Download to read offline









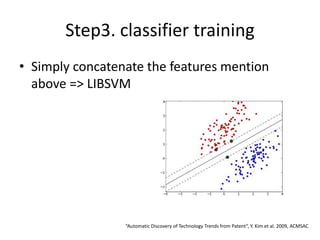














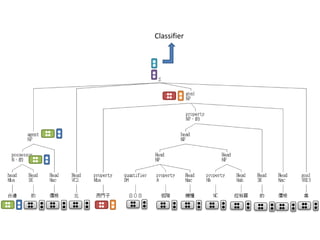



The document discusses techniques for extracting information from Chinese language documents, including named entity recognition and relation extraction. It describes using conditional random fields to recognize named entities and recursive neural networks to identify relationships between entities by representing words as vectors and modeling the context using matrices. Future work could involve extracting information across multiple sentences, documents, and languages.



































