Downloaded 128 times







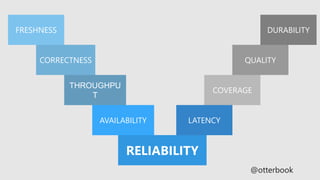
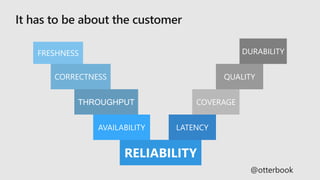








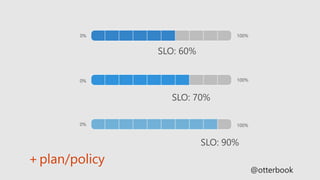







This document discusses best practices for site reliability engineering (SRE). It recommends hiring only coders, establishing service level agreements (SLAs) and measuring performance against them. It also suggests using error budgets, maintaining a common staffing pool for SRE and development teams, ensuring on-call teams have at least 8 people, and conducting post-mortems after every incident. Key reliability metrics like availability, latency, throughput and quality are identified. Objectives, service level objectives (SLOs) and responses if the error budget is exceeded or exhausted are outlined.























































































