Downloaded 34 times






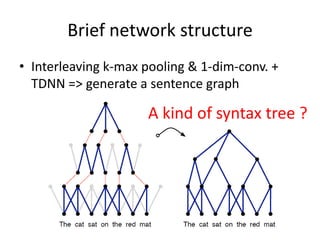
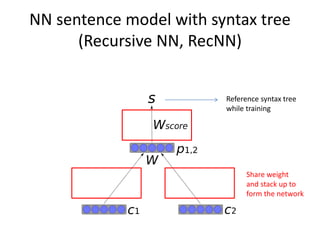

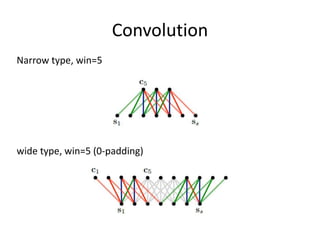
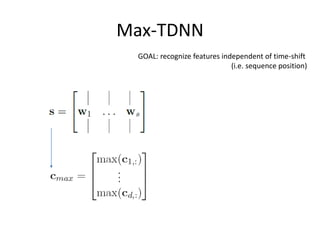
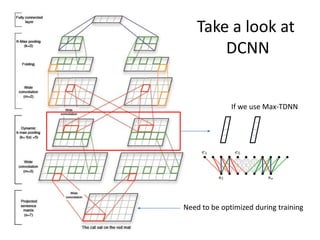




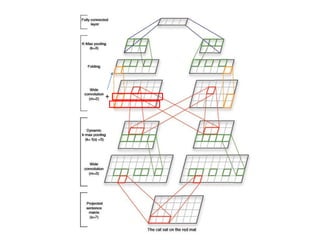

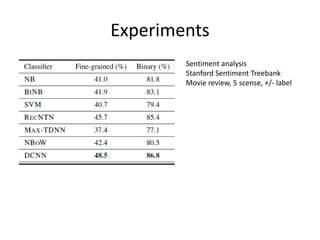
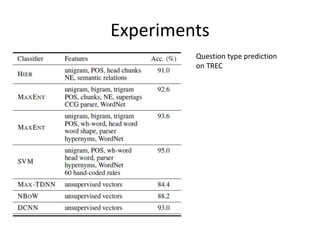
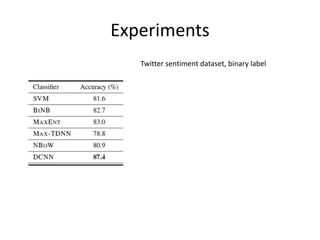
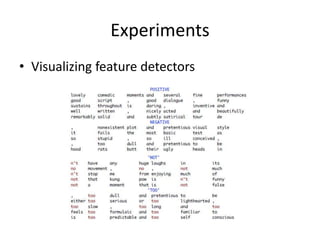




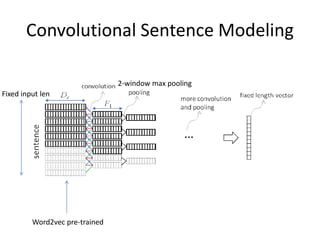

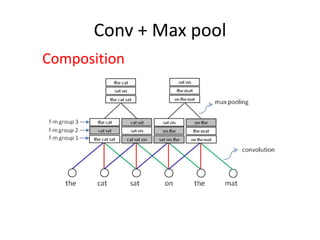
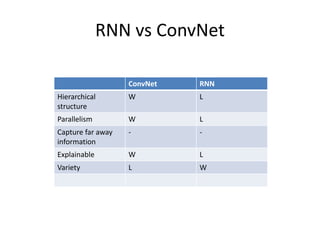
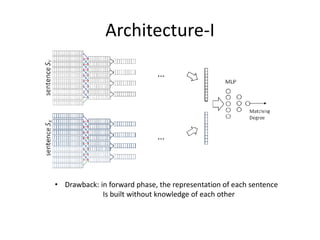
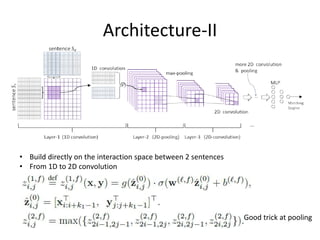
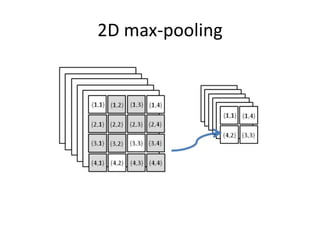

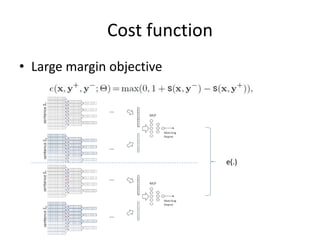
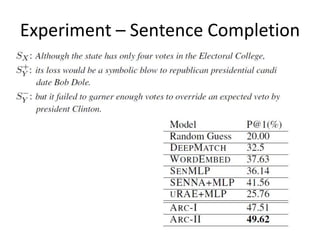
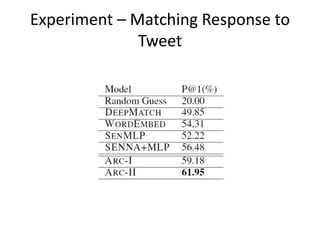
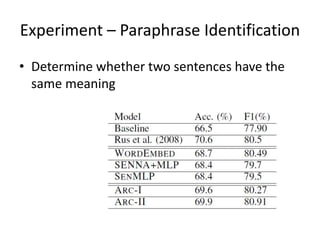



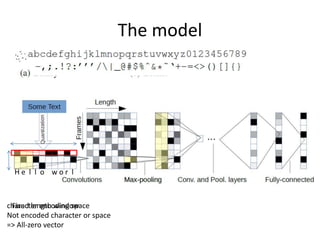
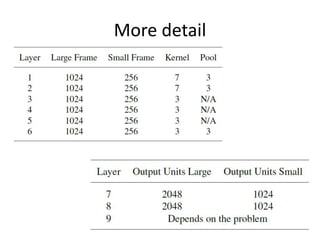



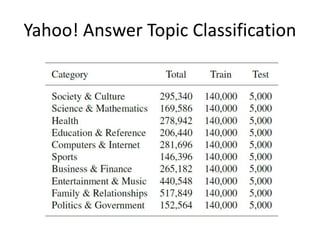
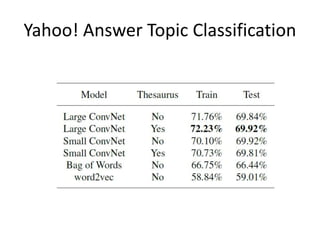
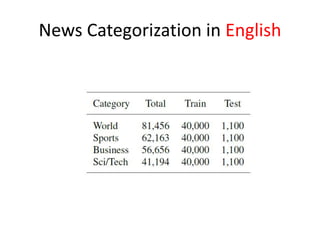
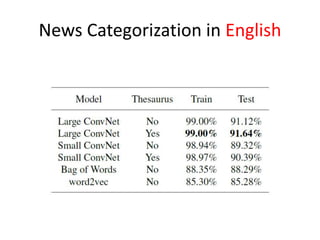



This document summarizes two papers on using convolutional neural networks (CNNs) for modeling sentences and text. The first paper proposes a CNN model called DCNN that uses convolutions, max-TDNN, and dynamic k-max pooling to model sentences without relying on syntactic structures. The second paper proposes a hierarchical CNN model that uses 2D convolutions to capture matching patterns between sentences for tasks like sentence completion and response matching. Both papers demonstrate their models can achieve good performance on tasks like sentiment analysis, question classification, and paraphrase identification.



































![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)













































