Downloaded 56 times
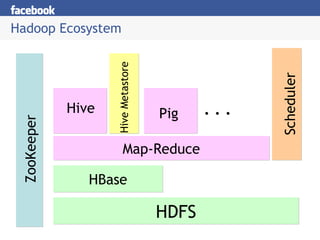



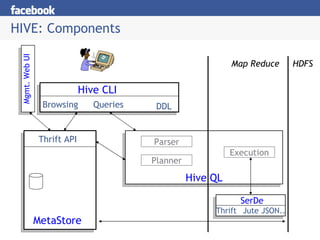
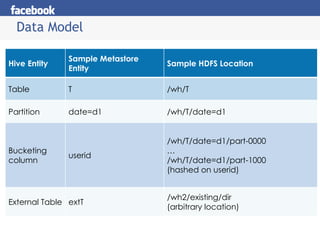













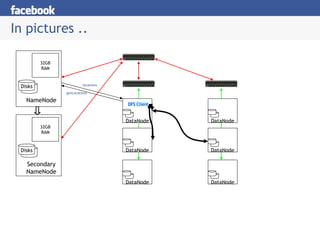
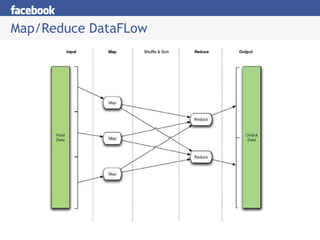

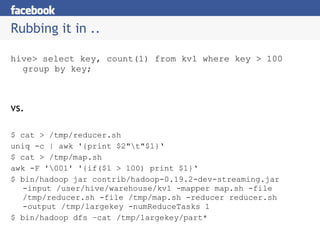
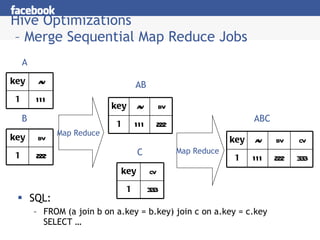

Hive provides an SQL-like interface to query data stored in Hadoop's HDFS distributed file system and processed using MapReduce. It allows users without MapReduce programming experience to write queries that Hive then compiles into a series of MapReduce jobs. The document discusses Hive's components, data model, query planning and optimization techniques, and performance compared to other frameworks like Pig.














































