














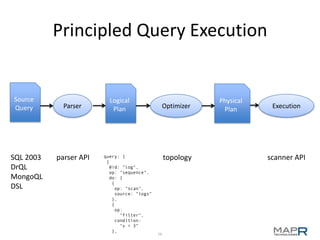
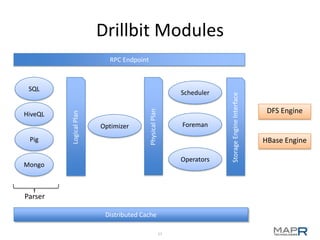














The document provides an overview of Apache Drill, emphasizing its capabilities in interactive querying across various data sources and formats while supporting low-latency and ad-hoc analysis. It details the architecture, features, and use cases, along with insights into its development inspired by Google's Dremel. The presentation highlights the extensibility of Apache Drill, support for nested data, and integration with existing tools, underscoring its community-driven progress and ongoing development initiatives.


































































































