Download to read offline











![val rdd: RDD[String] =
sc.textFile(…)
val wordsRDD = rdd
.flatMap(line => line.split(" "))
val lengthHistogram = wordsRDD
.groupBy(word => word.length)
.collect
val aWords = wordsRDD
.filter(word =>
word.startsWith(“a”))
.saveAsHadoopFile(“hdfs://…”)
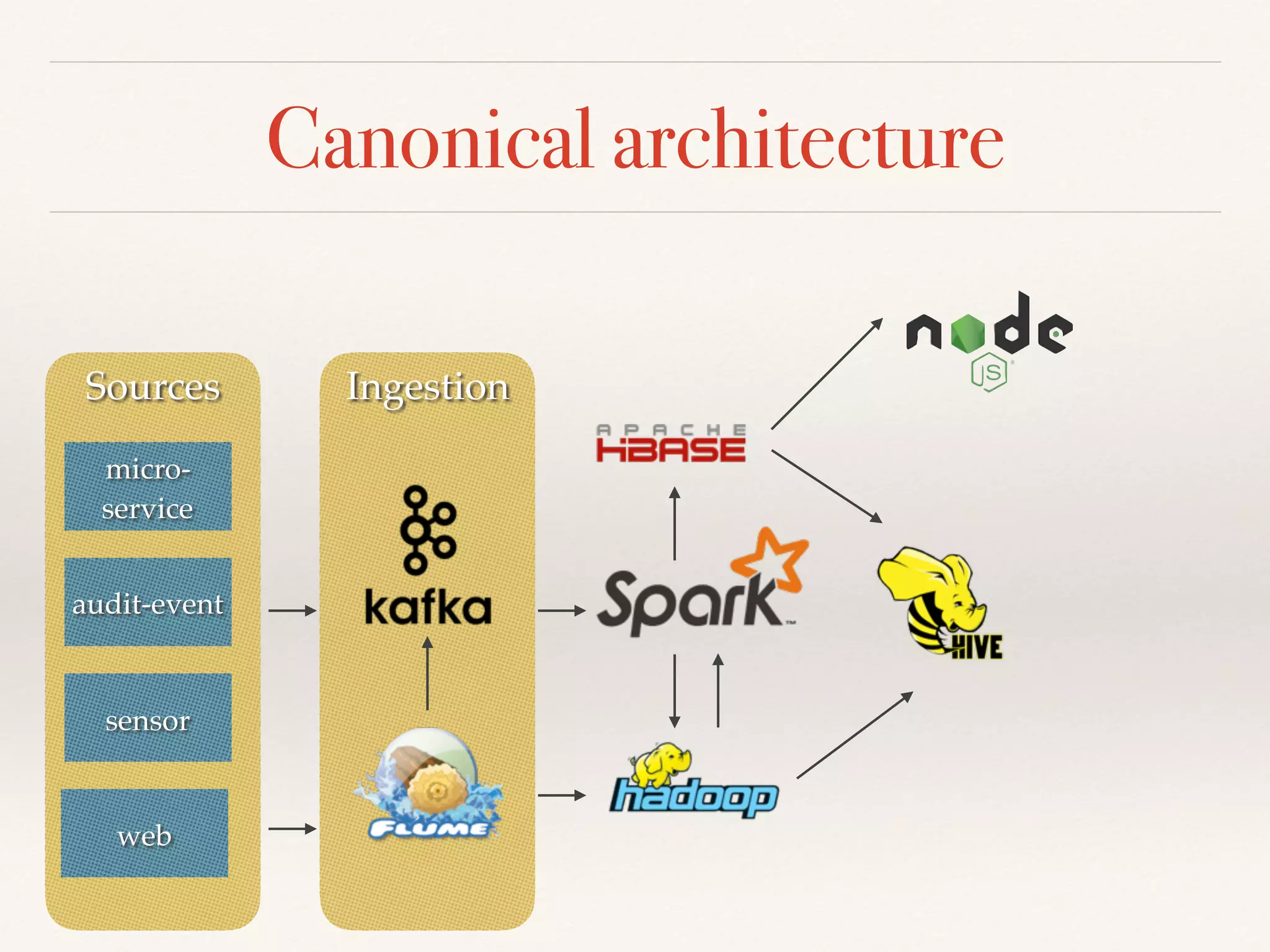
Meet DAG
B
C
E
D
F
A
B
C E
D F
A](https://image.slidesharecdn.com/a183f692-ec73-4b98-9fbc-ac2e9c1e62b9-160904112700/75/Apache-Spark-Streaming-14-2048.jpg)
![DStream
❖ Series of small and deterministic batch jobs
❖ Spark chops live stream into batches
❖ Each micro-batch processing produces a result
time [s]1 2 3 4 5 6
RDD1 RDD2 RDD3 RDD4 RDD5 RDD6](https://image.slidesharecdn.com/a183f692-ec73-4b98-9fbc-ac2e9c1e62b9-160904112700/75/Apache-Spark-Streaming-15-2048.jpg)
![val dstream: DStream[String] = …
val wordsStream = dstream
.flatMap(line => line.split(" "))
.transform(_.map(_.toUpper))
.countByValue()
.print()
Streaming program](https://image.slidesharecdn.com/a183f692-ec73-4b98-9fbc-ac2e9c1e62b9-160904112700/75/Apache-Spark-Streaming-16-2048.jpg)


![Stateful transformations
❖ Stateful transformation example
❖ Stateful DStream operators can have infinite lineages
❖ That leads to high failure-recovery time
❖ Spark solves that problem with checkpointing
val actions[(String, UserAction)] = …
val hotCategories =
actions.mapWithState(StateSpec.function(stateFunction))](https://image.slidesharecdn.com/a183f692-ec73-4b98-9fbc-ac2e9c1e62b9-160904112700/75/Apache-Spark-Streaming-20-2048.jpg)

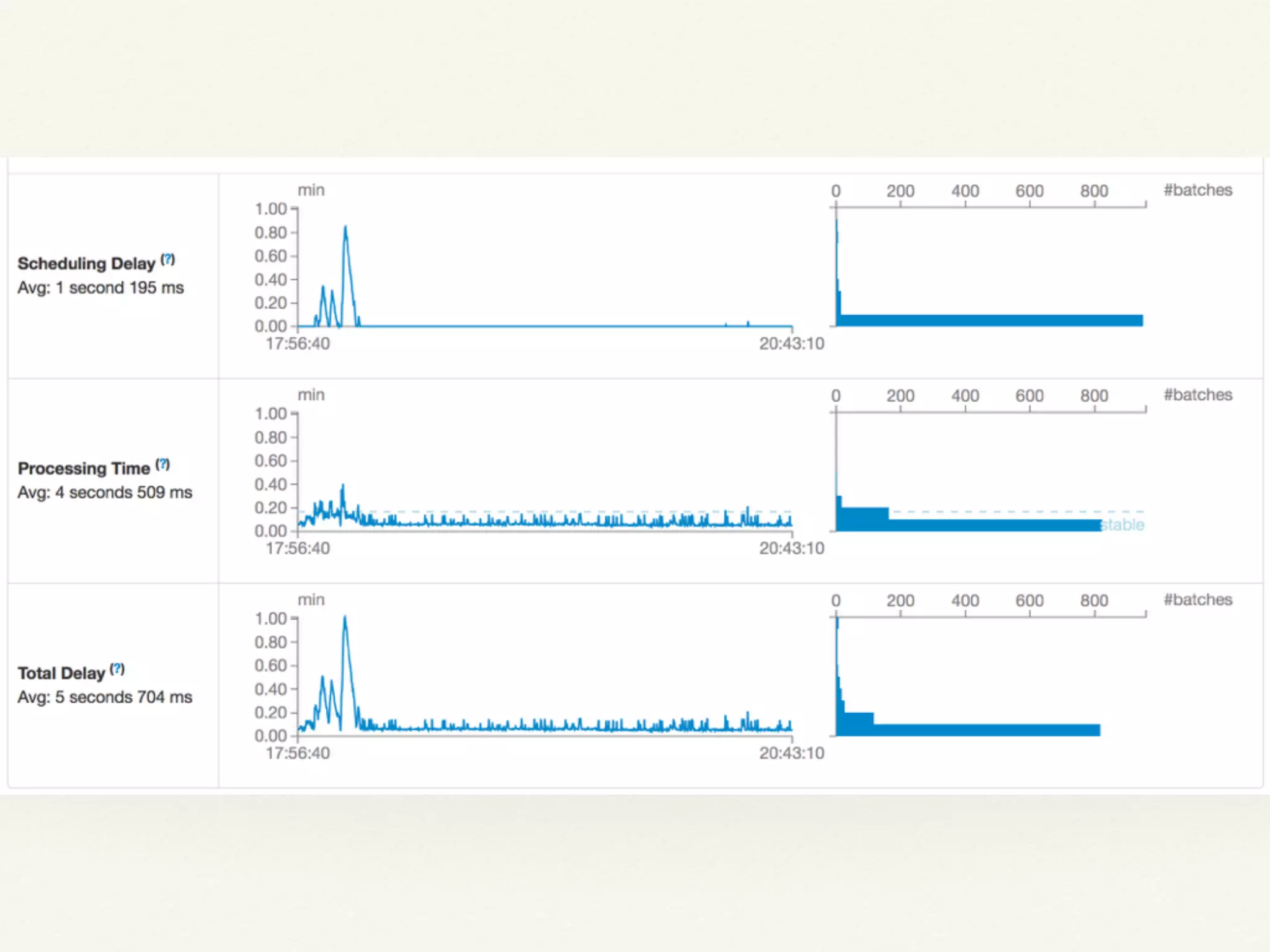
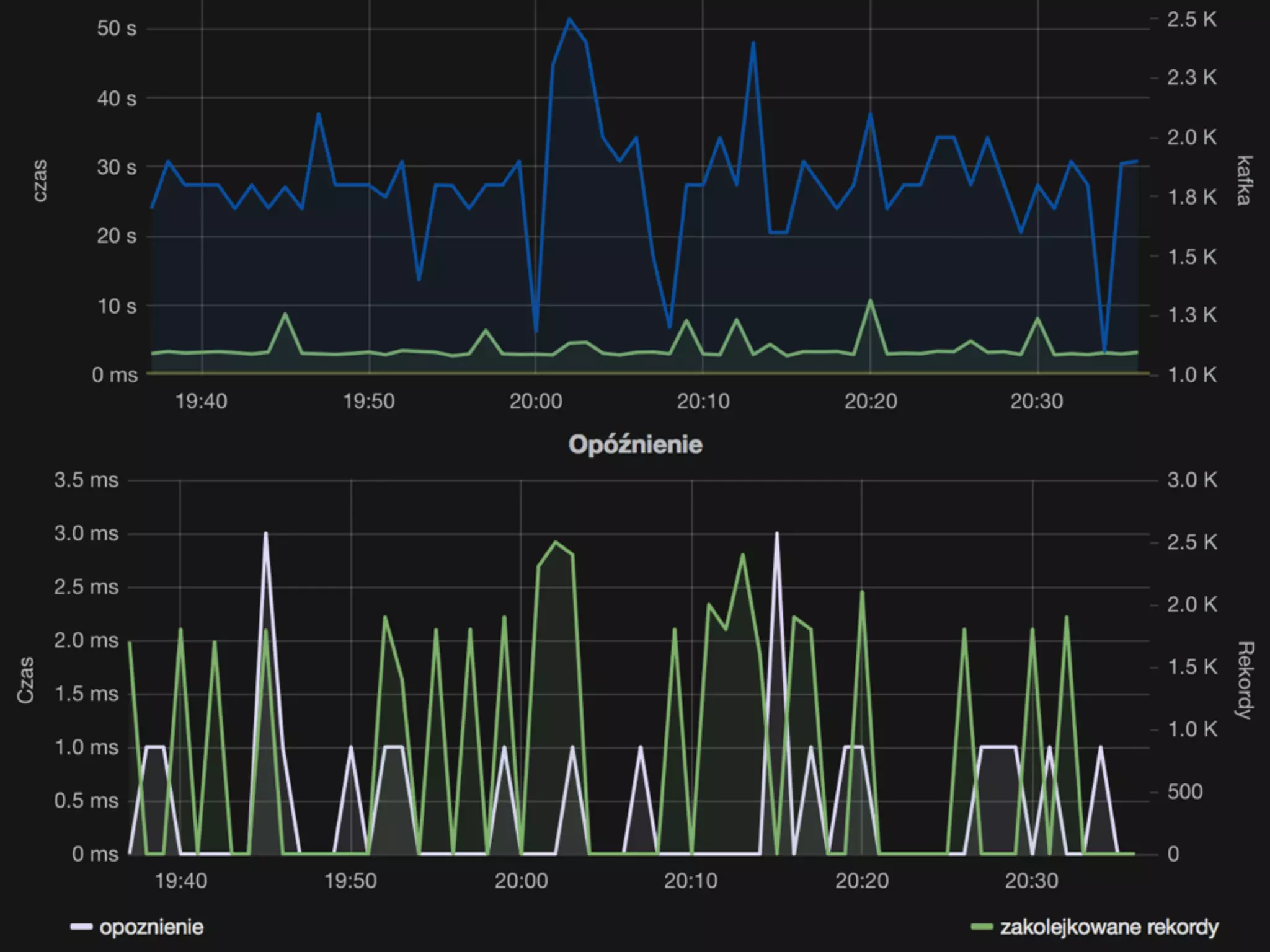
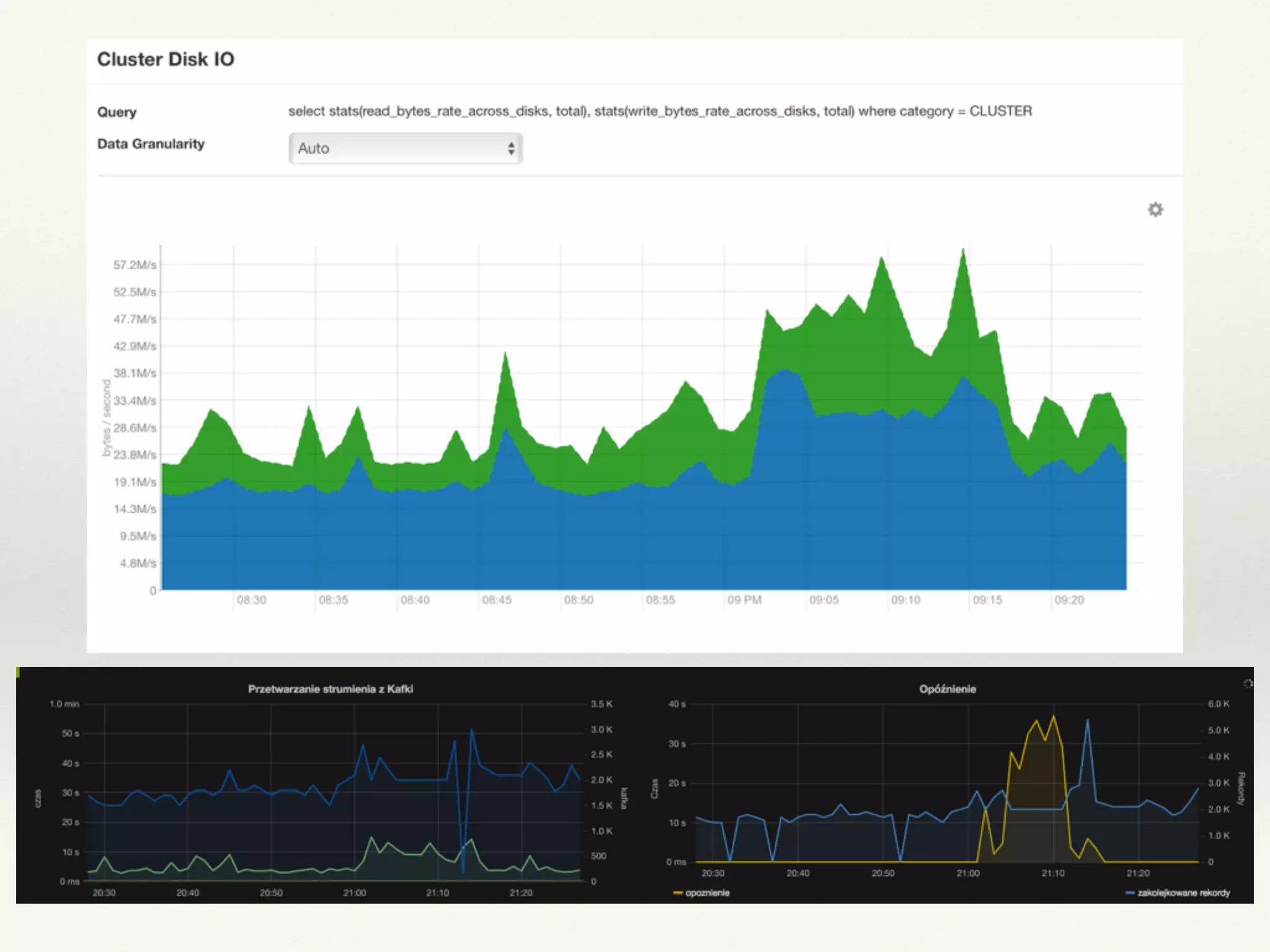

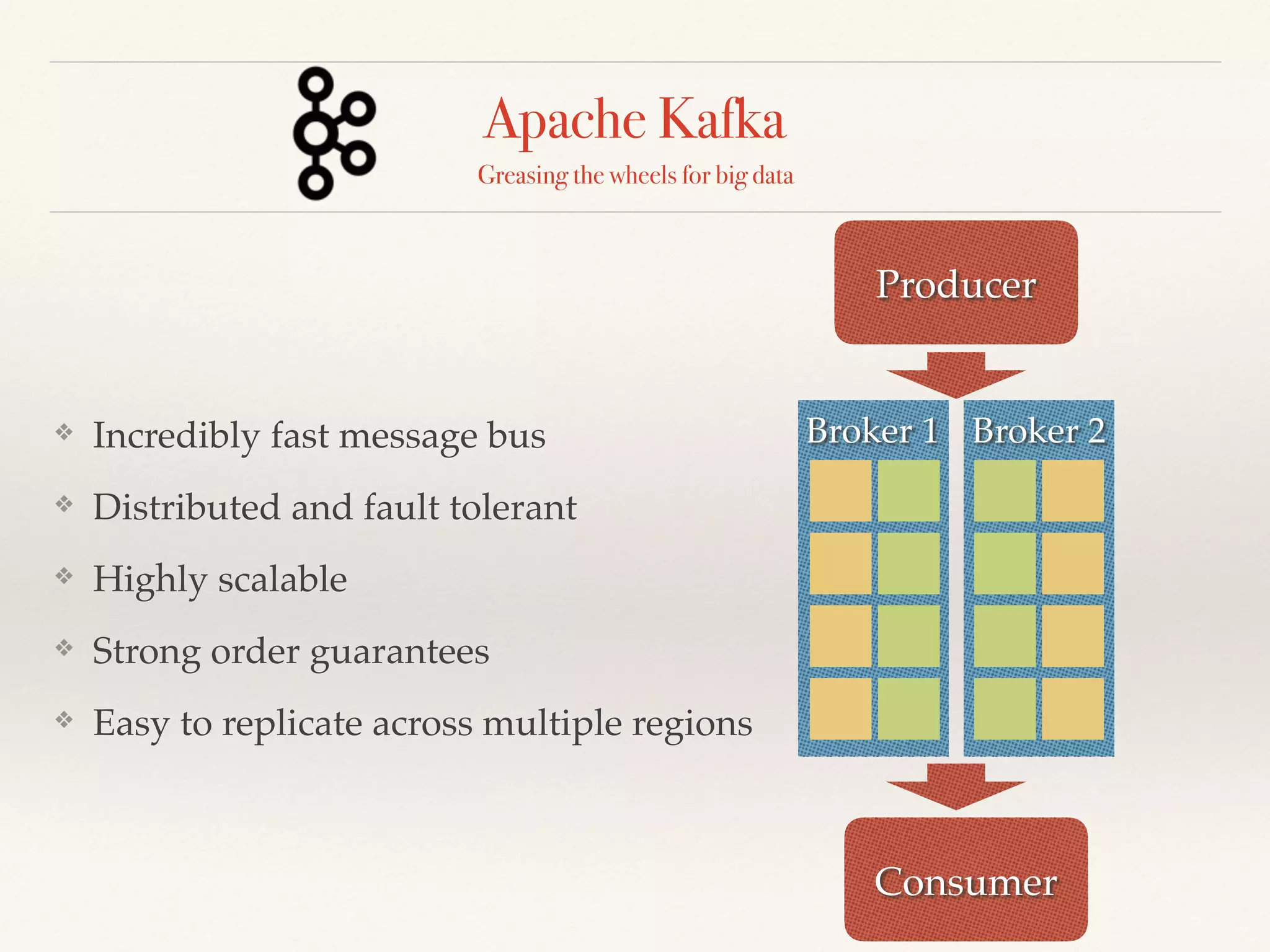







The document discusses using Apache Spark for streaming analytics. It describes Spark as a fast, scalable, and fault-tolerant platform for real-time processing of streaming data. Some key points covered include using Spark Streaming to ingest data from various sources, process streaming data using Resilient Distributed Datasets (RDDs) and Distributed Streams (DStreams), and considerations for monitoring and optimizing Spark streaming jobs.















































