Downloaded 46 times


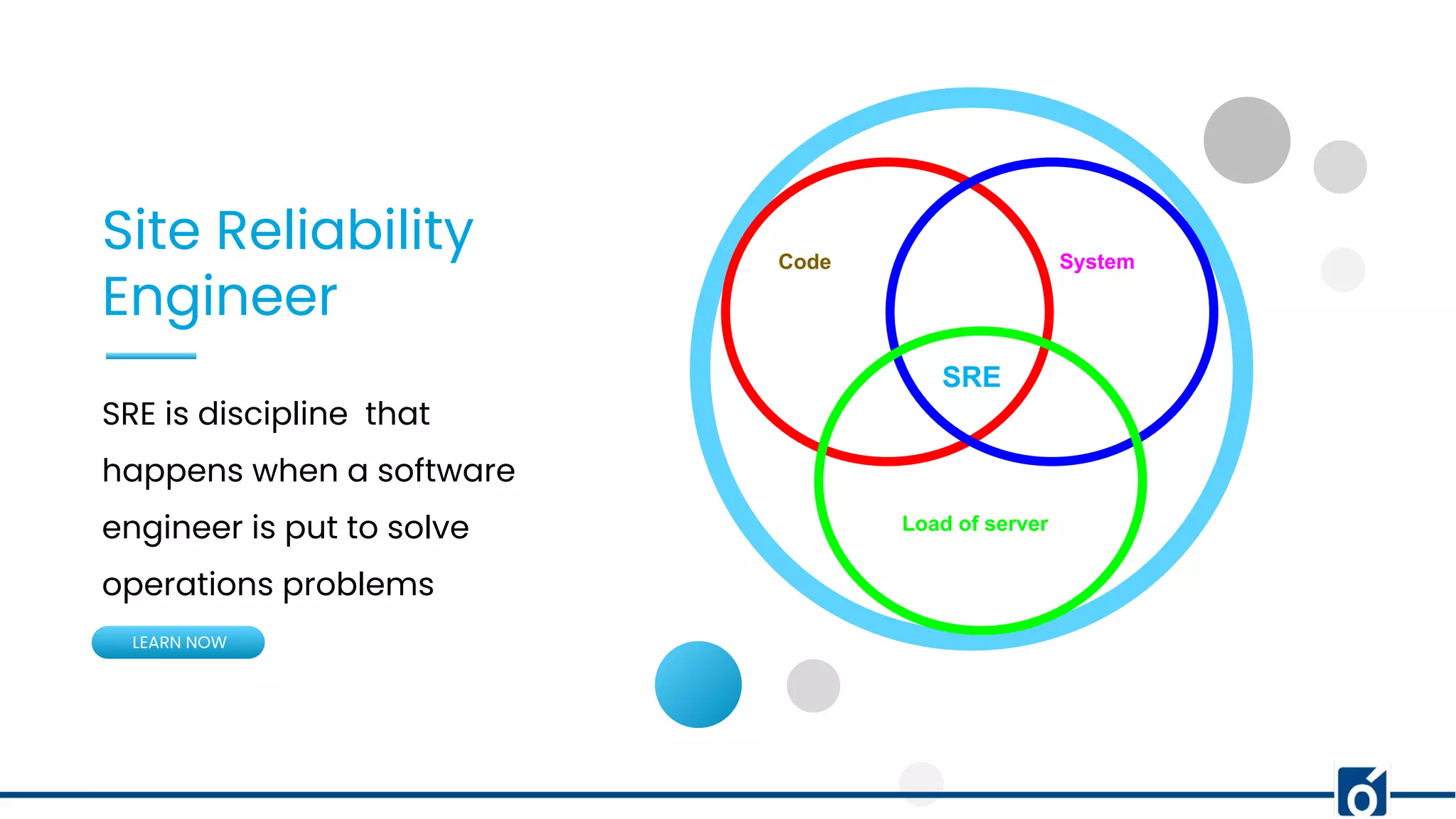

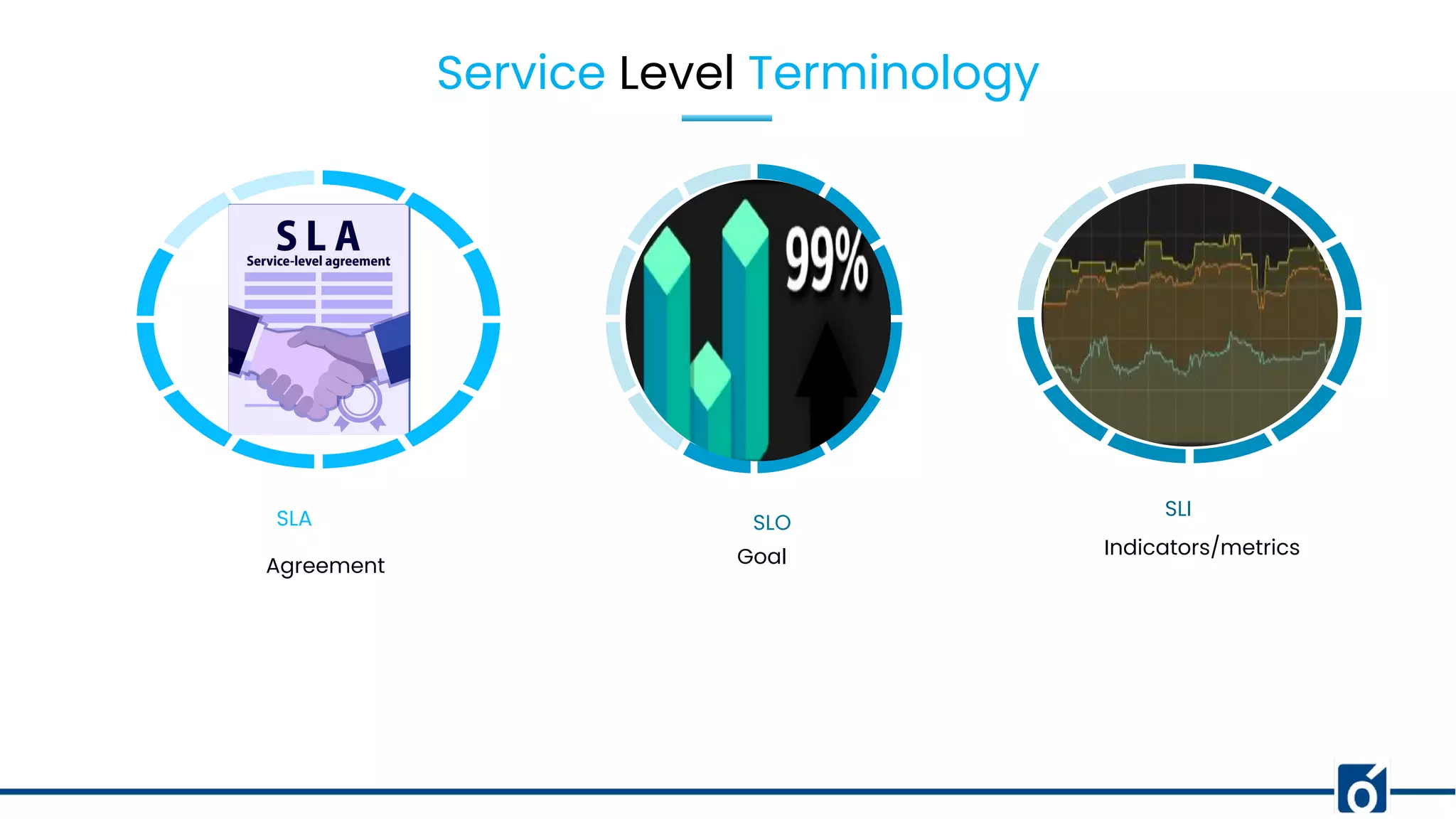
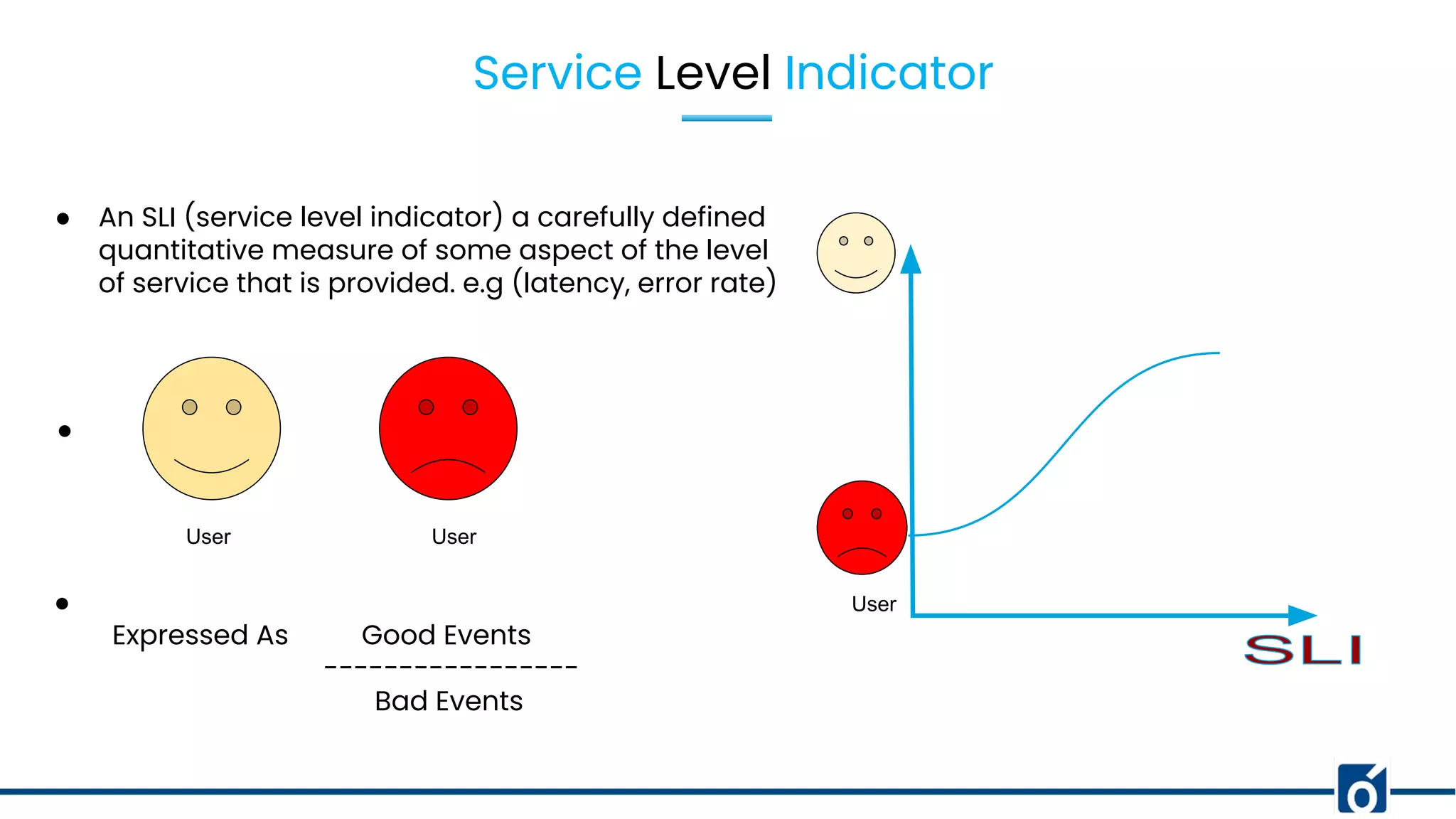








1. SRE is the discipline of applying software engineering practices to solve operations problems to build reliable systems. 2. Service level terminology includes Service Level Indicators (SLIs) which are quantitative measures of service aspects like latency or error rates, Service Level Objectives (SLOs) which are goals for specific metrics, and Service Level Agreements (SLAs) which are agreements within an SLA. 3. Choosing the right SLIs, crafting meaningful SLOs, collecting indicator data, and meeting customer expectations through SLAs are important for building reliable services.
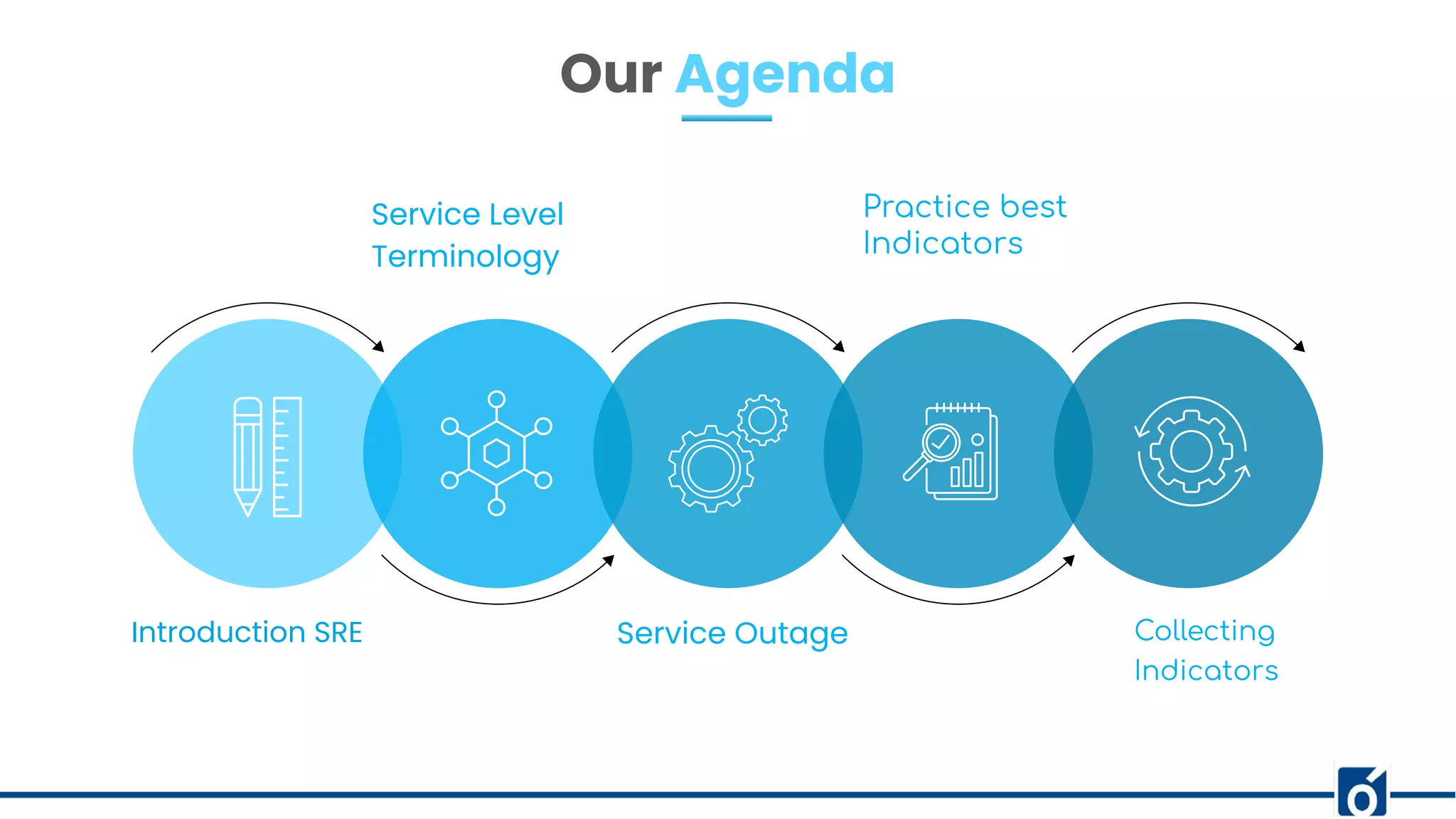
Introduction and agenda for SRE, presenting Knoldus as a tech consultancy, focusing on digital system modernization.
Introduction to SRE, addressing how to ascertain service reliability.
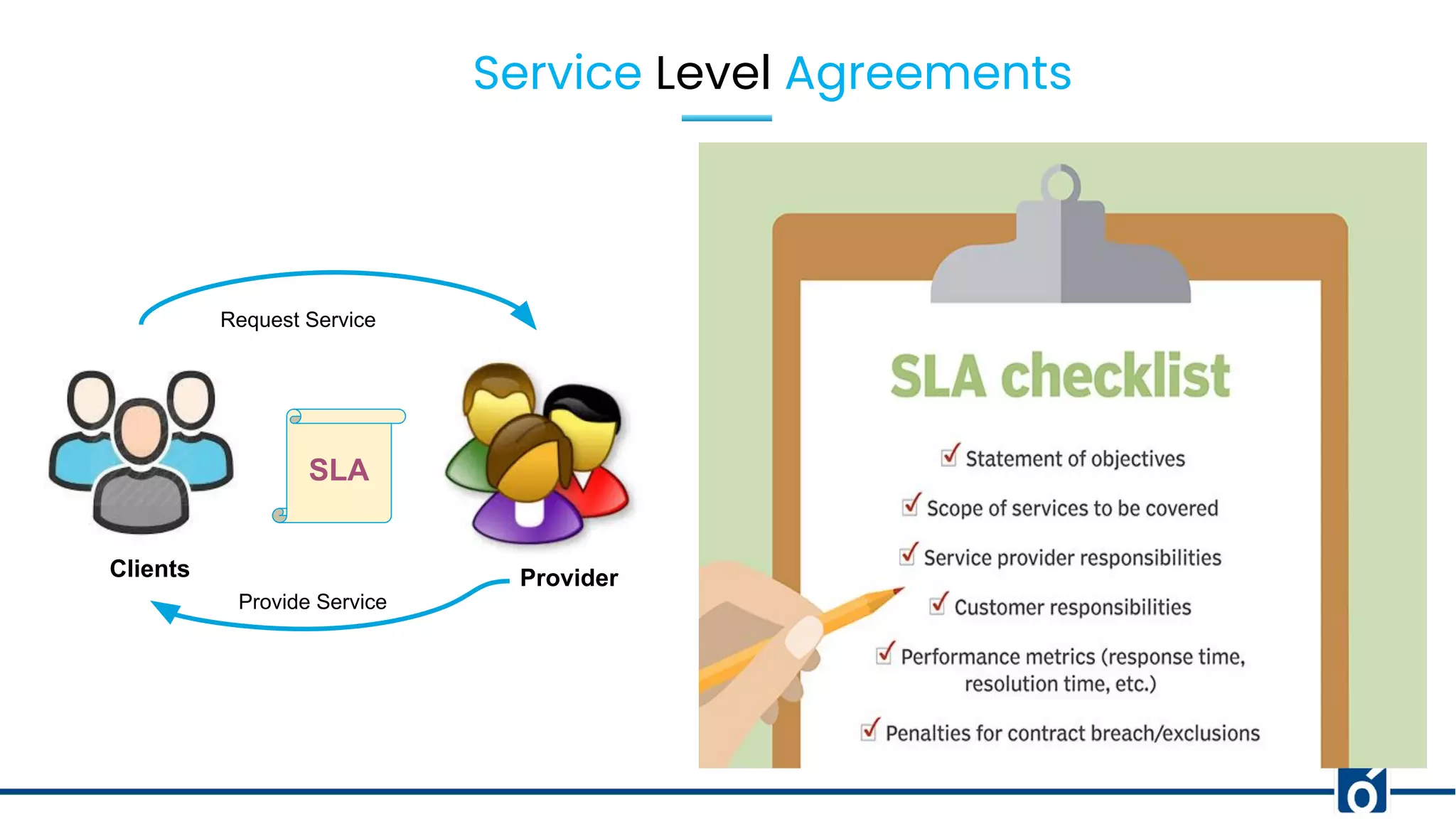
Defining SLA, SLO, and SLI; their roles in service agreements and objectives for performance metrics.
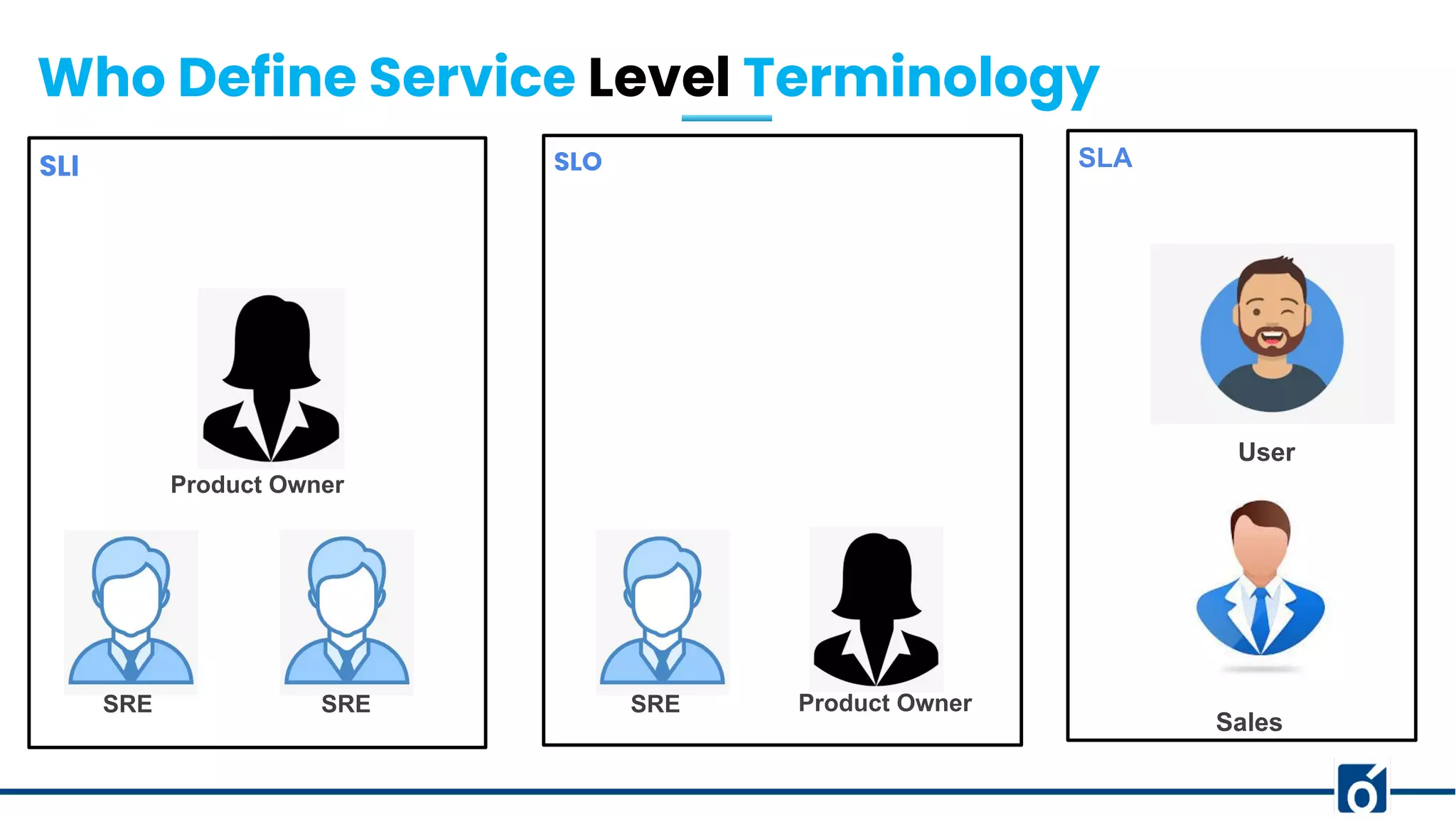
Best practices for crafting SLIs, SLOs, SLAs; role of various stakeholders in defining service levels.
Discussed service outages in banking and the solution involving setting up SLAs and SLOs for improved monitoring.
Selecting relevant indicators for services and methods for collecting these performance metrics.
Concluding insights on customer expectations, reliability, and the importance of SLIs, SLOs, SLAs.
Closing slide thanking the audience, with social media links for further engagement.




































































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)







![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)






