Download as PDF, PPTX











![Basic direct stream API
14
val stream: InputDStream[(String, String)] =
KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
streamingContext,
// kafka config parameters
Map(
"metadata.broker.list" -> "localhost:9092,anotherhost:9092"),
"auto.offset.reset" -> "largest"
),
// set of topics to consume
Set("sometopic", "anothertopic")
)](https://image.slidesharecdn.com/ko0lbyxaqnahx8hfk0vw-signature-9d21828b8995bb45daf6bd98ae827dae2f0010efa3f03f445d719c9fcbe7ef93-poli-150624002406-lva1-app6891/85/Exactly-Once-Streaming-from-Kafka-Cody-Koeninger-Kixer-14-320.jpg)



![Your own data store
18
val stream: InputDStream[Int] =
KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder,
Int](
streamingContext,
Map("metadata.broker.list" -> “localhost:9092,anotherhost:9092"),
// map of starting offsets, would be read from your storage in real code
Map(TopicAndPartition(“someTopic”, 0) -> someStartingOffset,
TopicAndPartition(“anotherTopic”, 0) -> anotherStartingOffset),
// message handler to get desired value from each message and metadata
(mmd: MessageAndMetadata[String, String]) => mmd.message.length
)](https://image.slidesharecdn.com/ko0lbyxaqnahx8hfk0vw-signature-9d21828b8995bb45daf6bd98ae827dae2f0010efa3f03f445d719c9fcbe7ef93-poli-150624002406-lva1-app6891/85/Exactly-Once-Streaming-from-Kafka-Cody-Koeninger-Kixer-18-320.jpg)
![Accessing offsets, per message
19
val messageHandler =
(mmd: MessageAndMetadata[String, String]) =>
(mmd.topic, mmd.partition, mmd.offset, mmd.key, mmd.message)
Your message handler has full access to all of the metadata.
Saving offsets per message may not be efficient, though.](https://image.slidesharecdn.com/ko0lbyxaqnahx8hfk0vw-signature-9d21828b8995bb45daf6bd98ae827dae2f0010efa3f03f445d719c9fcbe7ef93-poli-150624002406-lva1-app6891/85/Exactly-Once-Streaming-from-Kafka-Cody-Koeninger-Kixer-19-320.jpg)
![Accessing offsets, per batch
20
stream.foreachRDD { rdd =>
// Cast the rdd to an interface that lets us get an array of OffsetRange
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
val results = rdd.someTransformationUsingSparkMethods
...
// Your save method. Note that this runs on the driver
mySaveBatch(offsetRanges, results)
}](https://image.slidesharecdn.com/ko0lbyxaqnahx8hfk0vw-signature-9d21828b8995bb45daf6bd98ae827dae2f0010efa3f03f445d719c9fcbe7ef93-poli-150624002406-lva1-app6891/85/Exactly-Once-Streaming-from-Kafka-Cody-Koeninger-Kixer-20-320.jpg)
![Accessing offsets, per partition
21
stream.foreachRDD { rdd =>
// Cast the rdd to an interface that lets us get an array of OffsetRange
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd.foreachPartition { iter =>
// index to get the correct offset range for the rdd partition we're working on
val offsetRange: OffsetRange = offsetRanges(TaskContext.get.partitionId)
val perPartitionResult = iter.someTransformationUsingScalaMethods
// Your save method. Note this runs on the executors.
mySavePartition(offsetRange, perPartitionResult)
}
}](https://image.slidesharecdn.com/ko0lbyxaqnahx8hfk0vw-signature-9d21828b8995bb45daf6bd98ae827dae2f0010efa3f03f445d719c9fcbe7ef93-poli-150624002406-lva1-app6891/85/Exactly-Once-Streaming-from-Kafka-Cody-Koeninger-Kixer-21-320.jpg)



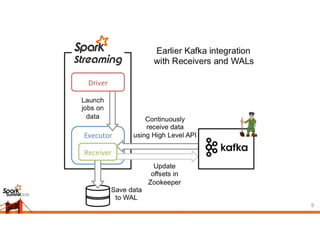
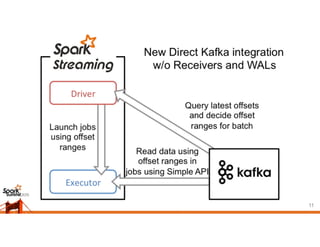
This document discusses different approaches for achieving exactly-once semantics when streaming data from Kafka using Spark Streaming. It presents idempotent and transactional approaches. The idempotent approach works for transformations that have a natural unique key, while the transactional approach works for any transformation by committing offsets and results together in a transaction. It also compares receiver-based and direct streaming, noting the pros and cons of each, and how to store offsets to enable exactly-once processing when using the direct approach.





























































![[Big Data Spain] Apache Spark Streaming + Kafka 0.10: an Integration Story](https://cdn.slidesharecdn.com/ss_thumbnails/bigdataspainapachesparkstreamingkafka0-171117095800-thumbnail.jpg?width=640&height=640&fit=bounds)













































