Downloaded 30 times


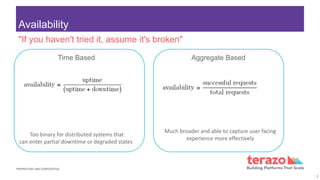






The document outlines the responsibilities and best practices of a Site Reliability Engineering (SRE) team, focusing on aspects like availability, performance, monitoring, and capacity planning. It details the importance of service level indicators (SLIs), objectives (SLOs), and agreements (SLAs), as well as how error budgets can guide prioritization of features and reliability. Additionally, it emphasizes the need for transparency, inspection, and adaptation in managing SLOs and error budgets for enhanced service delivery.








































![Site-Reliability-Engineering-v2[6241].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/site-reliability-engineering-v26241-221023035909-82e9559b-thumbnail.jpg?width=640&height=640&fit=bounds)


























