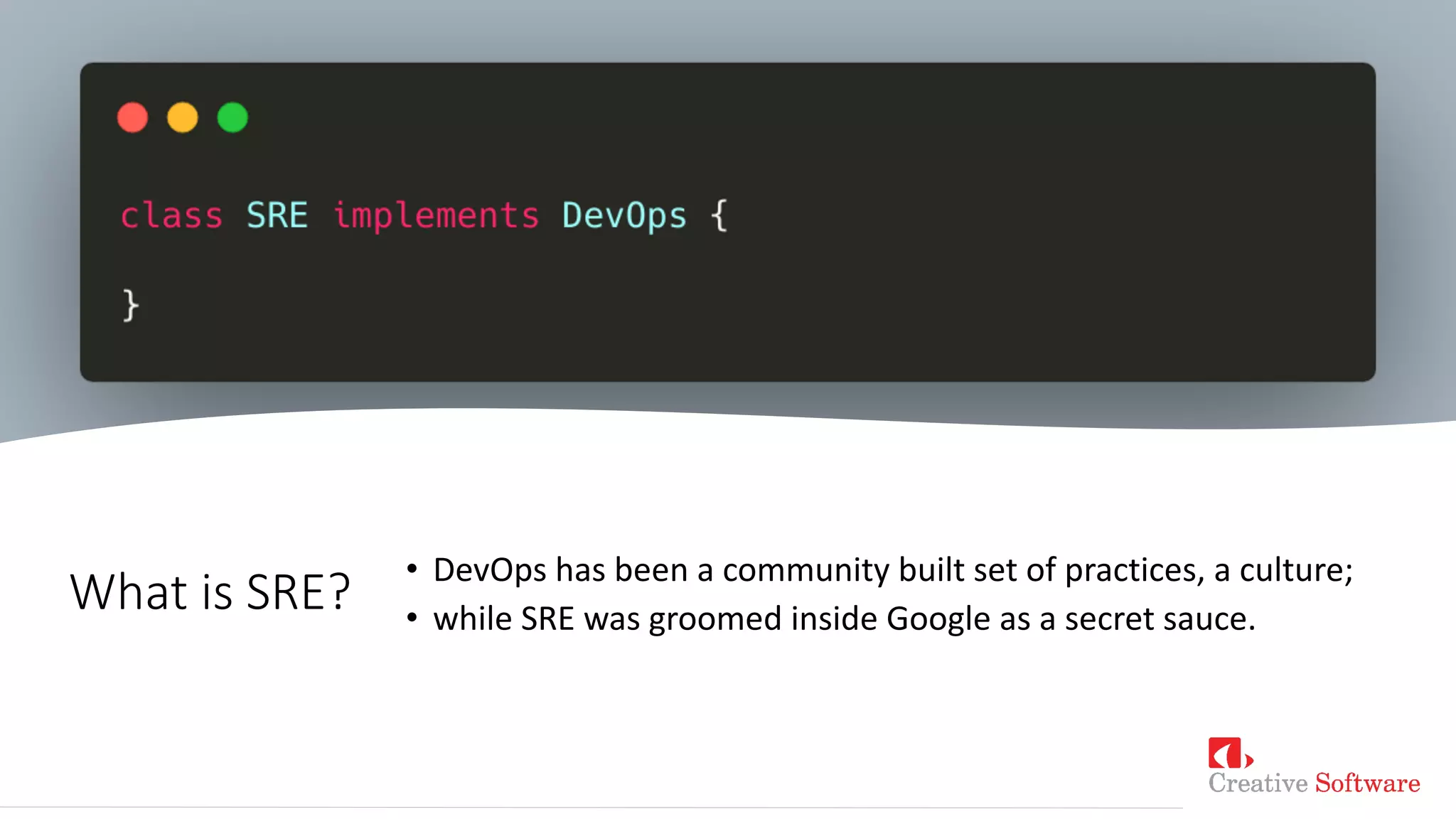
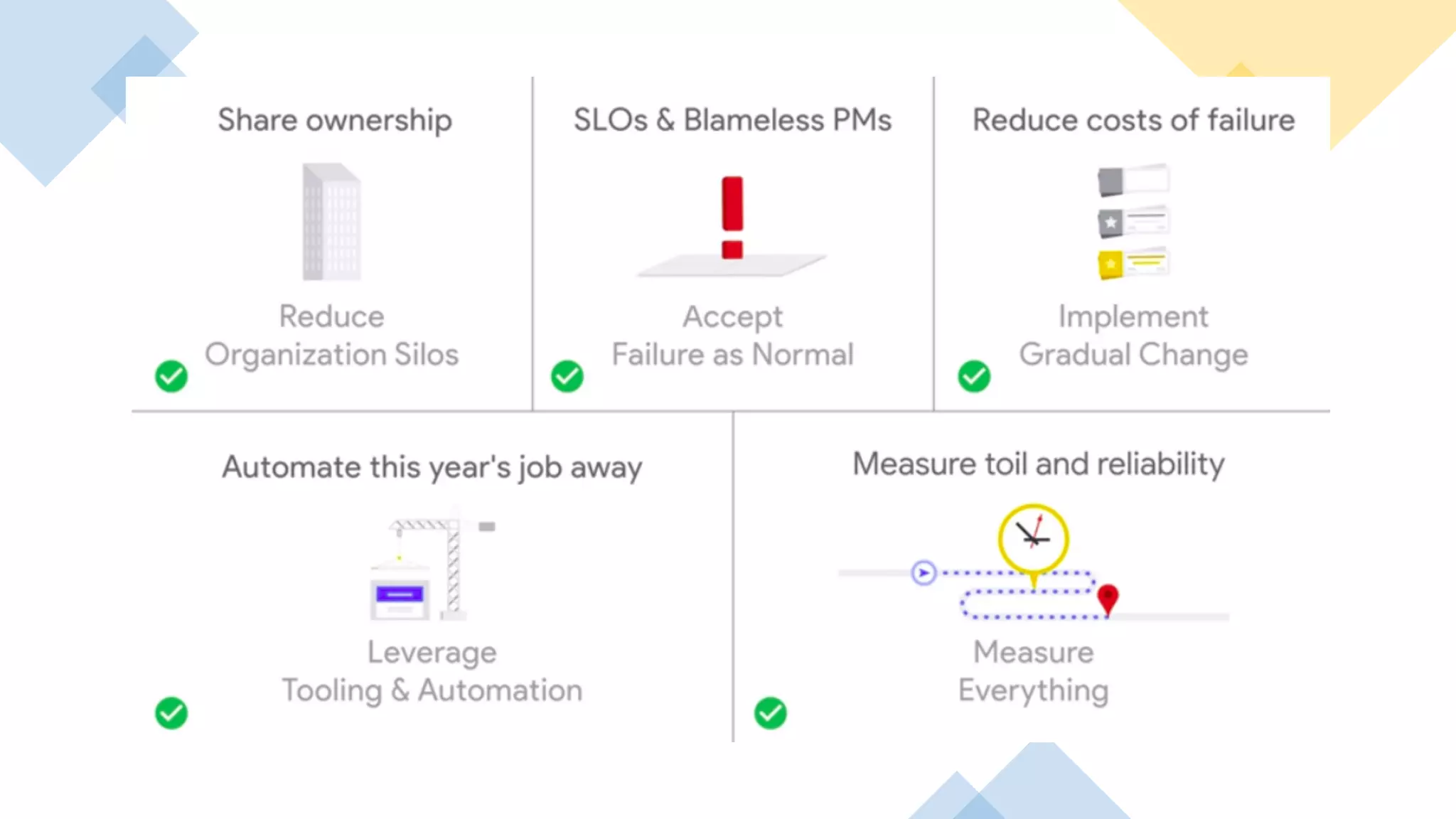
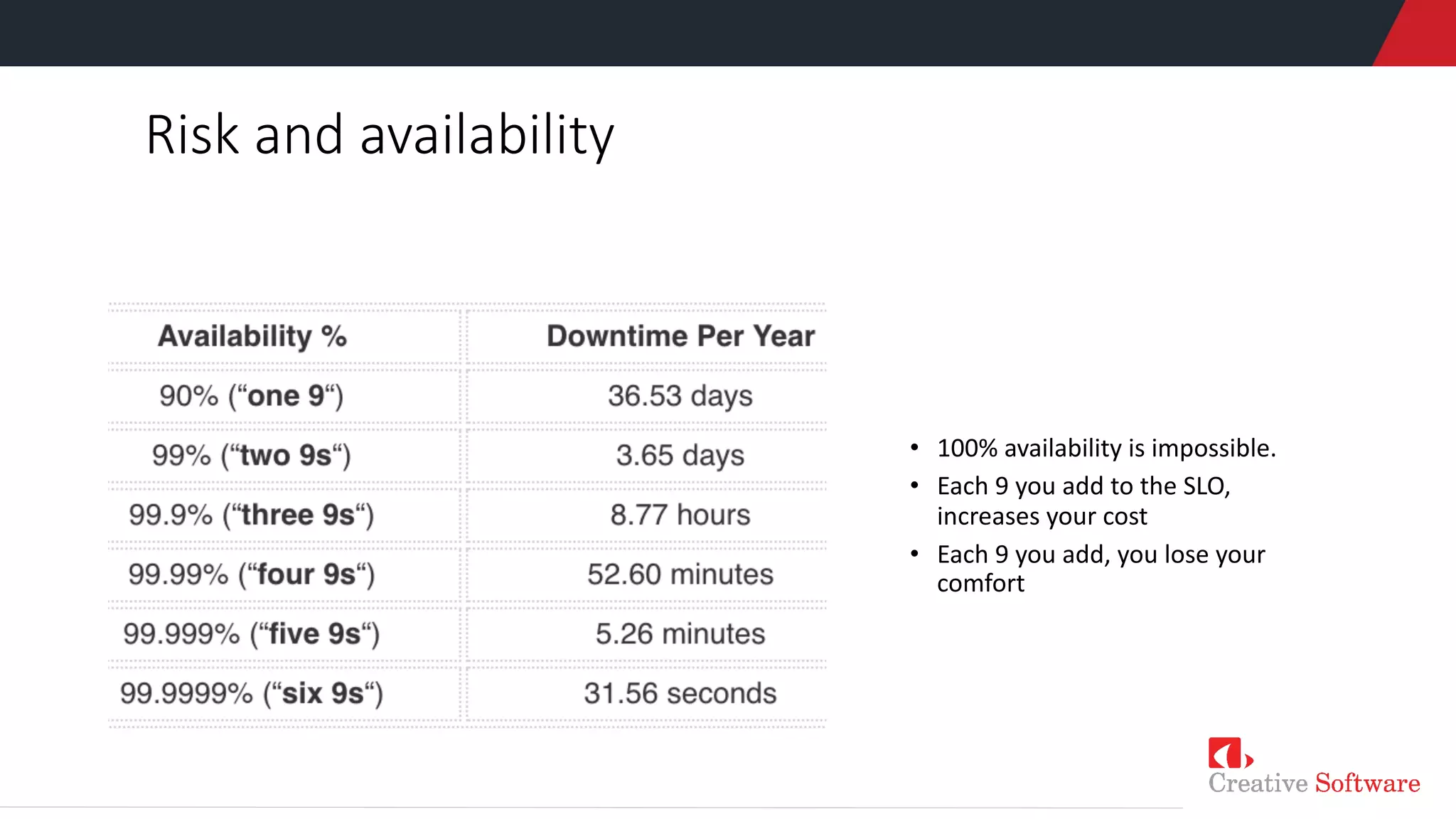
The document presents a discussion on Site Reliability Engineering (SRE) by Keet Malin Sugathadasa, highlighting its definition, principles, and practices crucial for managing production systems. It covers topics like the five pillars of SRE, service level indicators (SLIs), objectives (SLOs), error budgets, and the importance of blameless postmortems in promoting a culture of reliability. The presentation emphasizes the balance between agility in development and stability in operations, alongside strategies to manage toil and improve system reliability.









![Agility[Devs] vs Stability[Ops]
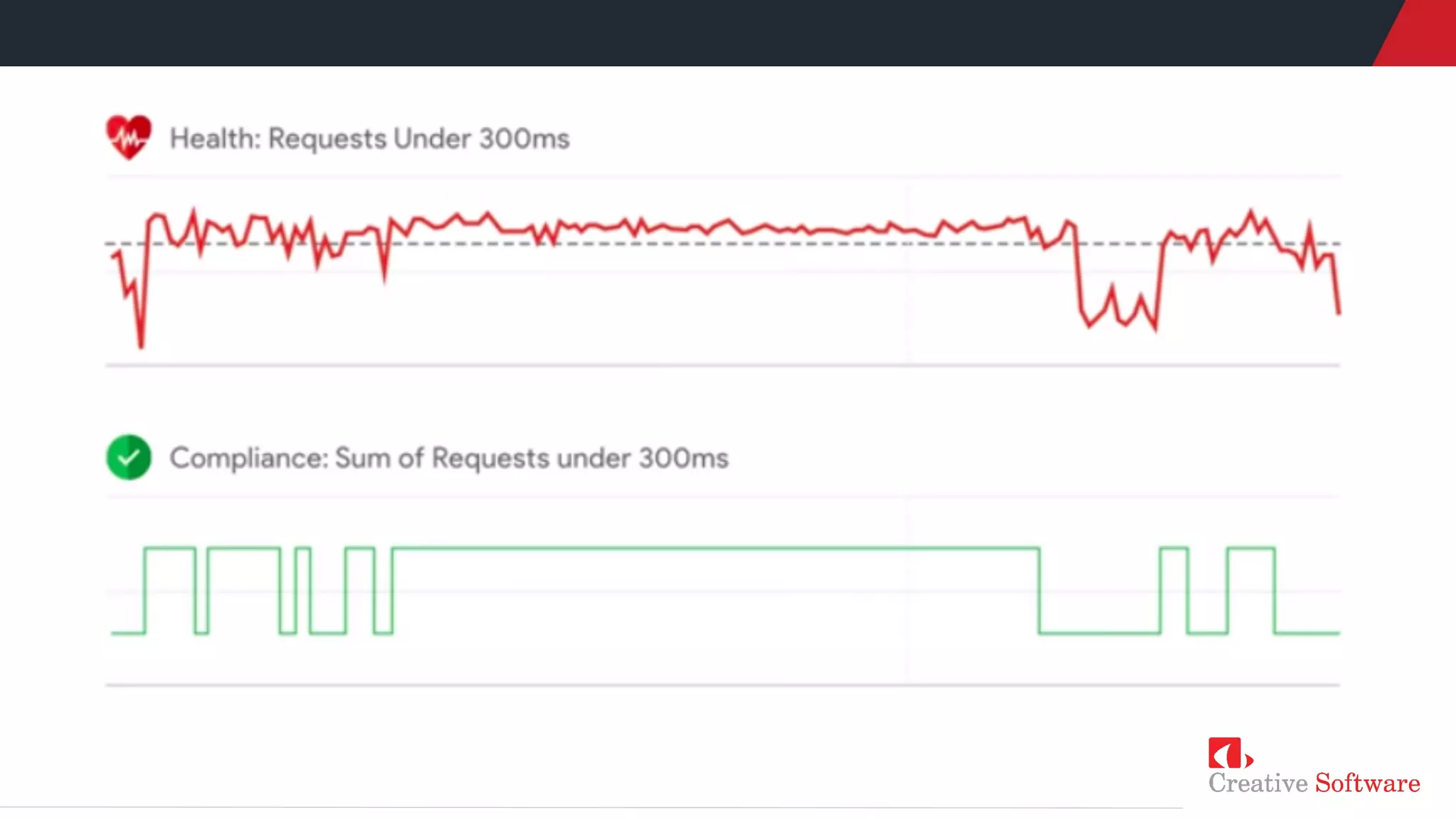
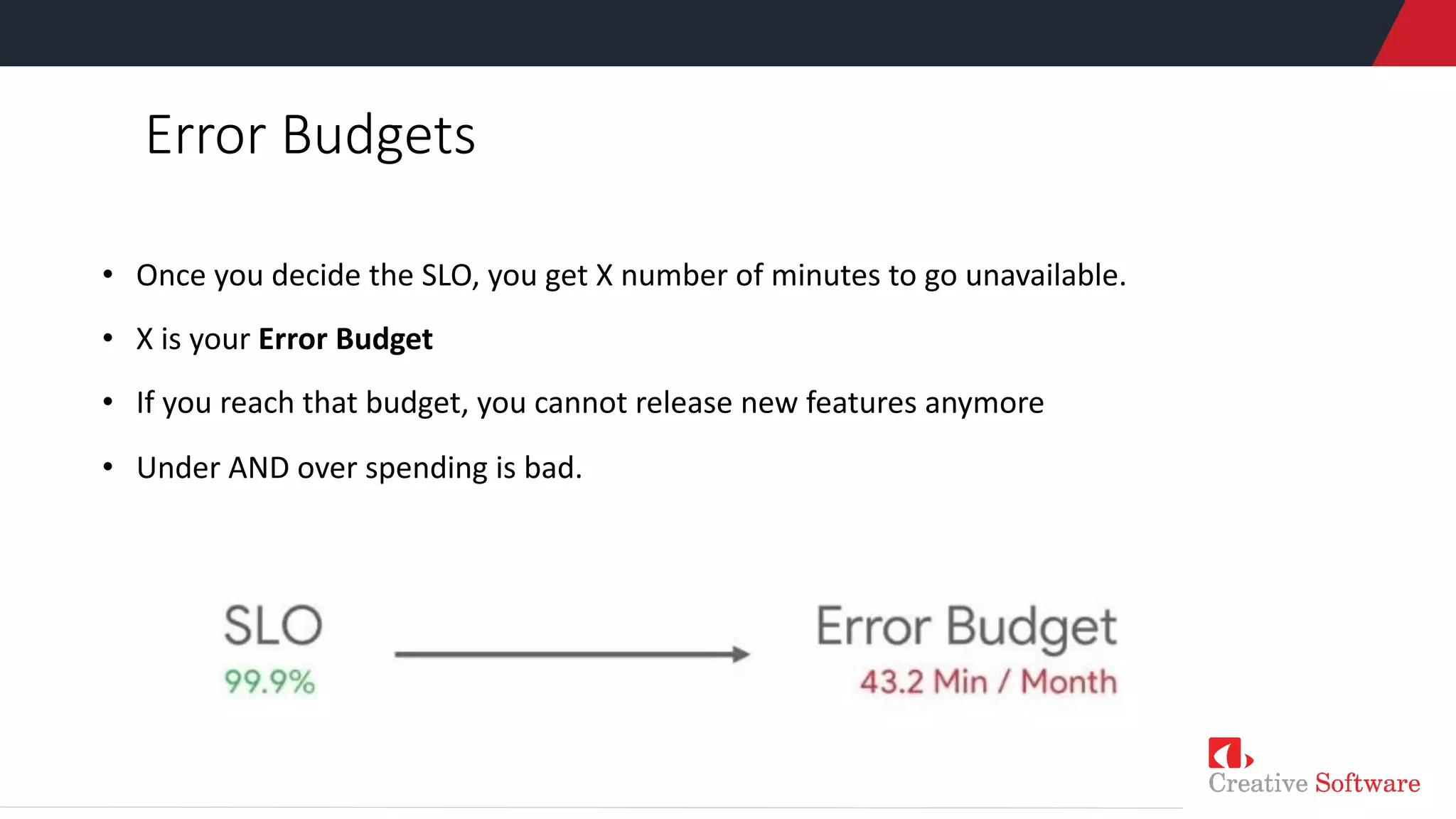
• What is availability?
• Clear definitions
• How available you want to be?
• Clear numerical indicators
• What to do when availability is
not met?](https://image.slidesharecdn.com/sretechtalkpresentation-201130180127/75/Site-Reliability-Engineering-SRE-Tech-Talk-by-Keet-Sugathadasa-12-2048.jpg)




































![Site-Reliability-Engineering-v2[6241].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/site-reliability-engineering-v26241-221023035909-82e9559b-thumbnail.jpg?width=640&height=640&fit=bounds)














































