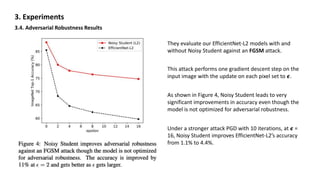
The document discusses the method of self-training with a 'noisy student' to improve ImageNet classification by leveraging unlabeled images and adding noise to enhance learning. Experiments demonstrate that this approach not only increases accuracy, achieving a 2.9% improvement over the previous state-of-the-art, but also boosts the robustness of models against various corruptions and adversarial attacks. The study concludes that using noisy students allows for significant advancements in both accuracy and robustness without requiring extensive weakly labeled data.














![4. Ablation Study
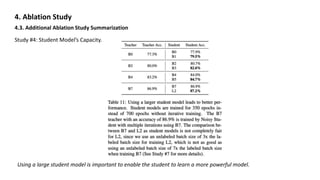
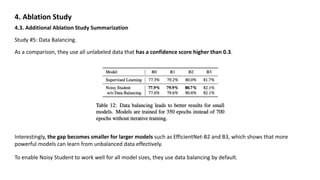
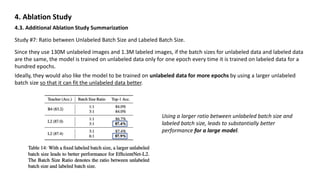
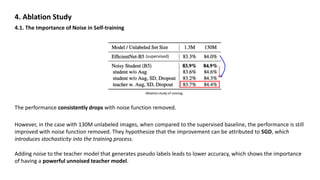
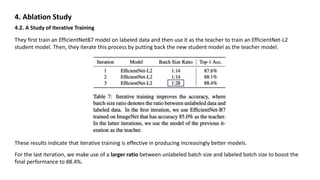
4.3. Additional Ablation Study Summarization
Study #3: Hard Pseudo-Label vs. Soft Pseudo-Label on Out-of-domain Data. (EfficientNet-B0)
Since a teacher model’s confidence on an image can be a good indicator of whether it is an out-of-domain image, they
consider the high-confidence images as in-domain images and the low-confidence images as out-of-domain images.
They sample 1.3M images in each confidence interval [0.0, 0.1], [0.1, 0.2], · · · , [0.9, 1.0].
(1) Soft pseudo labels and hard pseudo labels can both lead to
significant improvements with in-domain unlabeled images i.e.,
high-confidence images.
(2) With out-of-domain unlabeled images, hard pseudo labels can
hurt the performance while soft pseudo labels lead to robust
performance.](https://image.slidesharecdn.com/noisystudent-200120150153/85/Self-training-with-Noisy-Student-improves-ImageNet-classification-18-320.jpg)