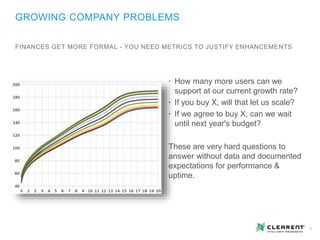
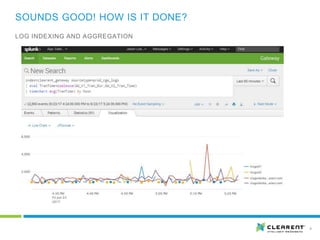
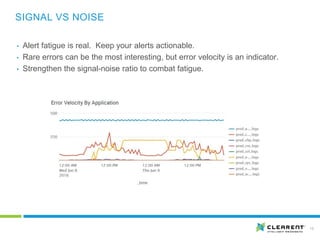
This document discusses site reliability engineering (SRE) for growing organizations. SRE focuses on production automation, resiliency and scalability, similar to devops but with more emphasis on keeping systems running. As companies grow, expectations often outpace capacity and complexity increases, requiring more automation rather than personnel to maintain high uptime levels. A dedicated SRE team can improve reaction times, learn from incidents, raise awareness of system behaviors, and focus on forward-looking improvements rather than just keeping existing systems running. Key SRE practices include automated monitoring, log indexing, health checks, establishing service level objectives and agreements, and implementing self-healing systems and runbooks.














































![Site-Reliability-Engineering-v2[6241].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/site-reliability-engineering-v26241-221023035909-82e9559b-thumbnail.jpg?width=640&height=640&fit=bounds)




































