Download as PDF, PPTX











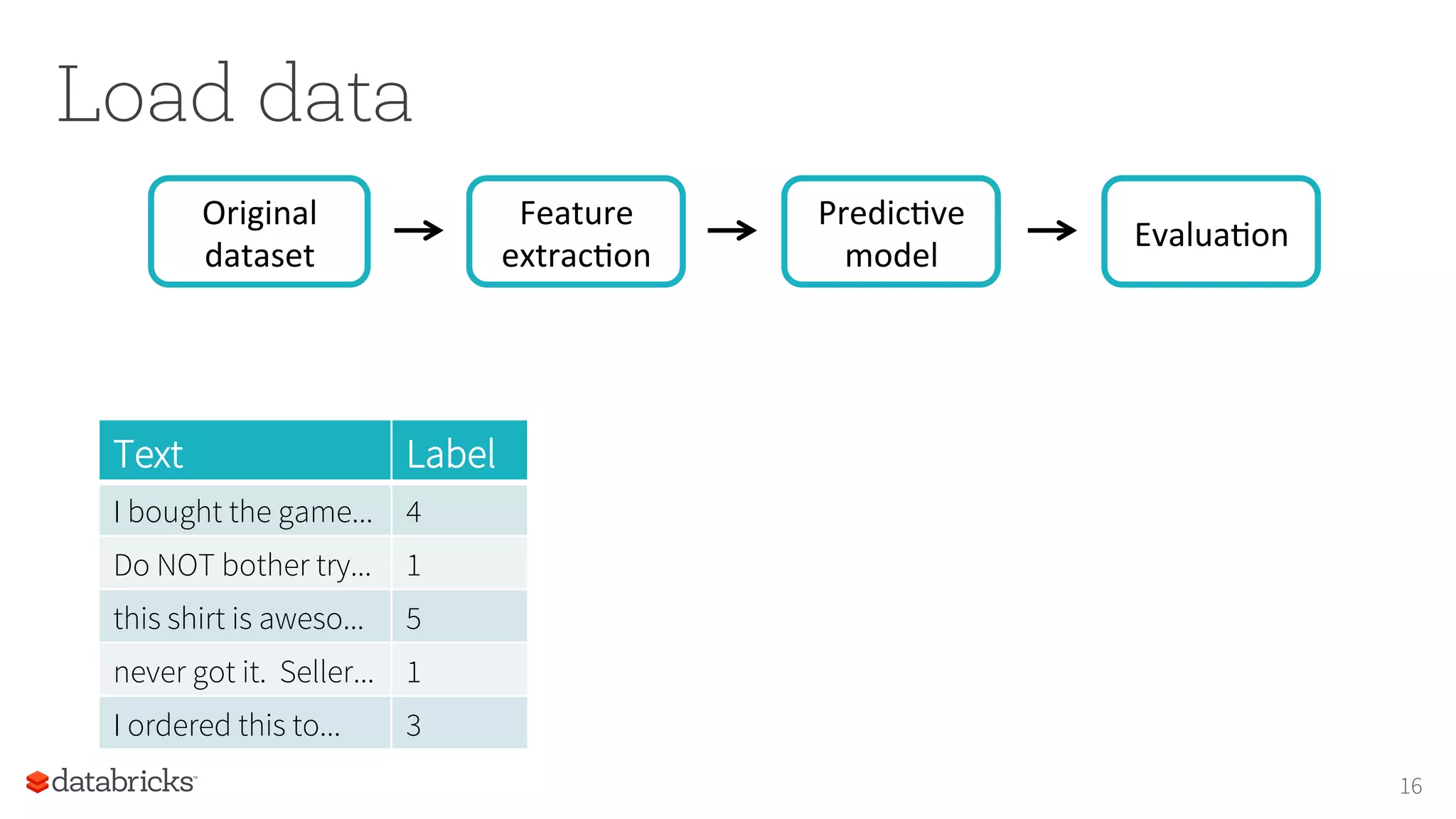
![Extract features
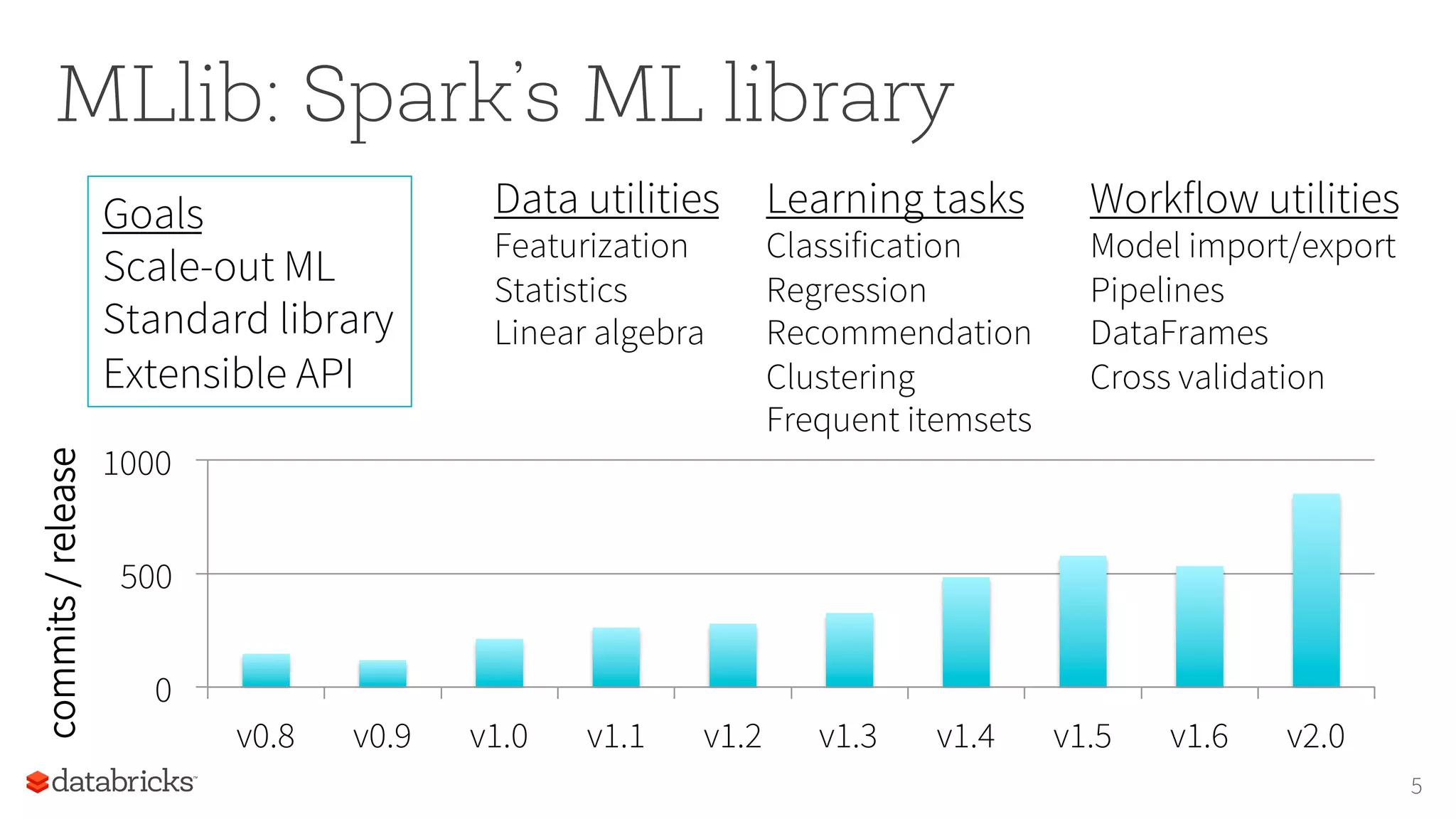
Feature
extracIon
Original
dataset
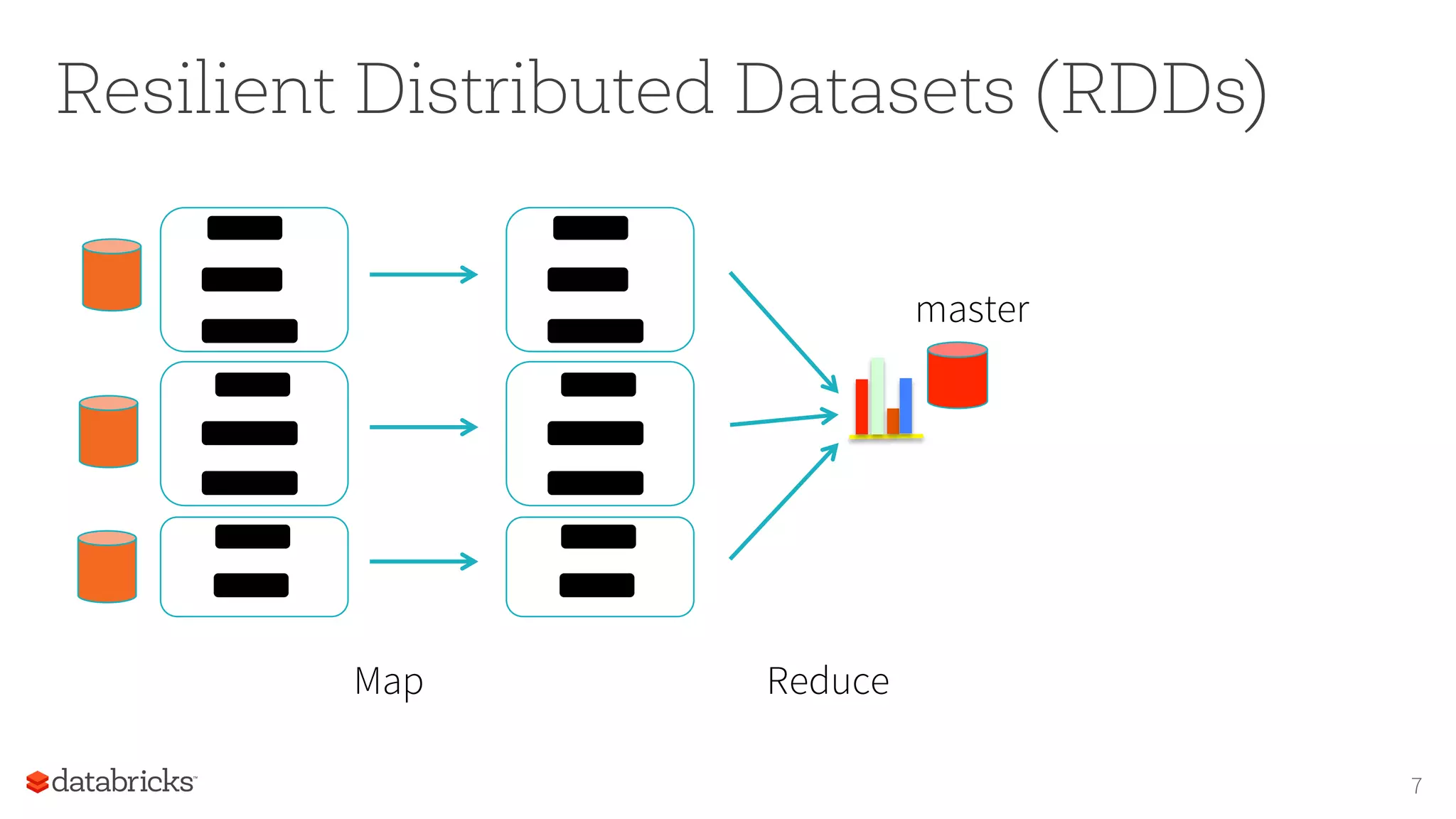
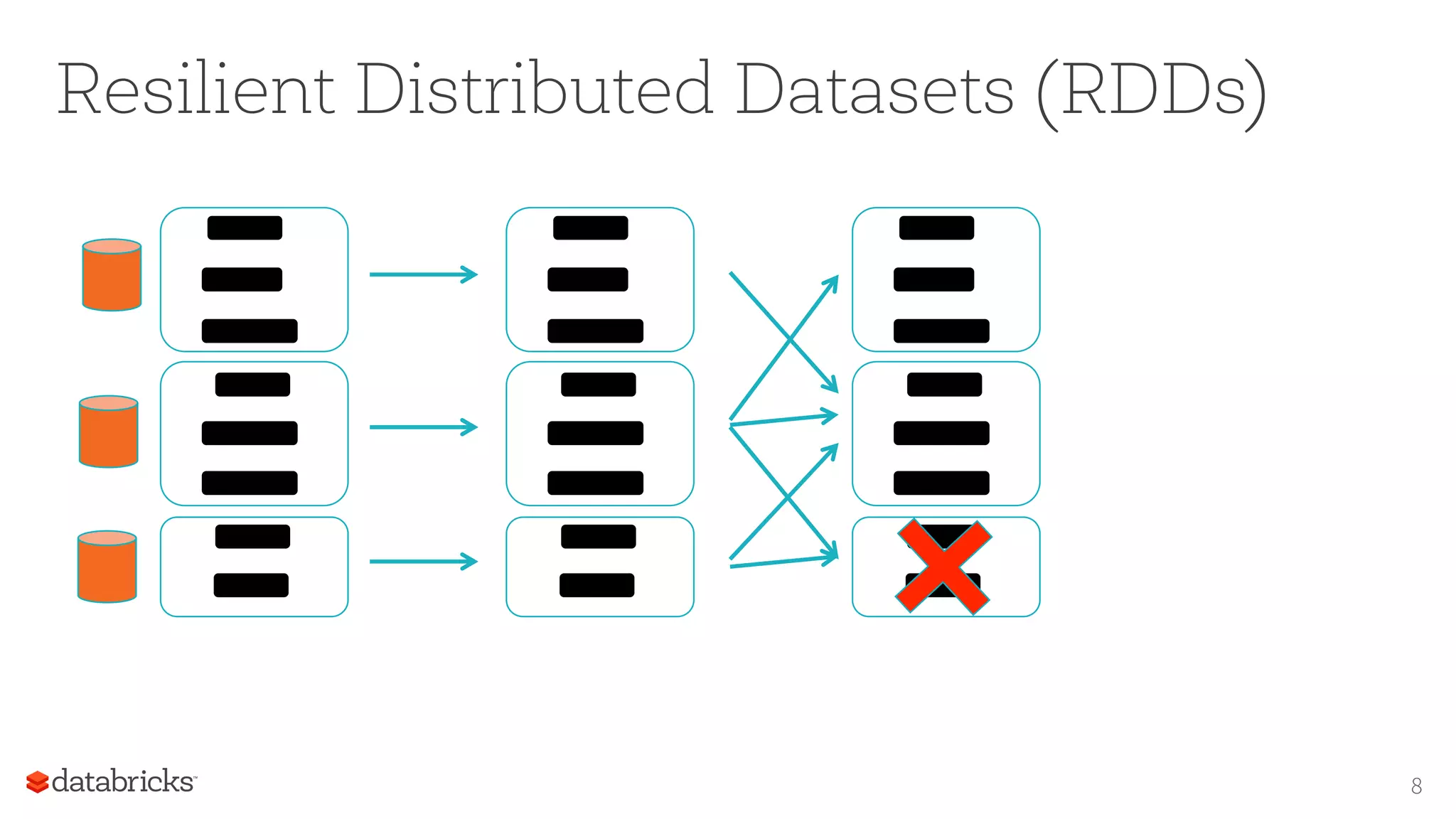
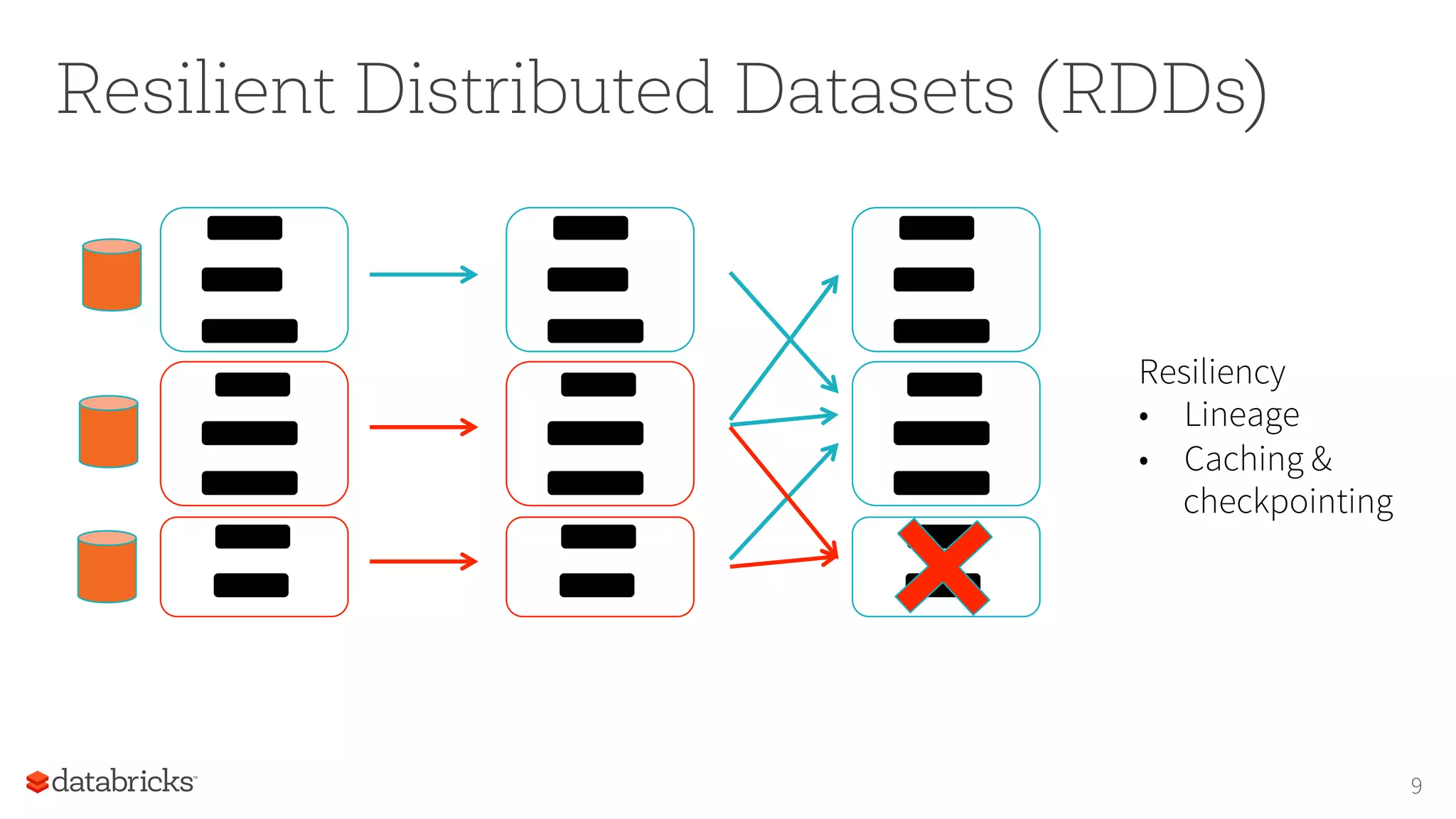
17
PredicIve
model
EvaluaIon
Text Label Words Features
I bought the game... 4 “i", “bought”,... [1, 0, 3, 9, ...]
Do NOT bother try... 1 “do”, “not”,... [0, 0, 11, 0, ...]
this shirt is aweso... 5 “this”, “shirt” [0, 2, 3, 1, ...]
never got it. Seller... 1 “never”, “got” [1, 2, 0, 0, ...]
I ordered this to... 3 “i”, “ordered” [1, 0, 0, 3, ...]](https://image.slidesharecdn.com/16-08-14kddbigmine16talk-160814212853/75/Foundations-for-Scaling-ML-in-Apache-Spark-by-Joseph-Bradley-at-BigMine16-17-2048.jpg)
![Fit a model
Feature
extracIon
Original
dataset
18
PredicIve
model
EvaluaIon
Text Label Words Features Prediction Probability
I bought the game... 4 “i", “bought”,... [1, 0, 3, 9, ...] 4 0.8
Do NOT bother try... 1 “do”, “not”,... [0, 0, 11, 0, ...] 2 0.6
this shirt is aweso... 5 “this”, “shirt” [0, 2, 3, 1, ...] 5 0.9
never got it. Seller... 1 “never”, “got” [1, 2, 0, 0, ...] 1 0.7
I ordered this to... 3 “i”, “ordered” [1, 0, 0, 3, ...] 4 0.7](https://image.slidesharecdn.com/16-08-14kddbigmine16talk-160814212853/75/Foundations-for-Scaling-ML-in-Apache-Spark-by-Joseph-Bradley-at-BigMine16-18-2048.jpg)
![Evaluate
Feature
extracIon
Original
dataset
19
PredicIve
model
EvaluaIon
Text Label Words Features Prediction Probability
I bought the game... 4 “i", “bought”,... [1, 0, 3, 9, ...] 4 0.8
Do NOT bother try... 1 “do”, “not”,... [0, 0, 11, 0, ...] 2 0.6
this shirt is aweso... 5 “this”, “shirt” [0, 2, 3, 1, ...] 5 0.9
never got it. Seller... 1 “never”, “got” [1, 2, 0, 0, ...] 1 0.7
I ordered this to... 3 “i”, “ordered” [1, 0, 0, 3, ...] 4 0.7](https://image.slidesharecdn.com/16-08-14kddbigmine16talk-160814212853/75/Foundations-for-Scaling-ML-in-Apache-Spark-by-Joseph-Bradley-at-BigMine16-19-2048.jpg)



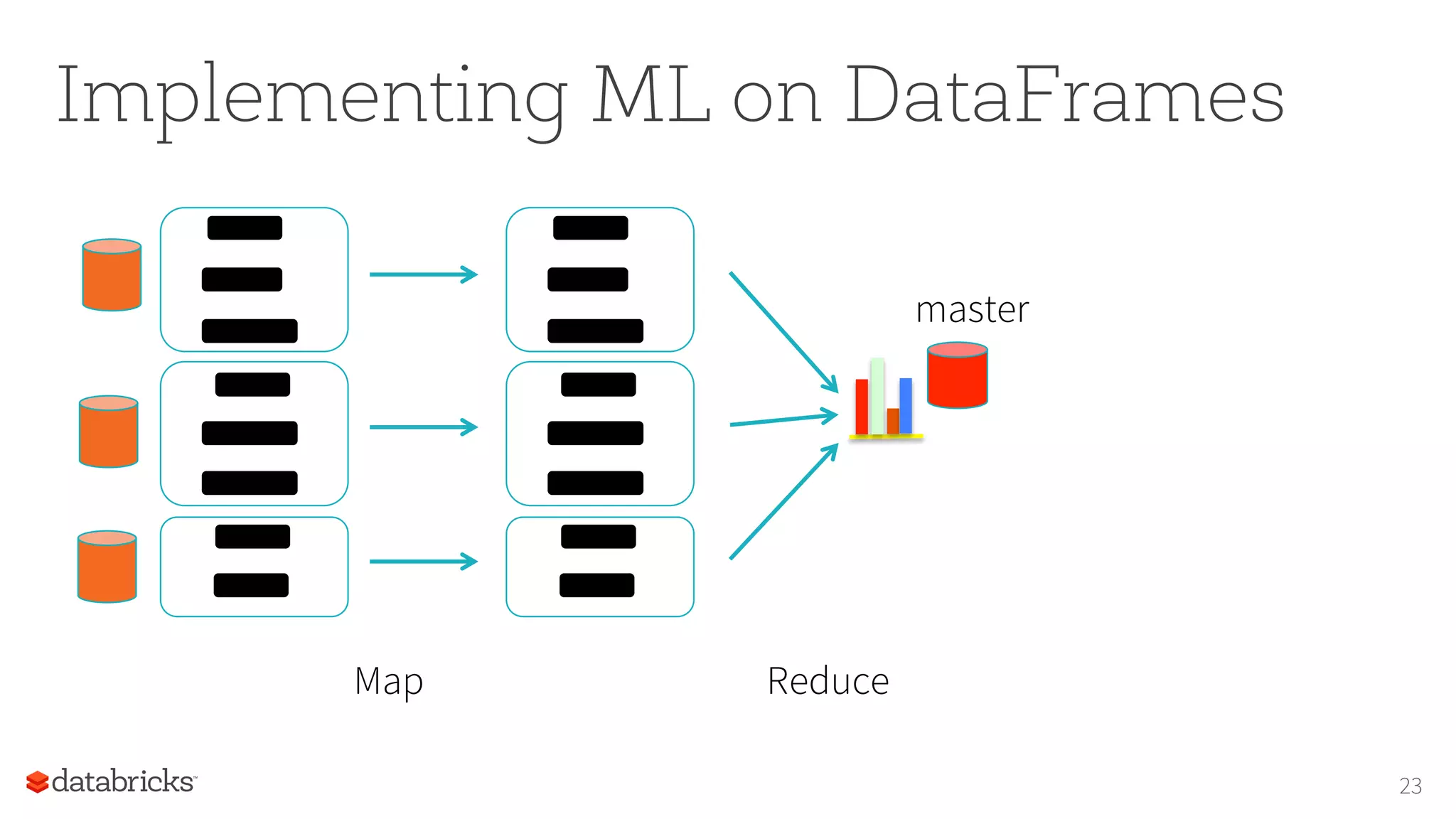


![Tungsten in ML
Tungsten: off-heap memory management
• Avoids JVM GC
• Uses efficient storage formats
• Code generation
26
Issue in ML:
object creation during each iteration
Issue in ML:
Array[(Int,Double,Double)]
Issue in ML:
Volcano iterator model in MR/RDDs](https://image.slidesharecdn.com/16-08-14kddbigmine16talk-160814212853/75/Foundations-for-Scaling-ML-in-Apache-Spark-by-Joseph-Bradley-at-BigMine16-26-2048.jpg)






The document discusses the foundations for scaling machine learning (ML) within Apache Spark, highlighting its capabilities for big data computing through features like Resilient Distributed Datasets (RDDs), DataFrames, and the ML library. It addresses challenges faced with RDDs for scalability while presenting the advantages of transitioning to DataFrames, which optimize performance and simplify algorithm development. The future of ML in Spark focuses on efficient scaling and improved usability through better resource management and optimization techniques.







































![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)

