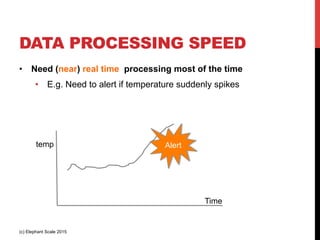
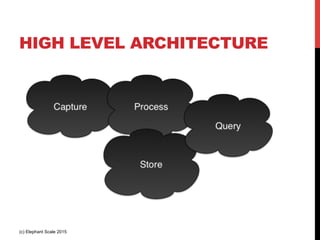
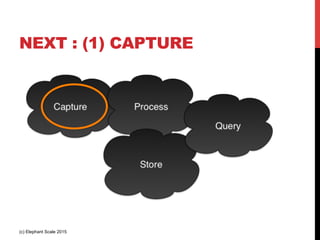
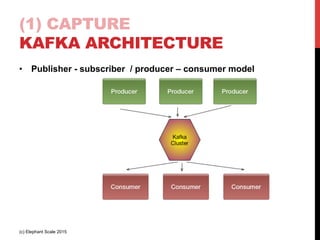
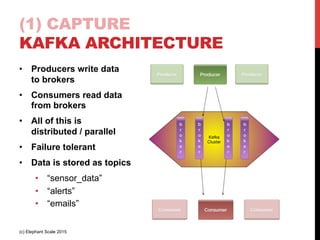
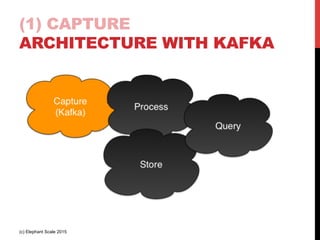
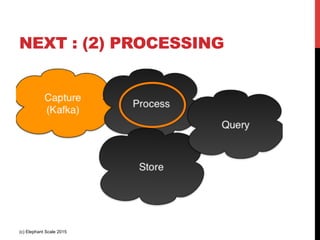
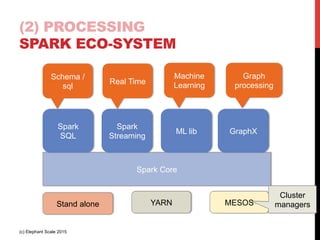
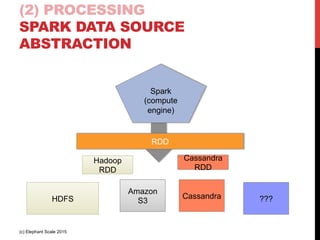
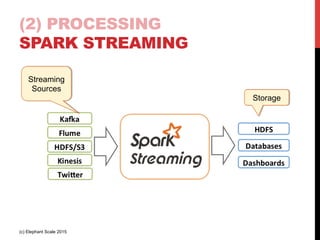
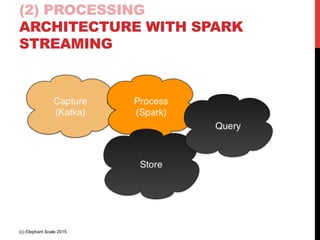
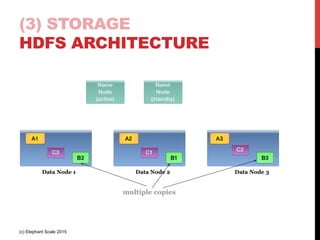
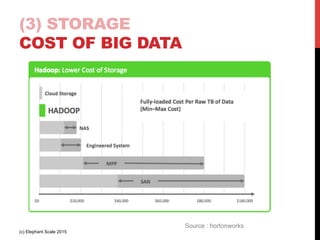
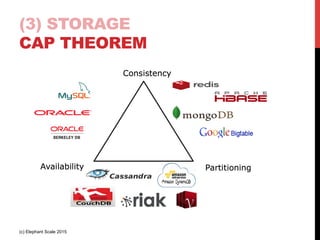
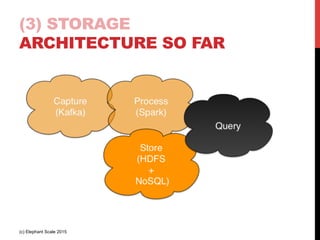
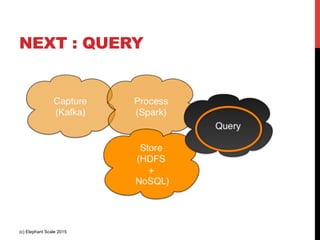
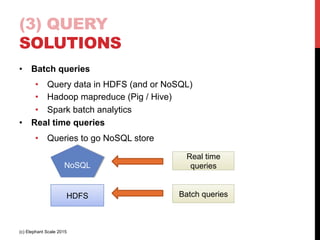
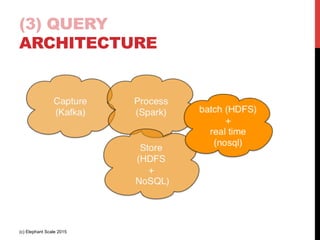
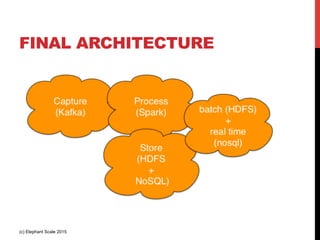
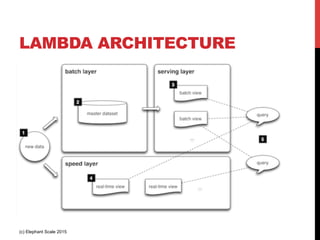
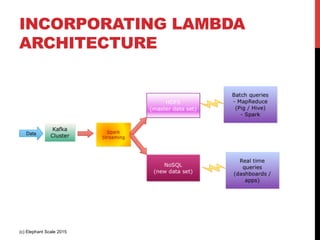
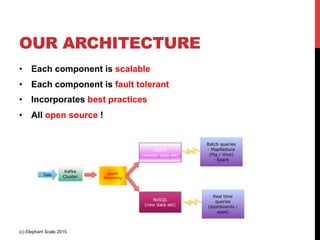
The document outlines a reference architecture for the Internet of Things (IoT), highlighting the need for efficient data capture, processing, storage, and querying. It discusses the use of various technologies such as Apache Kafka for data capture, Apache Spark for processing, and Hadoop for storage, addressing real-time data handling and the scalability challenges associated with big data. The proposed architecture incorporates best practices and emphasizes an open-source approach to build a robust IoT data platform.





































































![Stampabile msn 2009 mobile camp def [modalità compatibilità]](https://cdn.slidesharecdn.com/ss_thumbnails/stampabilemsn2009mobilecampdefmodalitcompatibilit-100906111342-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















































