Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Takumi Ohkuma
PPTX, PDF
53 views
「解説資料」Reasoning-RCNN: Unifying Adaptive Global Reasoning into Large-scale Object Detection
CVPR2019のReasoning-RCNNについて解説した資料です。
Science
◦
Related topics:
Deep Learning
•
Computer Vision Insights
•
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 25
2
/ 25
3
/ 25
4
/ 25
5
/ 25
6
/ 25
7
/ 25
8
/ 25
9
/ 25
10
/ 25
11
/ 25
12
/ 25
13
/ 25
14
/ 25
15
/ 25
16
/ 25
17
/ 25
18
/ 25
19
/ 25
20
/ 25
21
/ 25
22
/ 25
23
/ 25
24
/ 25
25
/ 25
More Related Content
PDF
第4章 ニューラルネットワークの学習
by
川上 詩織
PDF
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
PPTX
ラビットチャレンジレポート 深層学習Day1
by
HiroyukiTerada4
PDF
Tutorial-DeepLearning-PCSJ-IMPS2016
by
Takayoshi Yamashita
PPTX
CVPR2018 pix2pixHD論文紹介 (CV勉強会@関東)
by
Tenki Lee
PDF
20140726.西野研セミナー
by
Hayaru SHOUNO
PDF
Context-Aware Crowd Counting
by
harmonylab
PDF
Domain Adaptive Faster R-CNN for Object Detection in the Wild 論文紹介
by
Tsukasa Takagi
第4章 ニューラルネットワークの学習
by
川上 詩織
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
ラビットチャレンジレポート 深層学習Day1
by
HiroyukiTerada4
Tutorial-DeepLearning-PCSJ-IMPS2016
by
Takayoshi Yamashita
CVPR2018 pix2pixHD論文紹介 (CV勉強会@関東)
by
Tenki Lee
20140726.西野研セミナー
by
Hayaru SHOUNO
Context-Aware Crowd Counting
by
harmonylab
Domain Adaptive Faster R-CNN for Object Detection in the Wild 論文紹介
by
Tsukasa Takagi
Similar to 「解説資料」Reasoning-RCNN: Unifying Adaptive Global Reasoning into Large-scale Object Detection
PDF
DeepLearningDay2016Summer
by
Takayoshi Yamashita
PDF
SSII2014 詳細画像識別 (FGVC) @OS2
by
nlab_utokyo
PDF
ICCV 2019 論文紹介 (26 papers)
by
Hideki Okada
PPTX
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
PDF
CVPR 2019 report (30 papers)
by
ShunsukeNakamura17
PDF
IEEE ITSS Nagoya Chapter
by
Takayoshi Yamashita
PDF
物体検知(Meta Study Group 発表資料)
by
cvpaper. challenge
PDF
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
by
nlab_utokyo
PDF
点群SegmentationのためのTransformerサーベイ
by
Takuya Minagawa
PDF
【2015.07】(1/2)cvpaper.challenge@CVPR2015
by
cvpaper. challenge
PDF
Learning Spatial Common Sense with Geometry-Aware Recurrent Networks
by
Kento Doi
PDF
SPADE :Semantic Image Synthesis with Spatially-Adaptive Normalization
by
Tenki Lee
PDF
【2015.05】cvpaper.challenge@CVPR2015
by
cvpaper. challenge
PPTX
You Only Learn One Representation: Unified Network for Multiple Tasks
by
harmonylab
PDF
20201010 personreid
by
Takuya Minagawa
PDF
R-CNNの原理とここ数年の流れ
by
Kazuki Motohashi
PDF
Deep residual learning for image recognition
by
禎晃 山崎
PPTX
CVPR 2017 報告
by
Yu Nishimura
PPTX
[DL輪読会]Differentiable Mapping Networks: Learning Structured Map Representatio...
by
Deep Learning JP
PDF
(文献紹介)深層学習による動被写体ロバストなカメラの動き推定
by
Morpho, Inc.
DeepLearningDay2016Summer
by
Takayoshi Yamashita
SSII2014 詳細画像識別 (FGVC) @OS2
by
nlab_utokyo
ICCV 2019 論文紹介 (26 papers)
by
Hideki Okada
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
CVPR 2019 report (30 papers)
by
ShunsukeNakamura17
IEEE ITSS Nagoya Chapter
by
Takayoshi Yamashita
物体検知(Meta Study Group 発表資料)
by
cvpaper. challenge
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
by
nlab_utokyo
点群SegmentationのためのTransformerサーベイ
by
Takuya Minagawa
【2015.07】(1/2)cvpaper.challenge@CVPR2015
by
cvpaper. challenge
Learning Spatial Common Sense with Geometry-Aware Recurrent Networks
by
Kento Doi
SPADE :Semantic Image Synthesis with Spatially-Adaptive Normalization
by
Tenki Lee
【2015.05】cvpaper.challenge@CVPR2015
by
cvpaper. challenge
You Only Learn One Representation: Unified Network for Multiple Tasks
by
harmonylab
20201010 personreid
by
Takuya Minagawa
R-CNNの原理とここ数年の流れ
by
Kazuki Motohashi
Deep residual learning for image recognition
by
禎晃 山崎
CVPR 2017 報告
by
Yu Nishimura
[DL輪読会]Differentiable Mapping Networks: Learning Structured Map Representatio...
by
Deep Learning JP
(文献紹介)深層学習による動被写体ロバストなカメラの動き推定
by
Morpho, Inc.
More from Takumi Ohkuma
PPTX
「解説資料」ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
by
Takumi Ohkuma
PDF
(2022年3月版)深層学習によるImage Classificaitonの発展
by
Takumi Ohkuma
PPTX
「解説資料」MetaFormer is Actually What You Need for Vision
by
Takumi Ohkuma
PDF
「解説資料」Pervasive Label Errors in Test Sets Destabilize Machine Learning Bench...
by
Takumi Ohkuma
PDF
深層学習によるHuman Pose Estimationの基礎
by
Takumi Ohkuma
PDF
(2021年8月版)深層学習によるImage Classificaitonの発展
by
Takumi Ohkuma
PDF
「解説資料」VideoMix: Rethinking Data Augmentation for Video Classification
by
Takumi Ohkuma
PDF
「解説資料」Toward Fast and Stabilized GAN Training for High-fidelity Few-shot Imag...
by
Takumi Ohkuma
PPTX
「解説資料」Set Transformer: A Framework for Attention-based Permutation-Invariant ...
by
Takumi Ohkuma
PPTX
「解説資料」Large-Scale Few-shot Learning: Knowledge Transfer With Class Hierarchy
by
Takumi Ohkuma
「解説資料」ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
by
Takumi Ohkuma
(2022年3月版)深層学習によるImage Classificaitonの発展
by
Takumi Ohkuma
「解説資料」MetaFormer is Actually What You Need for Vision
by
Takumi Ohkuma
「解説資料」Pervasive Label Errors in Test Sets Destabilize Machine Learning Bench...
by
Takumi Ohkuma
深層学習によるHuman Pose Estimationの基礎
by
Takumi Ohkuma
(2021年8月版)深層学習によるImage Classificaitonの発展
by
Takumi Ohkuma
「解説資料」VideoMix: Rethinking Data Augmentation for Video Classification
by
Takumi Ohkuma
「解説資料」Toward Fast and Stabilized GAN Training for High-fidelity Few-shot Imag...
by
Takumi Ohkuma
「解説資料」Set Transformer: A Framework for Attention-based Permutation-Invariant ...
by
Takumi Ohkuma
「解説資料」Large-Scale Few-shot Learning: Knowledge Transfer With Class Hierarchy
by
Takumi Ohkuma
「解説資料」Reasoning-RCNN: Unifying Adaptive Global Reasoning into Large-scale Object Detection
1.
1 DEEP LEARNING JP [DL
Papers] http://deeplearning.jp/ Takumi Ohkuma, Nakayama Lab M1 Reasoning-RCNN: Unifying Adaptive Global Reasoning into Large-scale Object Detection
2.
自己紹介 ■ 大熊拓海(オオクマ タクミ) ■
東京大学 情報理工学系研究科 創造情報学専攻 中山研究室 M1 ■ 専門はCV系 – 現在の研究テーマは動画情報を用いたSemi-Supervised detection 2
3.
書誌情報 ■ 題名:Reasoning-RCNN: Unifying
Adaptive Global Reasoning into Large-scale Object Detection ■ 会議:CVPR 2019 ■ 著者:Hang Xu, ChenHan Jiang, Xiaodan Liang, Liang Lin, Zhenguo(Huaweiと中山大学の共同研究) スライド中の図で引用が特に明記されていないもの は、全て紹介する論文のものです 3
4.
概要 ■ クラス間の関係性を用いて、多 クラスの物体検出の精度を高め る ■ 物体間の関係性にはナレッジグ ラフを用い、その関係性はVisual Genome(VG)[1]より取得 ■
任意の物体検出器に応用するこ とが可能 [1] R. Krishna, et.al. “visual genome: Connecting language and vision using crowdsourced dense image annotations” 2016. 4
5.
背景 多数のクラス(1000以上) を含む物体検出器の精度を上げたい 教師データの数が少ないクラスや、 小さい物体が多いクラスに対しての情報が少ない クラス間の関係性にも 目を向けよう! 目的 問題点 解決策 5
6.
方針 ■ クラス間の関係性を明示的に保持しておき、検出に役立てる →Visual Genome(VG)から取得し、ナレッジグラフを用いて保持 ■
保持されている関係性と、ベースとなるのネットワーク出力である 特徴マップを用いて新たな特徴量を獲得し、既存の特徴量と結合 →ベースとなるの物体検出器を拡張する形を取るので、任意の物 体検出器に応用が可能 6
7.
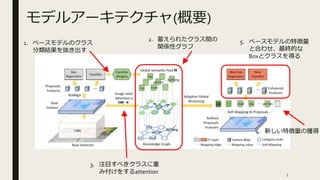
モデルアーキテクチャ(概要) 5. ベースモデルの特徴量 と合わせ、最終的な Boxとクラスを得る 2. 蓄えられたクラス間の 関係性グラフ 3.
注目すべきクラスに重 み付けをするattention 4. 新しい特徴量の獲得 1. ベースモデルのクラス 分類結果を抜き出す 7
8.
ナレッジグラフ ■ 本論文ではナレッジグラフを以下の無向グラフで定義する。 𝐺 =
< 𝑁, ξ > 𝑁: 物体のクラスに対応するノードの集合 𝑒𝑖𝑗 ∊ ξ :クラス間の関係性を表すエッジ(𝑖, 𝑗 ∊ 𝑁 ) ξはクラス数をCするとC × Cの実数値行列であり、この行 列を通じて物体間の一般常識(例:人がバイクに乗る)や 物体そのものに関する一般常識(例:リンゴは赤い)等の 情報を付加する。 8
9.
Visual Genome ■ ナレッジグラフが蓄える情報は、Visual
Genome(以下VG)というデータ セットを用いて獲得する。 • VGは物体検出用のデータセットで、 バンディングボックスの他に、画像 中の物体(左図の赤いノード)同士の 関係性(緑ノード)、および物体の性 質(青ノード)の情報を持っている。 • クラス数も豊富で、本論文ではその うちの1000クラス、および3000クラ スを用いて実験を行う(以下 𝑉𝐺1000, 𝑉𝐺3000)。 R. Krishna, et.al. “visual genome: Connecting language and vision using crowdsourced dense image annotations” 2016. 9
10.
ナレッジグラフの作成 ■ 本実験で用いるナレッジグラフは「クラス間の関係性」、「クラス間の 類似度」に基づく2種類ある。 「クラス間の関係性」 単純に対応する2クラスの関係の数を数え上げ、 それを規格化した値を𝑒𝑖𝑗 ∊
ξ の値とする。 <man, play, dog> <dog, sit on, man> <dog, by, man> … その数を𝑅𝑖𝑗(= 𝑅𝑗𝑖)とし 𝑒𝑖𝑗 = 𝑅𝑖𝑗 𝑘=1 𝐶 𝑅𝑖𝑘 𝑙=1 𝐶 𝑅𝑗𝑙 ここでは関係性の数のみに注目し、種類は問わ ない。 数え上げる 「クラス間の類似性」 各クラスに対応する性質を数え上げ、これを確率分 布とみなし、JSダイバージェンスでクラス間の類似 度を計算する。この値を𝑒𝑖𝑗 ∊ ξ とする。 𝑃𝑖, 𝑃𝑗を各クラスの性質の確率分布とすると 𝑒𝑖𝑗 = 𝑒𝑗𝑖 = 𝐽𝑆(𝑃𝑖||𝑃𝑗)である。 なおJSダイバージェンスは対称関数なので、 ξ は対 称行列である。 10
11.
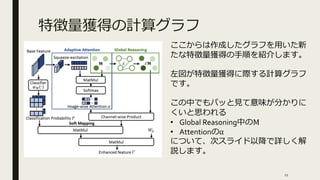
特徴量獲得の計算グラフ ここからは作成したグラフを用いた新 たな特徴量獲得の手順を紹介します。 左図が特徴量獲得に際する計算グラフ です。 この中でもパッと見て意味が分かりに くいと思われる • Global Reasoning中のM •
Attentionのα について、次スライド以降で詳しく解 説します。 11
12.
Global Semantic Pool ■
次は定義されたナレッジグラフの情報を効率良く伝搬させるのに相応し い特徴量を定める必要がある。 ■ 今回はベースモデルのクラス分類に用いられる最終層の重みMをそのま ま各クラスに対応する特徴量として用いる。 ■ Mは全データセットを用いて学習されているのでノイズに強く頑健であ り、また高レベルのレイヤーの特徴量なので大域的な情報を含んでいる。 ■ 論文ではこれをGlobal Semantic Poolと呼んでいる。 𝐶: クラス数 𝐷:ベースモデル最終層の特徴マップの次元数M ∊ ℝ 𝐶×𝐷 12
13.
特徴量抽出 ■ ナレッジグラフとGlobal Semantic
Pool、ベースモデルのクラス分類結果を 用いて新たな特徴量を抽出できる。 ξ : ナレッジグラフ M : Global Semantic Pool 𝑝: ベースモデルのクラス分類出力 1. まず𝑝 ∊ ℝ 𝐶をベースモデルのクラス分類出力の結果とする(𝐶次元が 各クラスに対応し総和は1)。 2. 次にナレッジグラフの情報をGlobal Semantic Poolを通じて反映させ たものであるξ Mを𝑝にかける。 3. ξ Mの各行は各クラスに対応している為、 𝑝の確率がより高いクラ スに高い重み付けがなされる。 4. 最後に線形変換𝑊𝐺 ∊ ℝ 𝐷×𝐸 を施して、 E次元の特徴ベクトルを得る。 𝑝ξ M𝑊𝐺 ∊ ℝ 𝐸 13
14.
Attention ■ 前スライドの定義だと、新たな特徴量は候補領域の確率のみに依存し、 画像全体の特徴を捉えられない。 ■ そこで画像全体の特徴量𝑧
𝑠を抽出し、Attention機構を構成する。 ■ 具体的には α = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥 𝑧 𝑠 𝑊𝑠 𝑀 ∊ ℝ 𝐶 とAttentionを定義し、最終的な特徴量𝑓′を 𝑓′ = 𝑝(α ⊗ ξ M)𝑊𝐺 ∊ ℝ 𝐸 と定義する。但し𝑊𝑠は次元を揃えるための線形変換であり、 ⊗は要素ごとの乗算である。 14
15.
特徴量獲得のまとめ 数式の多い説明になってしまったの で、ここで特徴量獲得の全体像をま とめておく。 ナレッジグラフとGlobal Semantic Pool からなるGlobal
reasoningと、画 像単位のAttentionを利用して、ベー スモデルのクラス分類出力𝑃から新 たな特徴量𝑓′が獲得される。 この獲得された𝑓′を元の特徴量𝑓と 合わせた特徴量[𝑓, 𝑓′]を最終的な検 出に用いる。 15
16.
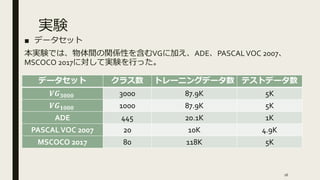
実験 ■ データセット 本実験では、物体間の関係性を含むVGに加え、ADE、PASCALVOC 2007、 MSCOCO
2017に対して実験を行った。 データセット クラス数 トレーニングデータ数 テストデータ数 𝑽𝑮 𝟑𝟎𝟎𝟎 3000 87.9K 5K 𝑽𝑮 𝟏𝟎𝟎𝟎 1000 87.9K 5K ADE 445 20.1K 1K PASCALVOC 2007 20 10K 4.9K MSCOCO 2017 80 118K 5K 16
17.
詳細 ■ ADE、PASCALVOC 2007、MSCOCO
2017に関しては物体間の関係性、属性 のデータが存在しないので、VGより得たナレッジグラフを用いた。 ■ ロバストなナレッジグラフを得るため、各クラス出現頻度上位200の関係 性及び属性のみを用いた。 ■ ベースモデルとしてFaster RCNN及びFaster RCNN with FPNを用いた。 ■ バックボーンはImageNet-PretrainedのResnet-101 ■ 特徴ベクトルは、ベースとなる特徴ベクトルが1024次元(D=1024)、新た な特徴ベクトルが256次元(E=256)とした。 17
18.
結果1(VG, ADE) 𝑉𝐺1000 、𝑉𝐺3000、ADEについての実験結果が左 図である。 •
Reasoning‐ RCNN 𝑅がFaster-RCNNベースの提 案手法。 • Reasoning‐ RCNNR W FPNがFaster-RCNN with FPNベースの提案手法の結果及びパラメータ 数である。 • ナレッジグラフは関係性ベースで作成。 • 両手法とも大きく性能が向上していることが 確認できる。 • また、よりパラメータ数の多いLight-head RCNNやCascade RCNNといったモデルに性能 で勝っている。 18
19.
結果2(PASCALVOC, MS COCO) 左の表はPASCAL
VOC及びMS COCOに対する結 果である。両データセットに対してはMask- RCNNベースのモデルも実験に用いている。 • またここでは、関係性ベースのナレッジグラ フを用いた Reasoning‐ RCNN 𝑅に加え、クラス 間の類似性ベースのナレッジグラフを用いた Reasoning‐ RCNNA を用いた実験も行っている。 • 前スライドで示したデータセットの時同様、 性能の向上が確認できた。 • 関係性ベースのナレッジグラフの方が類似性 ベースのナレッジグラフよりも大きな精度の 向上を実現できていることが確かめられた。 19
20.
結果3(出力結果) 左図は、Faster-RCNNと提案手法 であるReasoning-RCNNの検出結 果を比較したものである。 • Reasoning-RCNNの方が細かい 物体までより多くの数検出でき ていることが確認できる。 (キッチンの複数のキャビネッ ト、サイドミラーに映った男や 帽子、カメラ等) • 細かい物体等の単体では検出が 困難な物体でも、周囲の関係性 を利用することで検出を可能と している。 20
21.
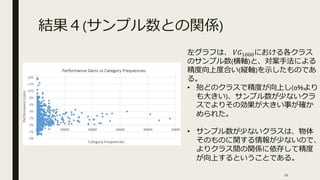
結果4(サンプル数との関係) 左グラフは、 𝑉𝐺1000における各クラス のサンプル数(横軸)と、対案手法による 精度向上度合い(縦軸)を示したものであ る。 • 殆どのクラスで精度が向上し(0%より も大きい)、サンプル数が少ないクラ スでよりその効果が大きい事が確か められた。 •
サンプル数が少ないクラスは、物体 そのものに関する情報が少ないので、 よりクラス間の関係に依存して精度 が向上するということである。 21
22.
結果5(Ablation studies) Ablation studyの結果が左の表である。 •
ナレッジグラフ ナレッジグラフを省いたとき(ξを単位行列と する)最も性能が低下し、本提案手法において 最も重要な要素であることが確かめられた。 • Global semantic pool Global semantic poolを省いたとき(𝑀を単位行 列とする)ときも一定の性能低下がみられ、特 に小さな物体に対するRecallがより大きく低下 した。 • Attention Attention αの機構を省いたときや、一様にし たとき(実質的な意味合いは同じ)もある程 度の性能低下がみられた。 22
23.
結論 ■ クラス間の関係性に目を向けることで、様々な物体検出データセットに 対して精度の向上を実現した。 ■ Global
Semantic PoolやAttentionによりロバスト性が向上 ■ 関係性のデータセットはVGのものしか存在しないが、他のデータセット に対しても有効であった(一般常識的なものが獲得できている?)。 ■ 提案するアーキテクチャの計算コストはあまり高くないので、パラメー タ数や推論時間がベースモデルからあまり増加しないのも高評価。 ■ Future workとしては、クラス間の関係性をセグメンテーション等他のタ スクにも応用することが挙げられる。 23
24.
個人的な感想1 ■ 発想自体は自然 もっと主流になるべきだと思う ■ それに対して、モデルアーキテクチャは工夫されていると感じた。 Global
Semantic Pool辺りは自分では絶対思いつかないと思う ■ Visual Genomeは偉大 関係性を与えてくれる上、クラス数も豊富 やはりデータセットが無いとこの分野の研究は始まらない 24
25.
個人的な感想2 ■ 任意の物体検出器に応用できるのは強い、任意のナレッジグラフを 適応できる(関係性、類似性以外でも可能) ■ もう少し行って欲しい実験がある –
任意の物体検出器に応用できるとは書いてあるが、Faster-RCNN 系列をベースにした実験しか無い。 – せっかくクラス間の関係性ベースと類似性ベースの両ナレッジ グラフを提案したのだから、比較だけでなく併用した実験も 行って欲しい。 併用自体は独立に生成したそれぞれの特徴量と、ベースの特徴 量を合わせればいいだけなので、自然な拡張で行える。 25
Download
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Takumi Ohkuma, Nakayama Lab M1
Reasoning-RCNN: Unifying Adaptive Global
Reasoning into Large-scale Object Detection](https://image.slidesharecdn.com/20190726-200128191017/85/Reasoning-RCNN-Unifying-Adaptive-Global-Reasoning-into-Large-scale-Object-Detection-1-320.jpg)
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Takumi Ohkuma, Nakayama Lab M1
Reasoning-RCNN: Unifying Adaptive Global
Reasoning into Large-scale Object Detection](https://image.slidesharecdn.com/20190726-200128191017/75/Reasoning-RCNN-Unifying-Adaptive-Global-Reasoning-into-Large-scale-Object-Detection-1-2048.jpg)


![概要
■ クラス間の関係性を用いて、多
クラスの物体検出の精度を高め
る
■ 物体間の関係性にはナレッジグ
ラフを用い、その関係性はVisual
Genome(VG)[1]より取得
■ 任意の物体検出器に応用するこ
とが可能
[1] R. Krishna, et.al. “visual genome: Connecting language and vision
using crowdsourced dense image annotations” 2016. 4](https://image.slidesharecdn.com/20190726-200128191017/85/Reasoning-RCNN-Unifying-Adaptive-Global-Reasoning-into-Large-scale-Object-Detection-4-320.jpg)








![特徴量獲得のまとめ
数式の多い説明になってしまったの
で、ここで特徴量獲得の全体像をま
とめておく。
ナレッジグラフとGlobal Semantic
Pool からなるGlobal reasoningと、画
像単位のAttentionを利用して、ベー
スモデルのクラス分類出力𝑃から新
たな特徴量𝑓′が獲得される。
この獲得された𝑓′を元の特徴量𝑓と
合わせた特徴量[𝑓, 𝑓′]を最終的な検
出に用いる。
15](https://image.slidesharecdn.com/20190726-200128191017/85/Reasoning-RCNN-Unifying-Adaptive-Global-Reasoning-into-Large-scale-Object-Detection-15-320.jpg)



































![[DL輪読会]Differentiable Mapping Networks: Learning Structured Map Representatio...](https://cdn.slidesharecdn.com/ss_thumbnails/differentiablemappingnetworks-200707033539-thumbnail.jpg?width=640&height=640&fit=bounds)










