Download as PDF, PPTX









![A short example
import pandas as pd
df = pd.read_csv("my_data.csv")
df.columns = ['x', 'y', 'z1']
df['x2'] = df.x * df.x
PySparkpandas
df = (spark.read
.option("inferSchema", "true")
.csv("my_data.csv"))
df = df.toDF('x', 'y', 'z1')
df = df.withColumn('x2', df.x * df.x)](https://image.slidesharecdn.com/678niallturbitt-200709204238/85/Koalas-Pandas-on-Apache-Spark-9-320.jpg)

![A short example
import pandas as pd
df = pd.read_csv("my_data.csv")
df.columns = ['x', 'y', 'z1']
df['x2'] = df.x * df.x
pandas
import databricks.koalas as ks
df = ks.read_csv("my_data.csv")
df.columns = ['x', 'y', 'z1']
df['x2'] = df.x * df.x
Koalas](https://image.slidesharecdn.com/678niallturbitt-200709204238/85/Koalas-Pandas-on-Apache-Spark-12-320.jpg)


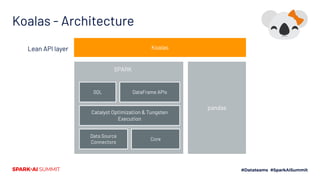

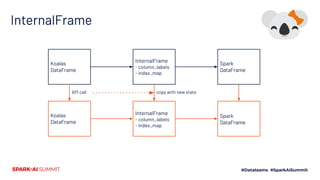
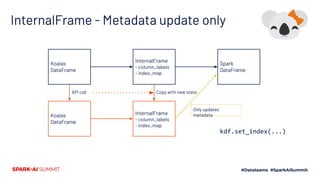
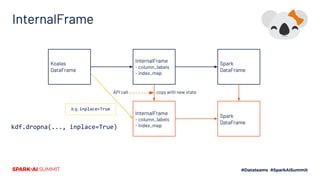

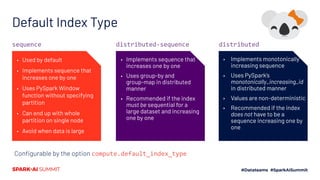







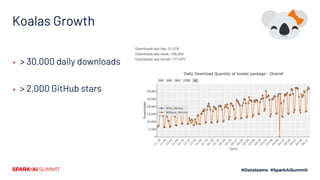
The document outlines Koalas, a library that aims to provide a pandas-like API on top of Apache Spark, facilitating a seamless transition from small to large data analysis. It details the growth and current status of Koalas, including community involvement, feature implementation, and comparisons between Spark and pandas. Additionally, it highlights the architecture of Koalas and provides information on its roadmap and installation options.















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)







