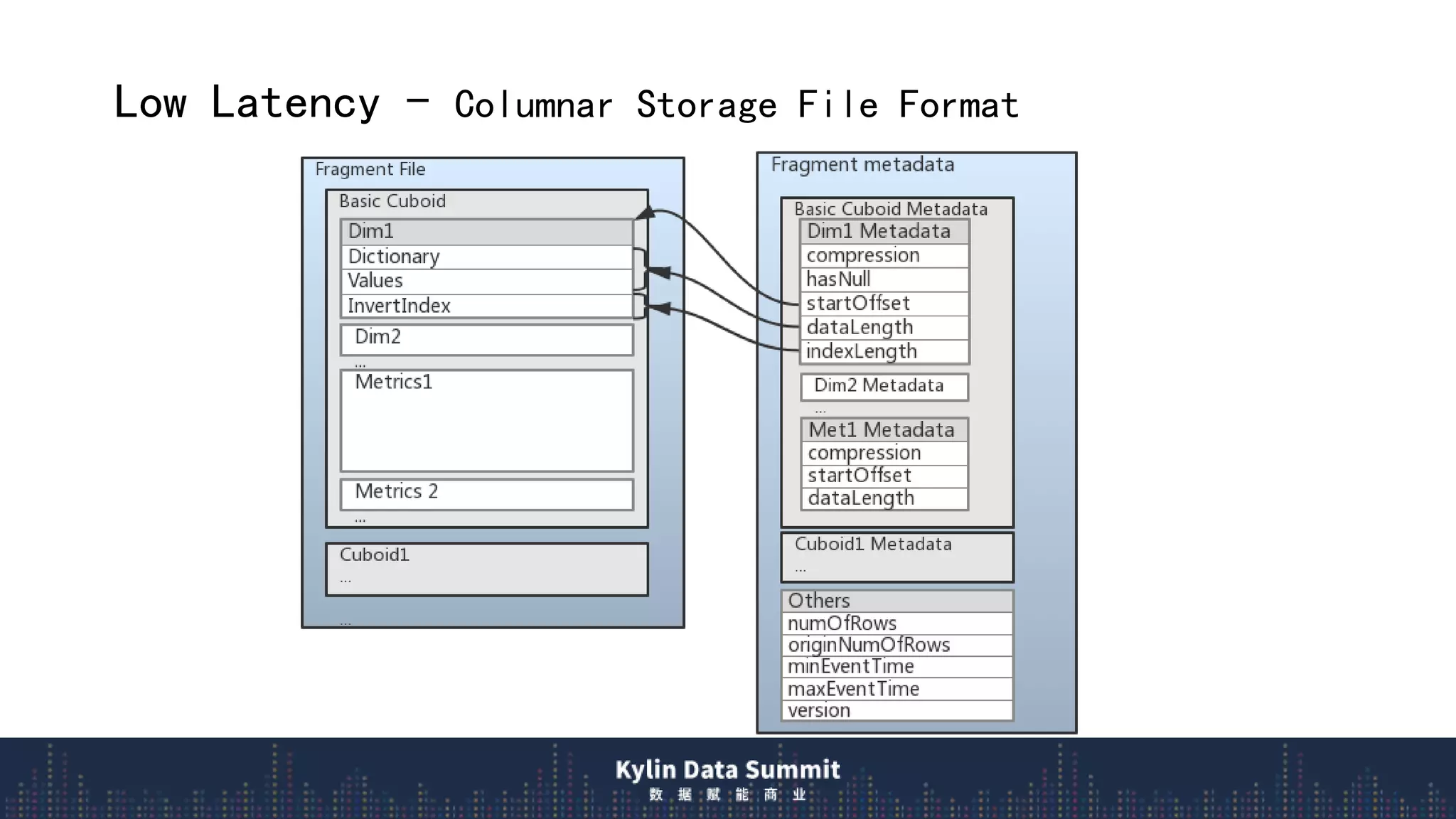
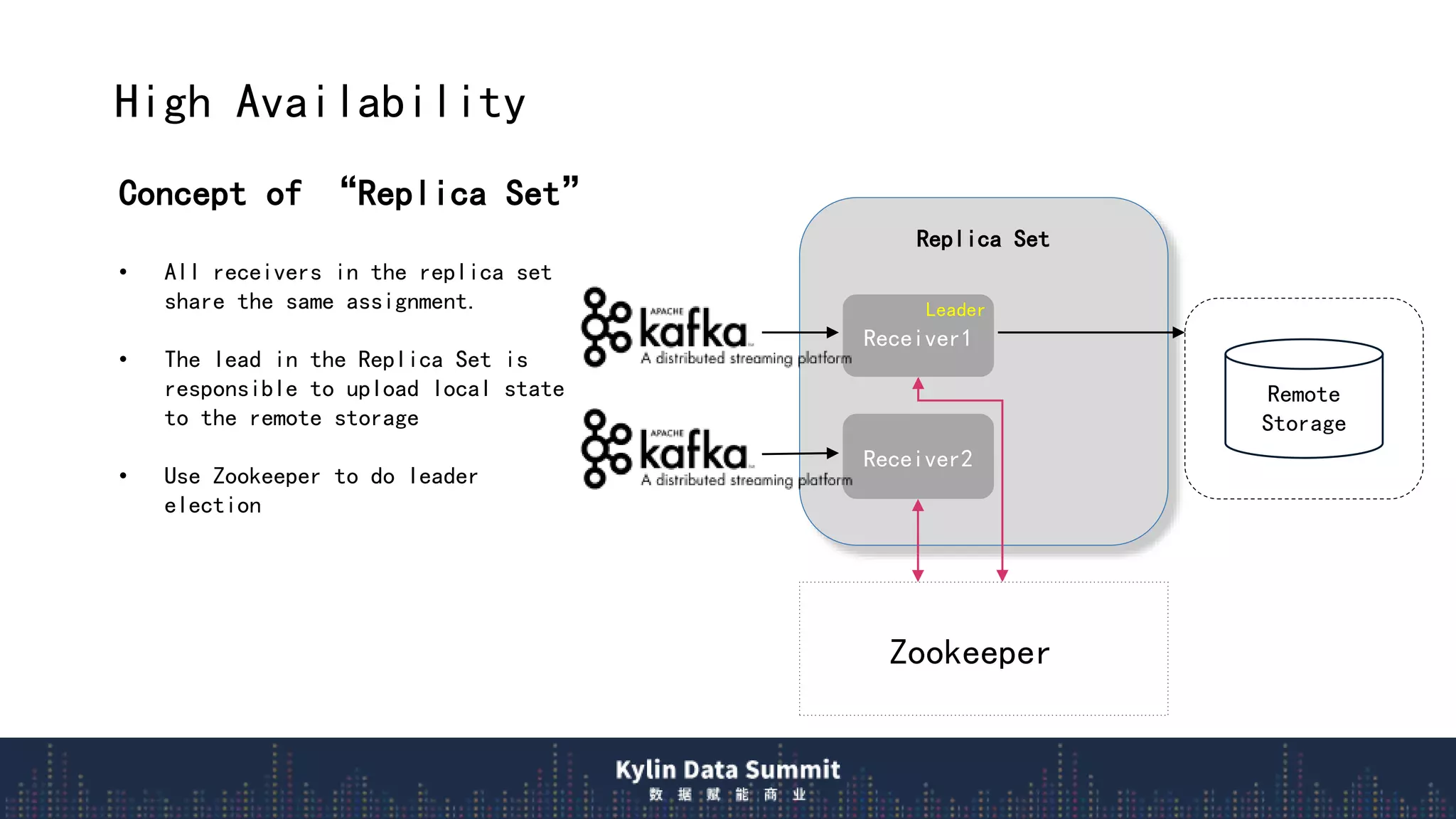
2) The data flow uses streaming receivers to aggregate streaming events in memory and flush to local disk in real-time segments before uploading to remote storage.
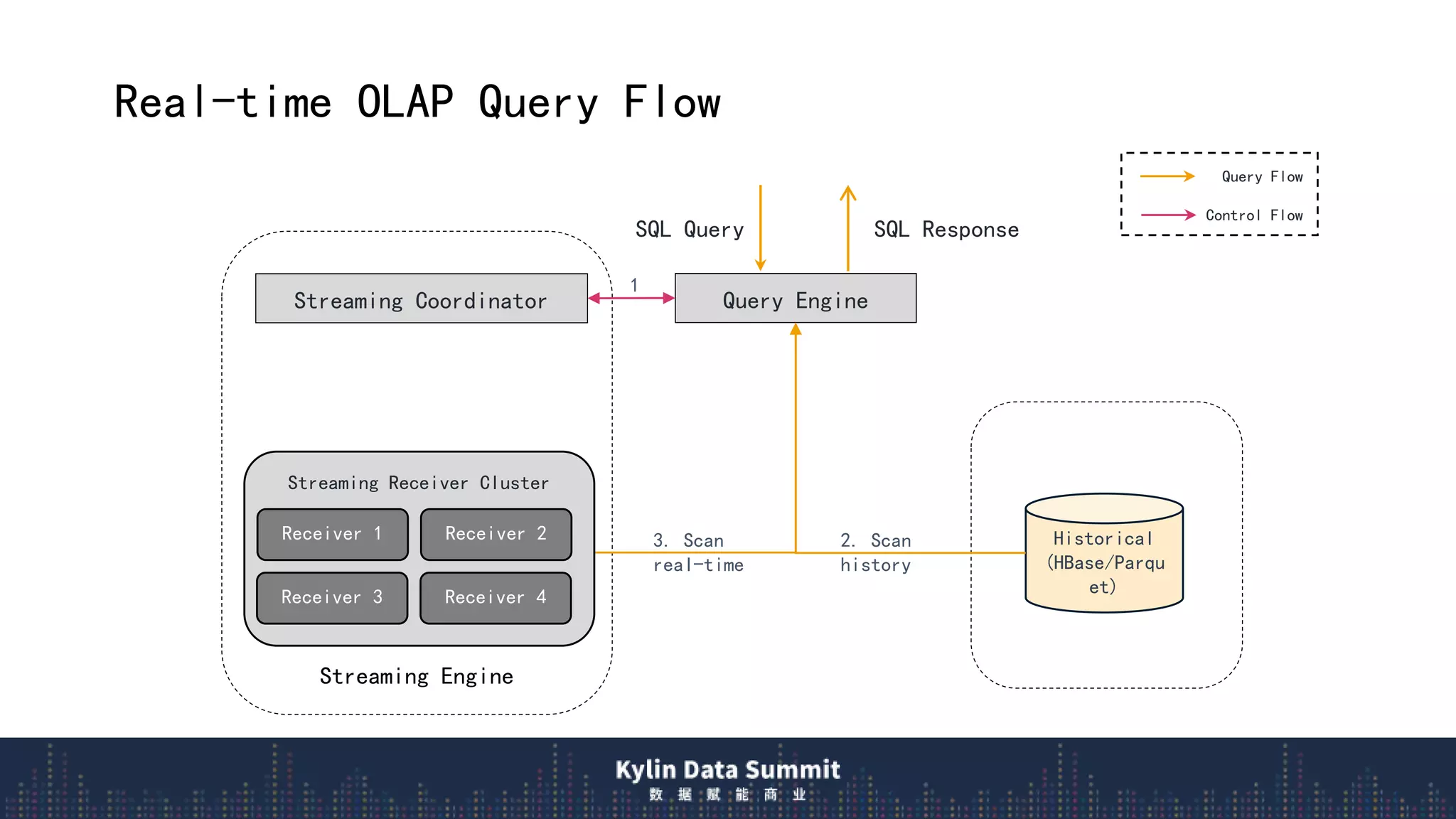
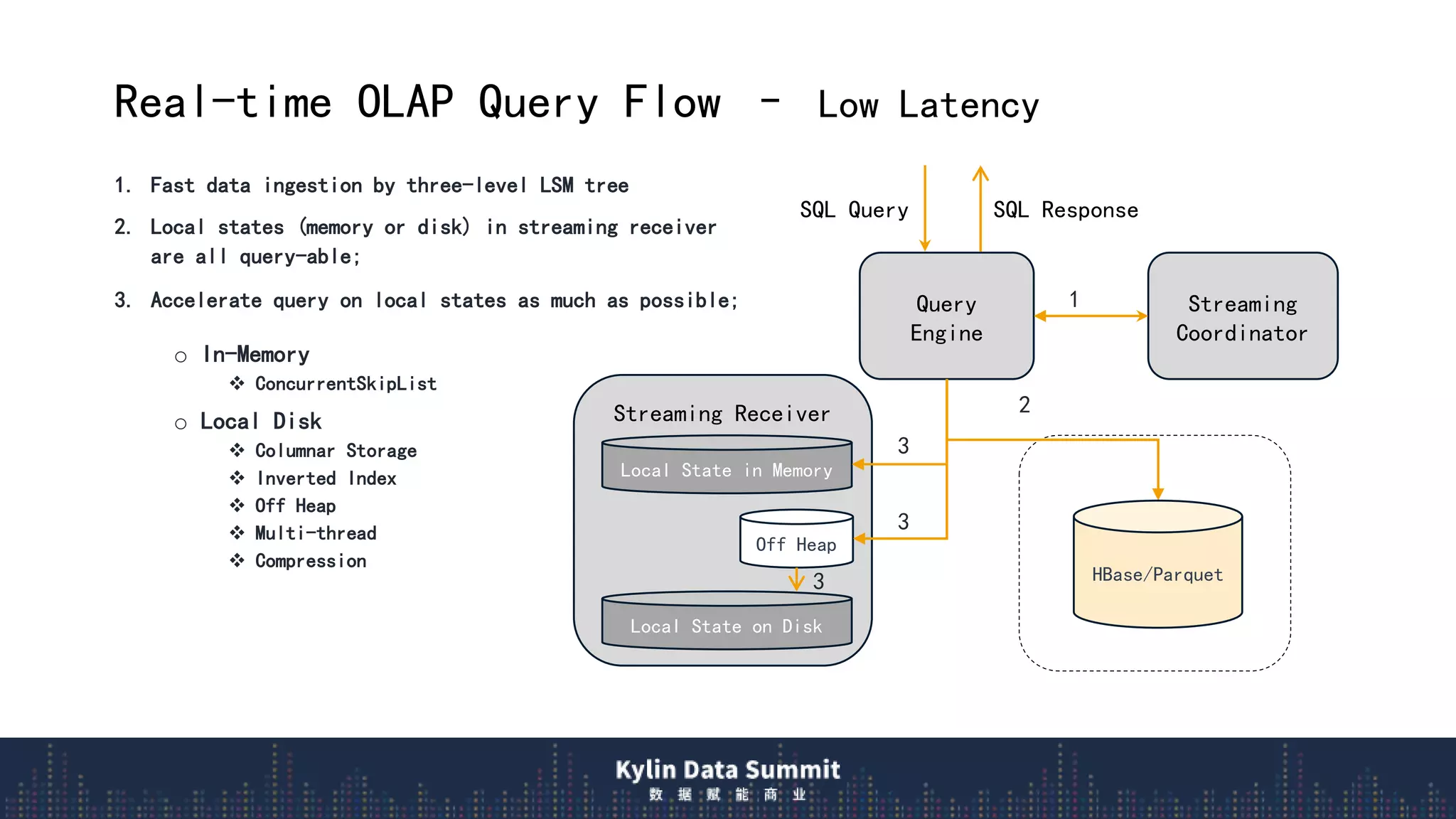
3) The query flow scans local real-time segments for low latency before querying remote historical data, providing millisecond responses over trillions of rows.


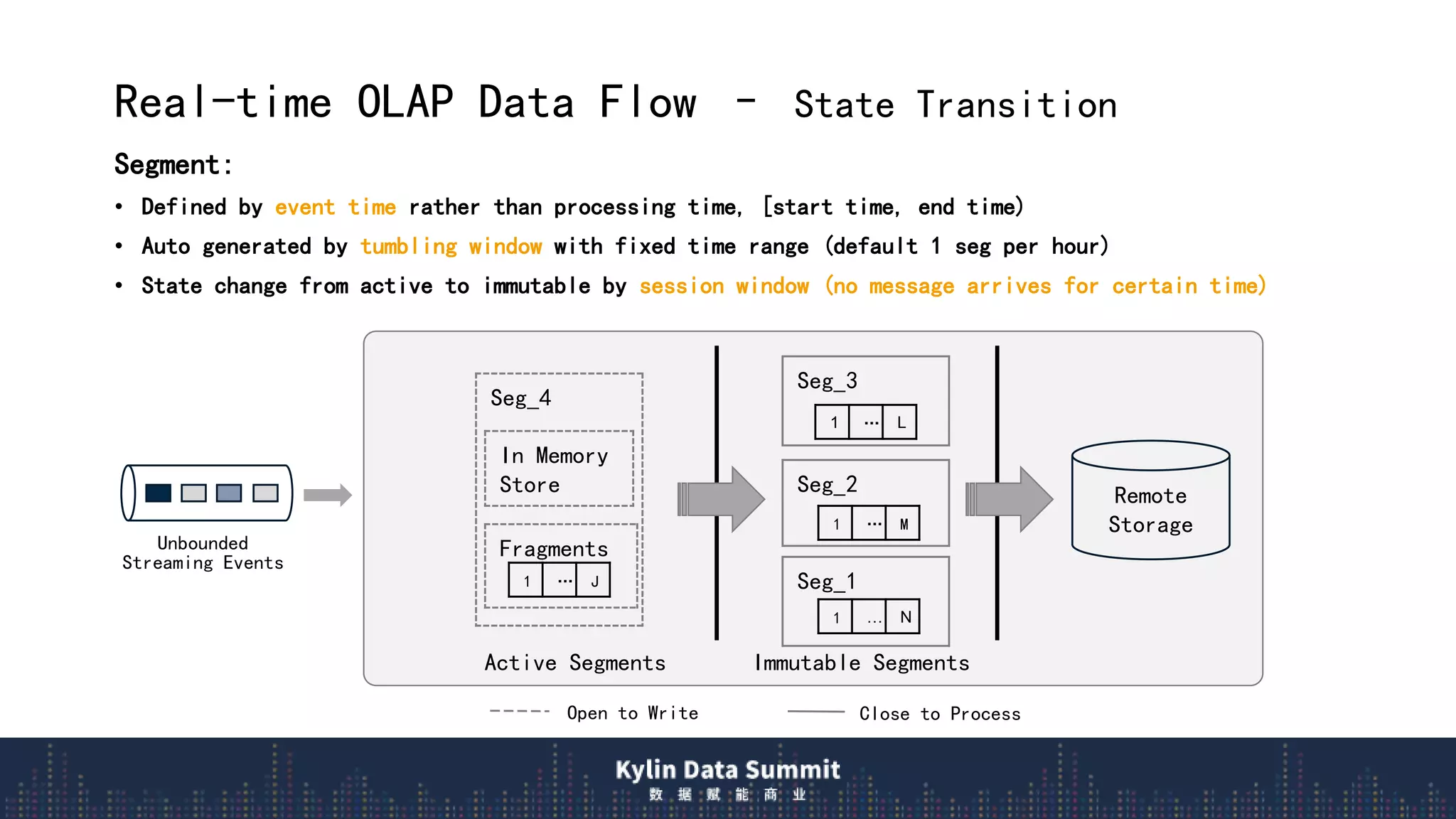
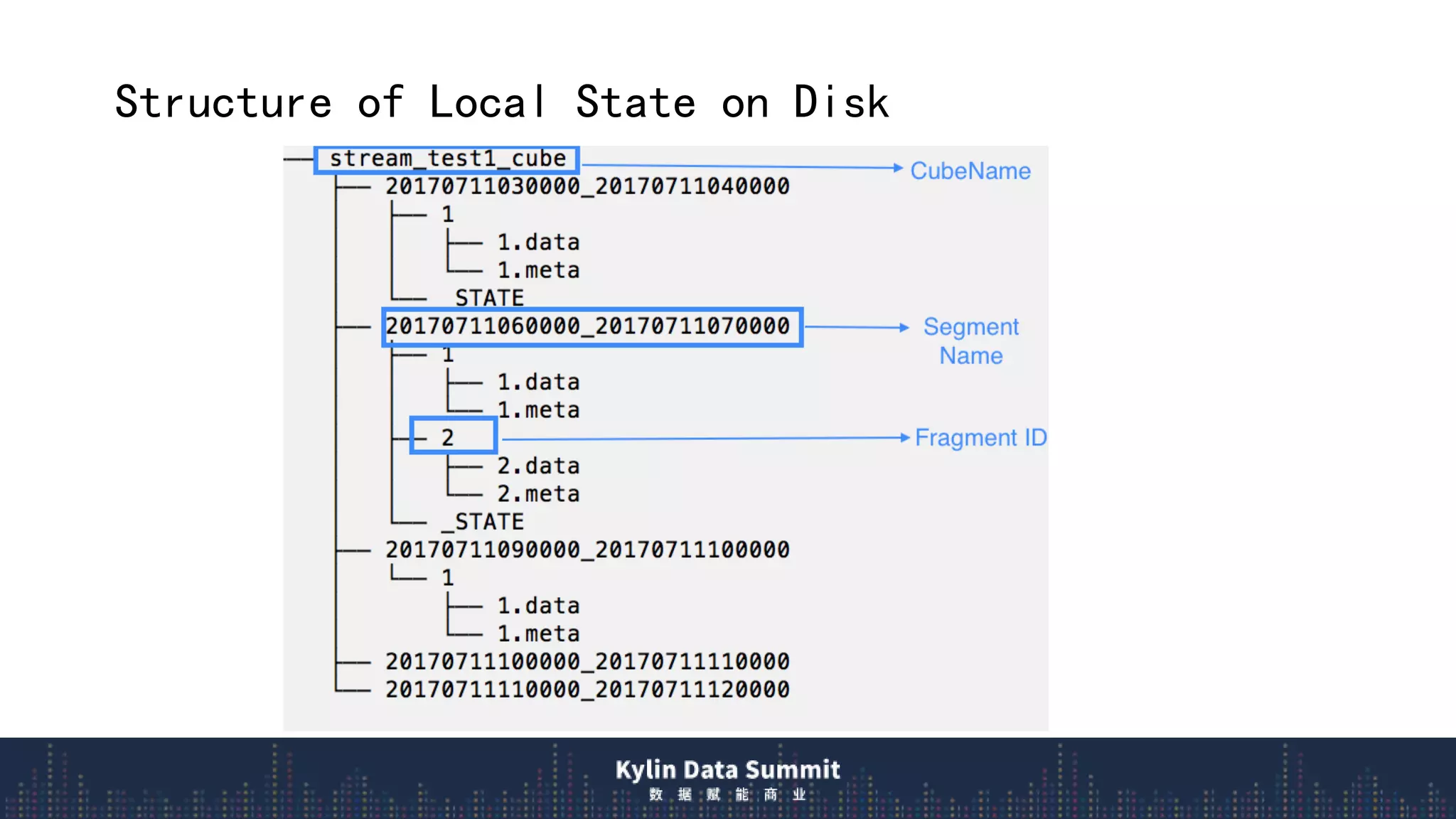
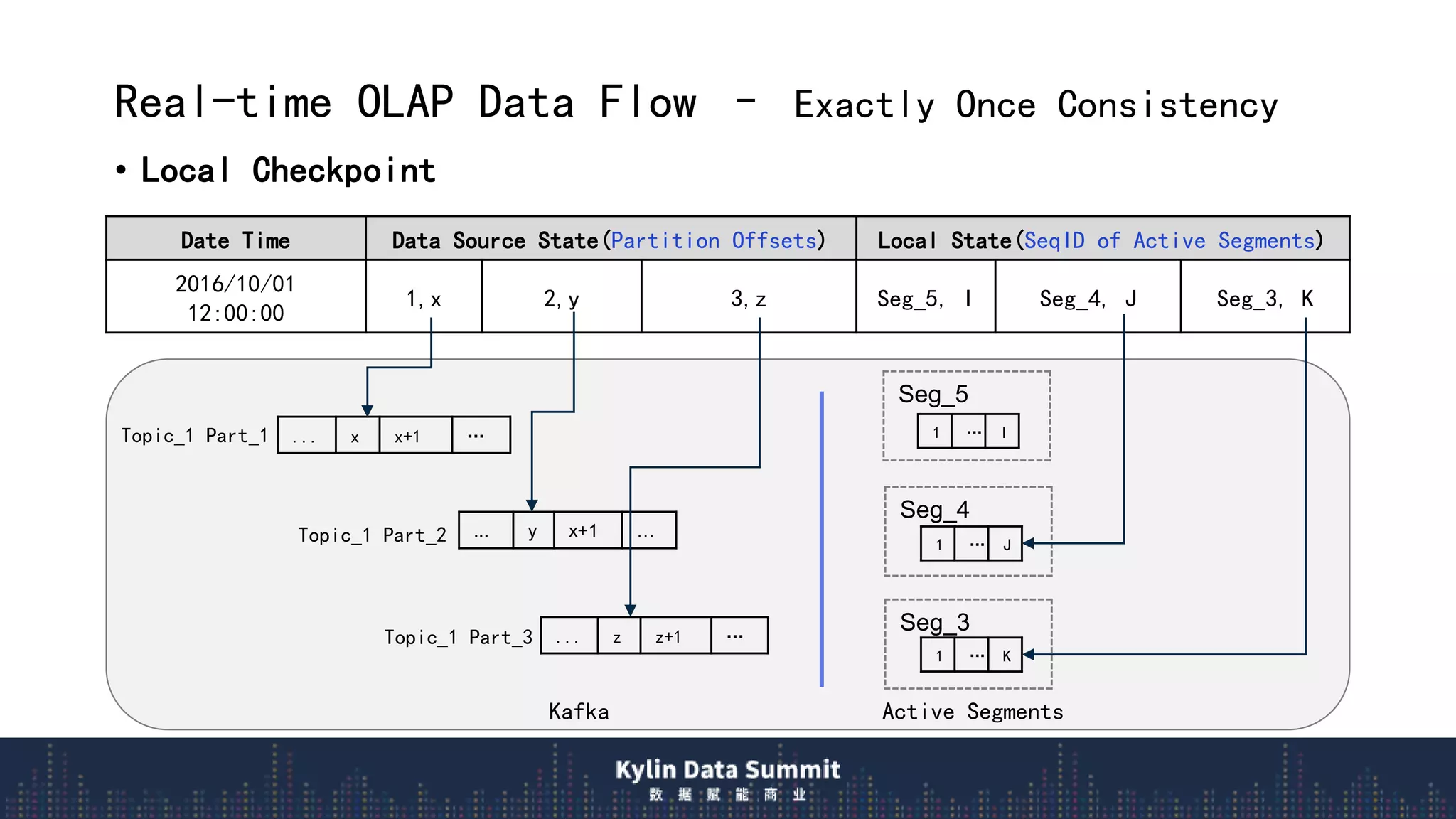
![Real-time OLAP Data Flow – Exactly Once Consistency
• Remote Checkpoint
o Checkpoint is saved to Cube Segment metadata after HBase segment be built
“segments”:[{…,
"stream_source_checkpoint": {"0":8946898241, “1”: 8193859535, ...}
},
]
o The checkpoint info is the smallest/earliest partition offsets on the streaming receiver
when real-time segment is sent to full build.](https://image.slidesharecdn.com/realtimeolaparchitectureinapachekylin3-190808052428/75/Realtime-olap-architecture-in-apache-kylin-3-0-10-2048.jpg)


































![[WSO2Con EU 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/1-181113084942-thumbnail.jpg?width=640&height=640&fit=bounds)




![[WSO2Con USA 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/wso2conusa2018theriseofstreamingsql-180717041454-thumbnail.jpg?width=640&height=640&fit=bounds)








![[ODSC EUROPE 2022] Eagleeye - Data Pipeline for Anomaly Detection in Cyber Se...](https://cdn.slidesharecdn.com/ss_thumbnails/odsceurope2022eagleeye-datapipelineforanomalydetectionincybersecurity-250320161155-77fa6dd8-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)


