Downloaded 29 times



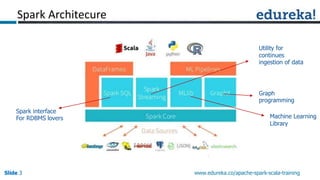

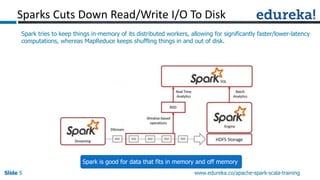



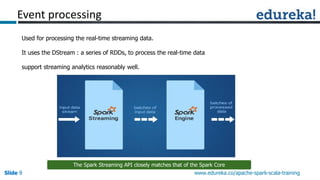

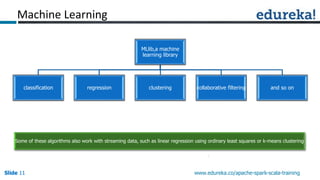
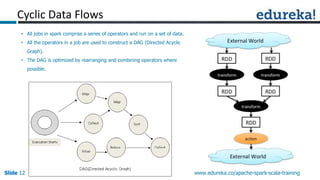
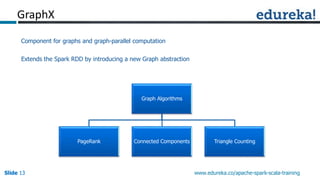

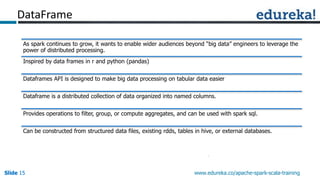


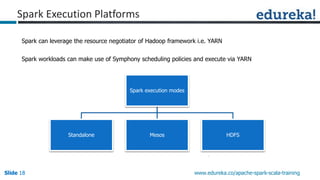
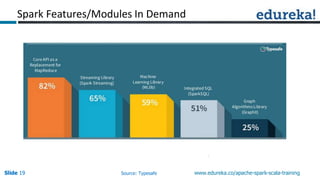




Spark can process data faster than Hadoop by keeping data in-memory as much as possible to avoid disk I/O. It supports streaming data, machine learning algorithms, graph processing, and SQL queries on structured data using its DataFrame API. Spark can integrate with Hadoop by running on YARN and accessing data from HDFS. The key capabilities discussed include low latency processing, streaming, machine learning, graph processing, DataFrames, and Hadoop integration.















































![Interview questions on Apache spark [part 2]](https://cdn.slidesharecdn.com/ss_thumbnails/interviewquestionsonapachesparkpart2-150731093720-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



























































