Download as PDF, PPTX








![© 2018 Bloomberg Finance L.P. All rights reserved.
Python UDFs
• Native Python code
• Function objects are pickled and passed to workers
• Row data passed to Python workers one at a time
• Code will pass from Python runtime-> JVM runtime -> Python runtime and back
• [SPARK-22216] [SPARK-21187] – support vectorized UDF support with Arrow format –
see Li Jin’s talk](https://image.slidesharecdn.com/7estherkundin-180611220022/75/Integrating-Existing-C-Libraries-into-PySpark-with-Esther-Kundin-9-2048.jpg)

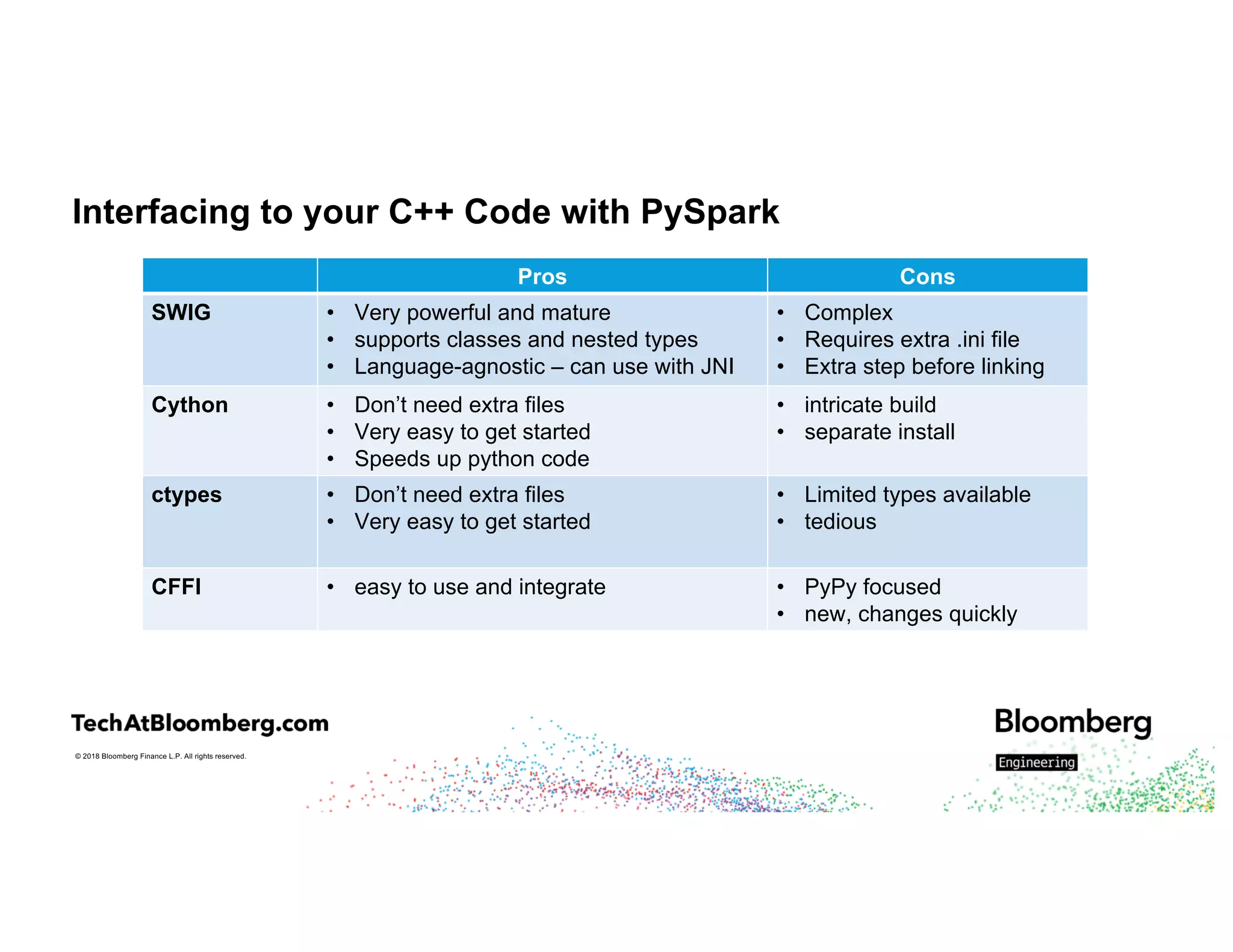



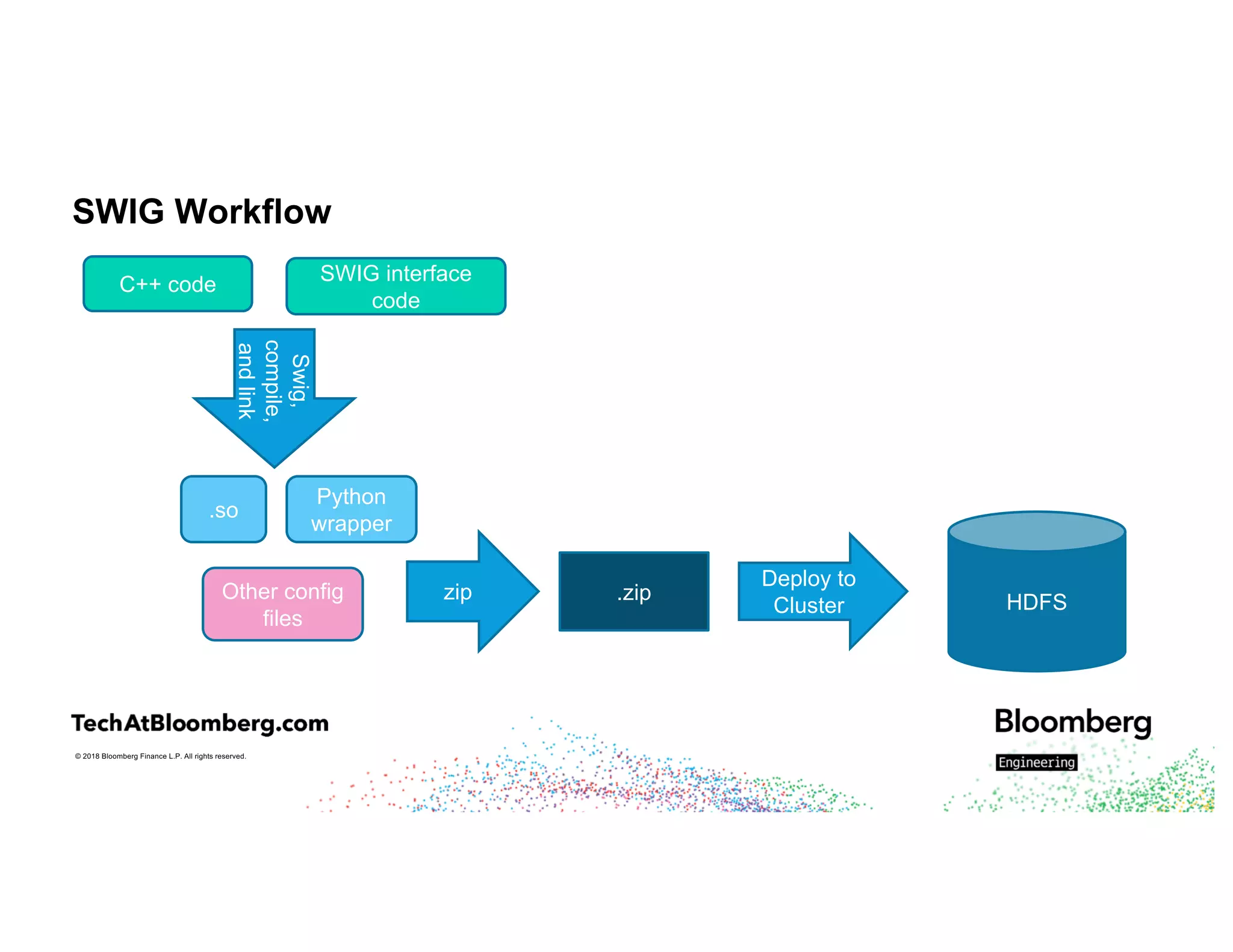





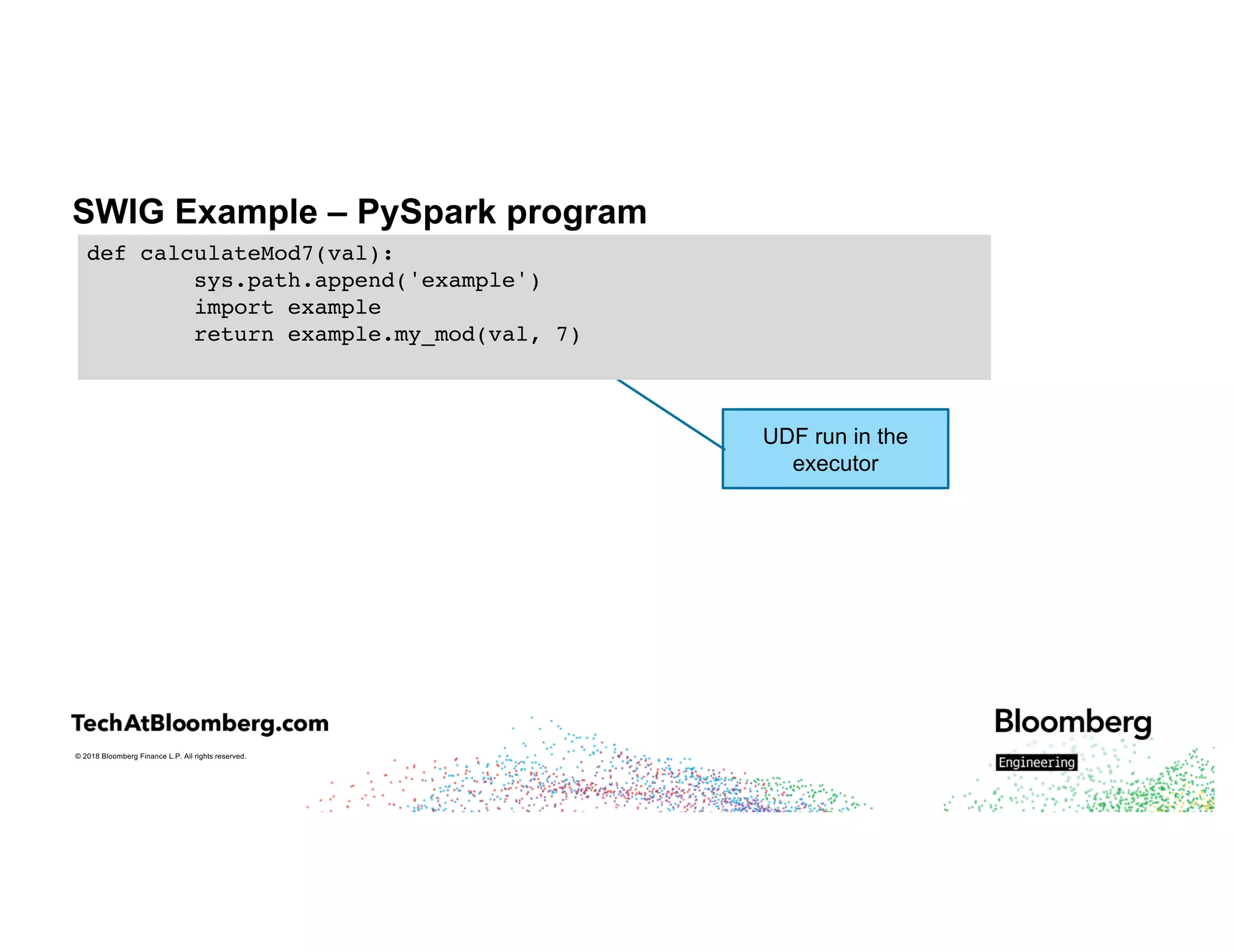
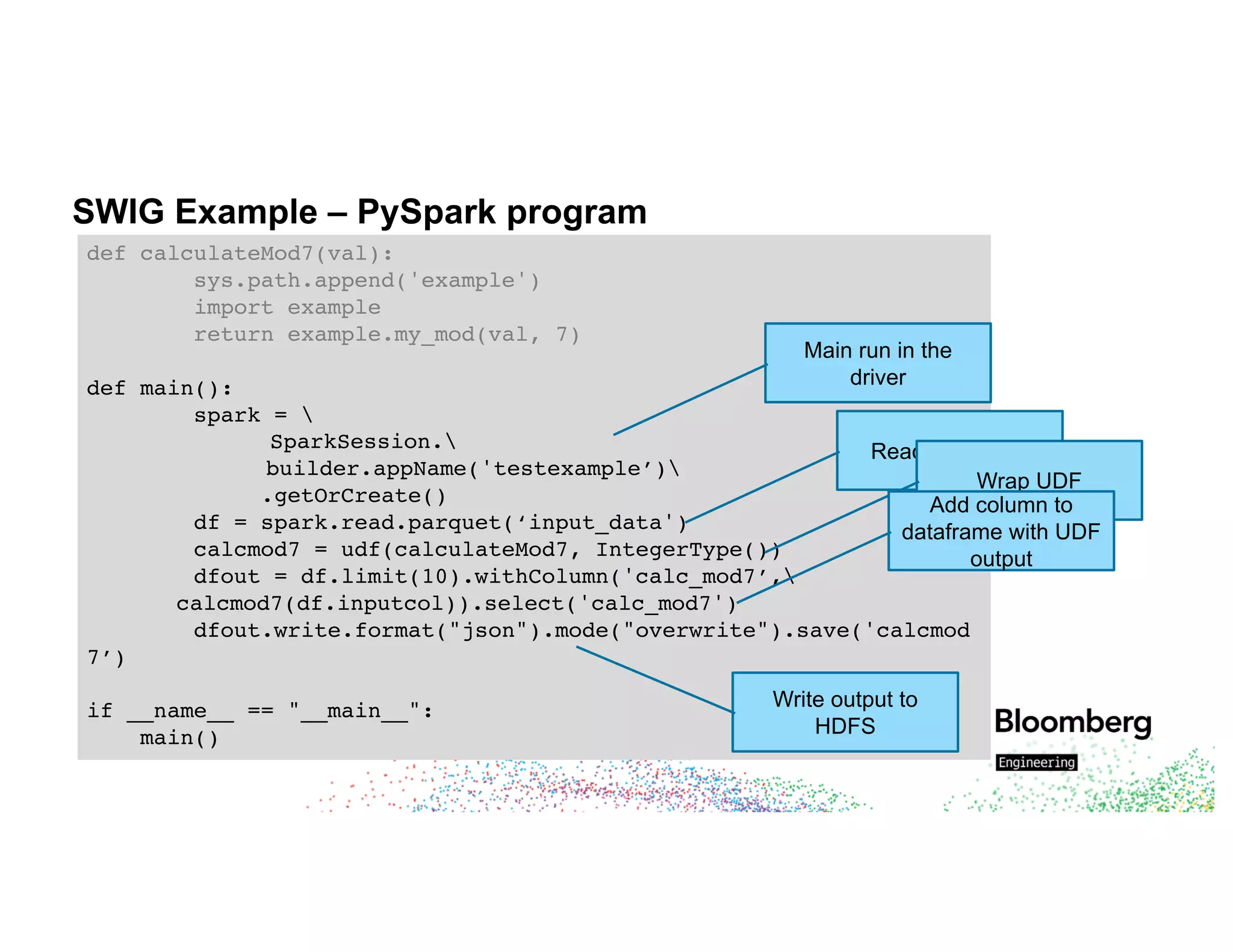












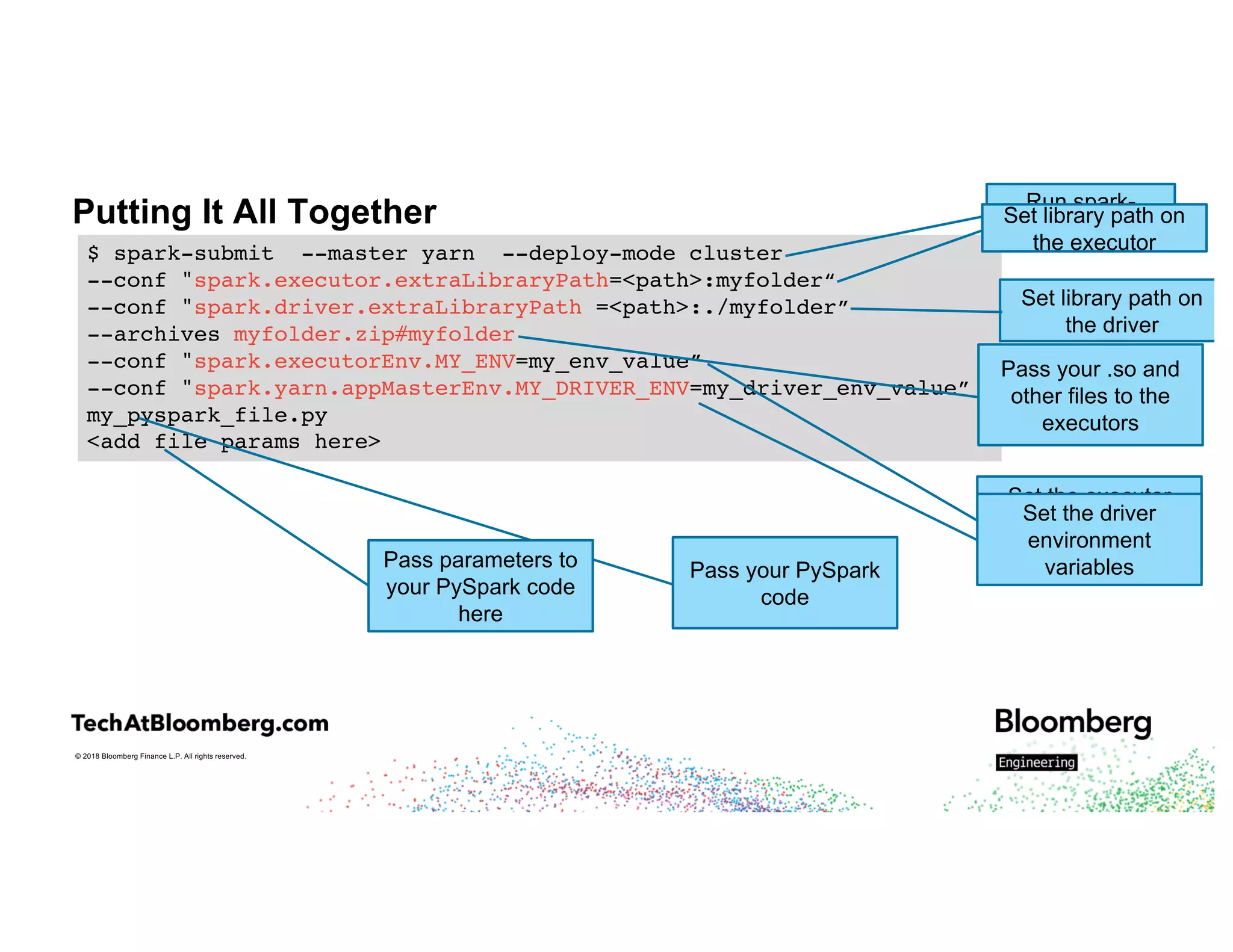

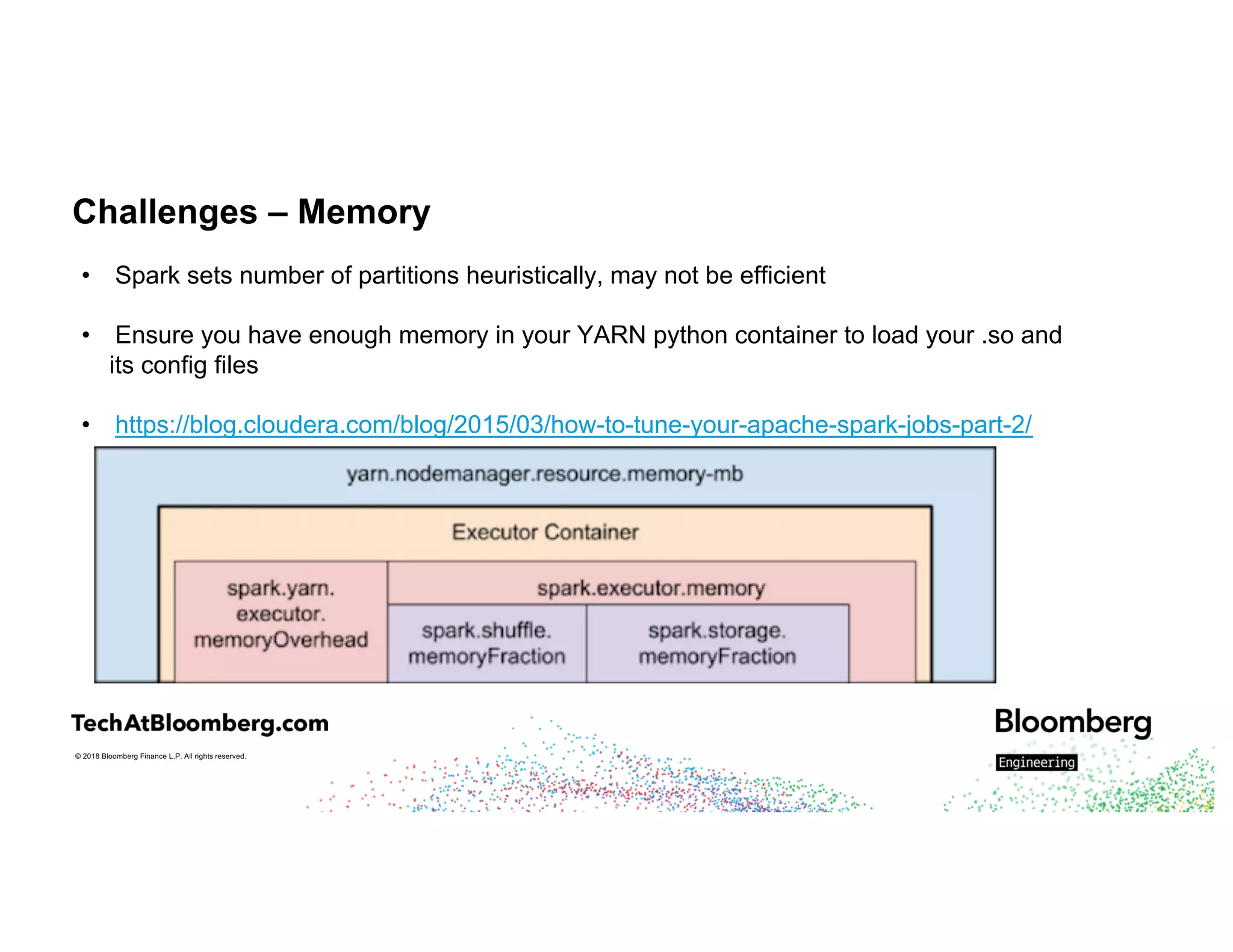


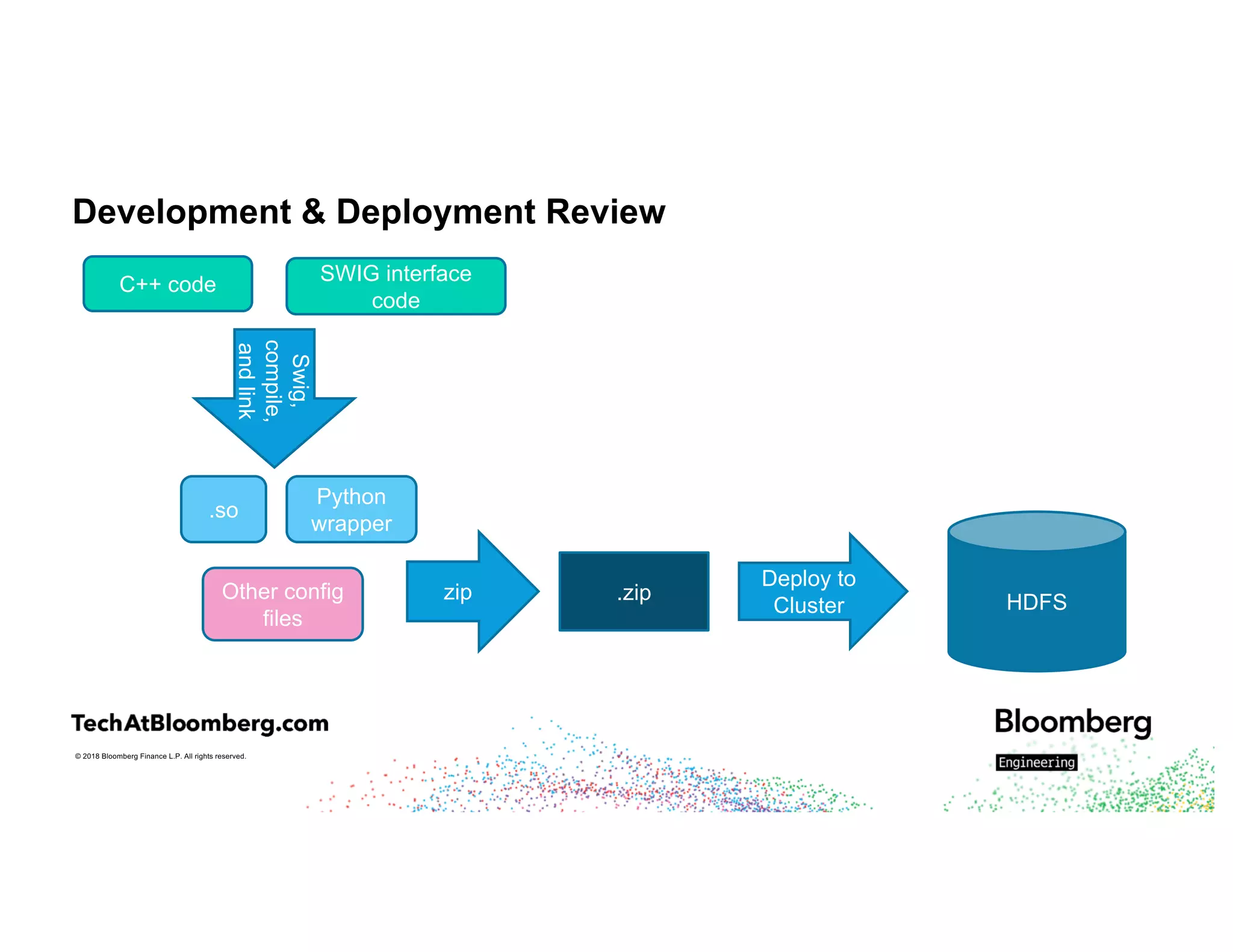





The document discusses integrating existing C++ libraries into PySpark for real-time sentiment analysis of news stories, emphasizing the importance of efficiency and quick response times. It outlines the process of interfacing C++ with PySpark, the use of different wrappers (like SWIG and ctypes), challenges faced during execution, and strategies for effective resource management. Key takeaways include the ability to run historical data backfills using C++ code in Spark and the need for careful deployment and configuration to ensure smooth operations.








![[Outdated] Secrets of Performance Tuning Java on Kubernetes](https://cdn.slidesharecdn.com/ss_thumbnails/jvmoncontainersjuly2022-220718124816-cca24690-thumbnail.jpg?width=640&height=640&fit=bounds)





























































![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)