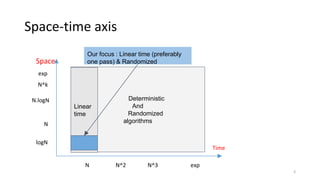
1) The document discusses algorithms for computing statistics like minimum, maximum, average over data streams using limited memory in a single pass. It covers algorithms for computing cardinality, heavy hitters, order statistics and histograms.
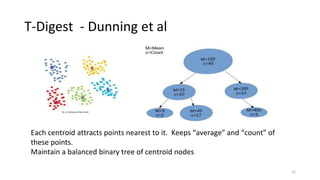
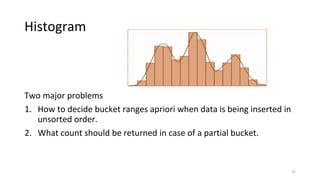
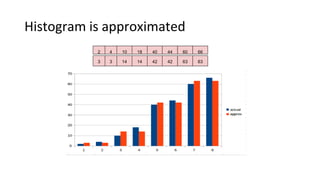
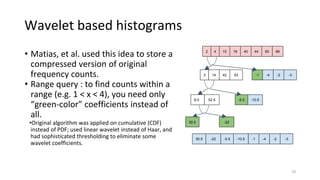
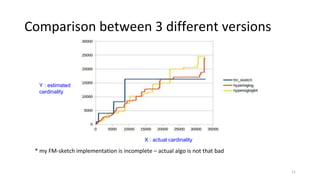
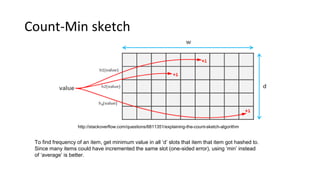
2) Cardinality can be estimated using the Flajolet-Martin algorithm which tracks the position of the rightmost zero bit in a bitmap. Heavy hitters can be found using the Count-Min sketch. Order statistics like the median can be approximated using the Frugal and T-Digest algorithms. Wavelet-based approaches can be used to compute histograms over data streams.
3) The document provides high-level explanations of these streaming algorithms along with references for further reading, but does not







![Bit patterns
For num = [1, 1000]
h = hash(num)
Number of hashes ending in Out of 1000
0 530
10 281
100 140
1000 53
10000 28
100000 9
1000000 12
10000000 5
100000000 2
1000000000 0
10000000000 0
100000000000 0
8
Bit ‘1’ followed by 9 or
more zeroes not found
Because 1000 ~ 2^10](https://image.slidesharecdn.com/datastreamingalgorithms-160901054312/85/Data-streaming-algorithms-8-320.jpg)
![Flajolet-Martin sketch algo
1. For each item
2. Index = rightmost bit in hash(item)
3. Bitmap[index] = 1
(at this point, bitmap = “000...00000101011111”)
1. Estimated N ~ 2 rightmost ‘0’ bit in bitmap
9
Further improvements : split stream into M substreams and use harmonic mean of their
counters, use 64-bit hash instead of 32, add custom correction factors to hash at low and high
range.](https://image.slidesharecdn.com/datastreamingalgorithms-160901054312/85/Data-streaming-algorithms-9-320.jpg)
![Why it works
• The number of distinct items can be roughly estimated by the
position of the rightmost 0-bit.
• A randomized algorithm which takes sublinear space - number of bits
is equal to log2(n)
• Algorithm also works over strings [ 1985 paper uses strings ]
• Any set of bits can be used [ hyperloglog uses middle bits]
10](https://image.slidesharecdn.com/datastreamingalgorithms-160901054312/85/Data-streaming-algorithms-10-320.jpg)



![Heavy Hitters – Karp, et al
1. Keep a frequency Map<item, count>
2. For each v in sequence
3. increment Map[v].count
4. If map.size() > threshold
5. for each element in Map
6. decrement Map[element].count
7. if count is zero, delete Map[element]
Algo has second pass to adjust counts. Paper discusses additional optimizations.
Implemented in Apache Spark. See DataFrameStatFunctions.freqItems().
Maintain a truncated histogram
15](https://image.slidesharecdn.com/datastreamingalgorithms-160901054312/85/Data-streaming-algorithms-15-320.jpg)


![Order statistics terminology
Given sorted sequence [1, 1, 1, 2, 3]
1. 0-quantile = minimum
2. 0.25 quantile = 1st quartile = 25 percentile
3. 0.50 quantile = 2nd quartile = 50 percentile = median
4. 0.75 quantile = 3rd quartile = 75 percentile
5. 1-quantile = maximum
19](https://image.slidesharecdn.com/datastreamingalgorithms-160901054312/85/Data-streaming-algorithms-19-320.jpg)