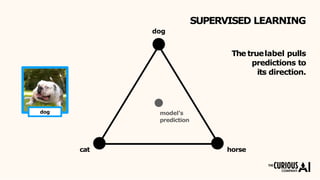
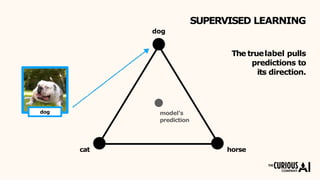
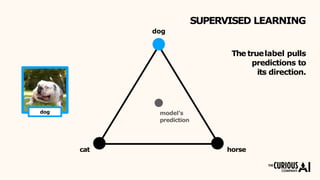
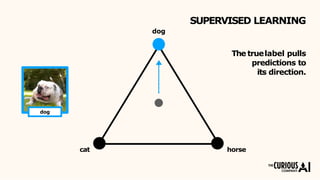
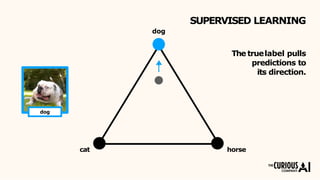
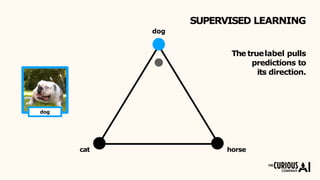
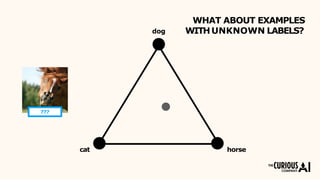
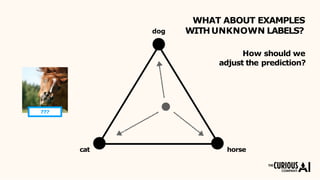
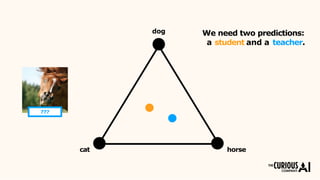
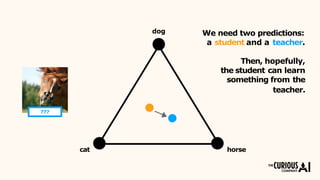
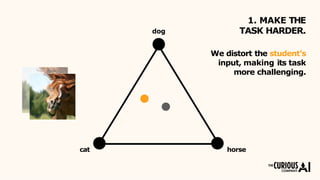
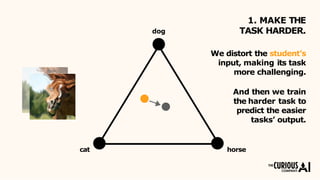
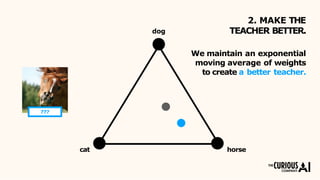
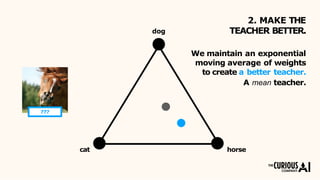
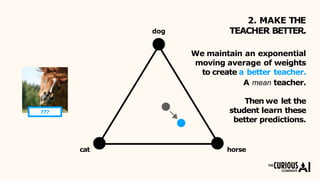
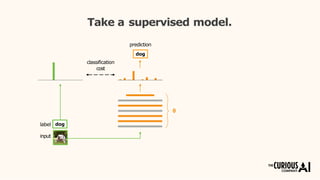
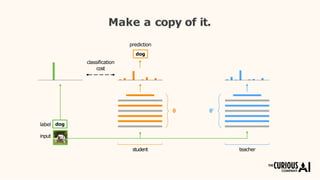
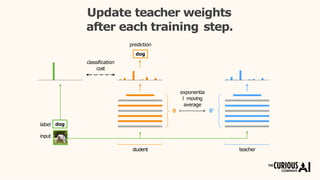
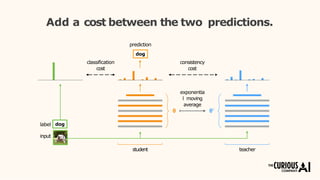
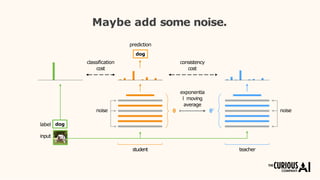
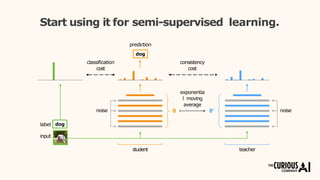
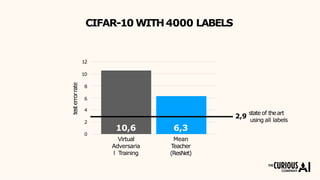
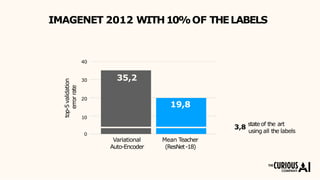
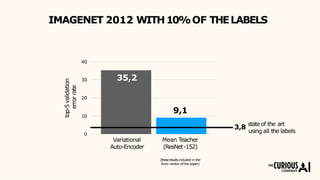
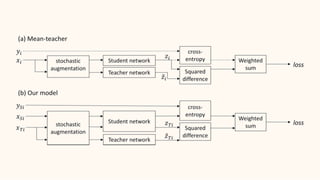
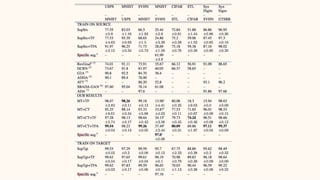
The document describes the mean teacher approach for semi-supervised learning. The mean teacher uses two neural networks, a student network and a teacher network, which are the same architecture but have different weights. The teacher's weights are an exponential moving average of the student's trained weights and provide better predictions to help train the student. This allows the student and teacher to improve each other in a virtuous cycle. Results shown demonstrate that the mean teacher approach achieves state-of-the-art results on image classification tasks using only a small percentage of labeled data.